Use Python To Index Files Into Elasticsearch - Index All Files in a Directory (Part 2)
Introduction
Part one of this series demonstrated how you can use Python to crawl for files in a directory, and then use the os library’s open() method to open the files and return their content as string data.
This article will show you how to use the helpers module, in the low-level Python client, to index the data from the files into Elasticsearch. The example code in this article will also show you how to put the name and meta data from the file into Elasticsearch fields for the documents as well.
Now let’s jump into Part 2 of how to use Python to index files into Elasticsearch, specifically indexing all files in a directory.
Prerequisites
Python 2 is now deprecated and losing support, and the code in this article has only been tested with Python 3, so it’s recommended that you use Python 3.4 or newer when executing this code. Use the following commands to check if Python 3, and its PIP package manager, are installed:
1 2 | python3 -V pip3 -V |
You can use the PIP3 package manager to install the elasticsearch low-level Python client with the following command:
1 | pip3 install elasticsearch |
You can use the following cURL request to check if the Elasticsearch cluster is running on yourlocalhost server:
1 | curl -XGET localhost:9200 |
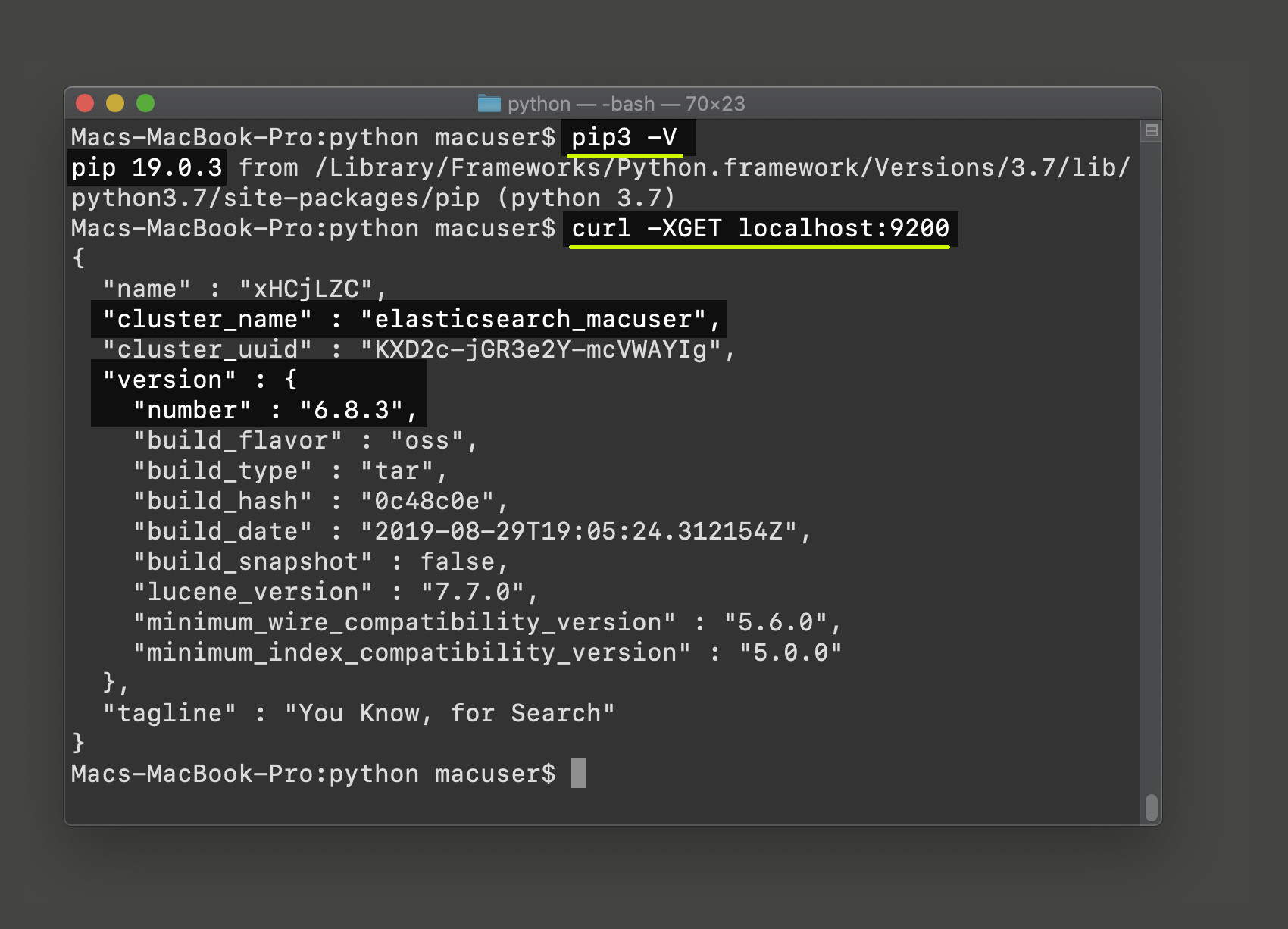
NOTE: The default port for Elasticsearch is 9200, but you can change this in your installation’s elasticsearch.yml file.
Make sure to import the helpers library for the Elasticsearch client. The following Python code demonstrates how to do this:
1 2 | # use the elasticsearch client's helpers class for _bulk API from elasticsearch import Elasticsearch, helpers |
Iterate all of the file names returned by Python
The last article for this series demonstrated how to get all of the files in a directory (with a relative path to the Python script) using the following function:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | # function that returns the full path for the script's current directory ($PWD) def current_path(): return os.path.dirname(os.path.realpath( __file__ )) # default path is the script's current dir def get_files_in_dir(self=current_path()): # declare empty list for files file_list = [] # put a slash in dir name if needed if self[-1] != slash: self = self + slash # iterate the files in dir using glob for filename in glob.glob(self + '*.*'): # add each file to the list file_list += [filename] # return the list of filenames return file_list |
NOTE: The default parameter for the function’s directory uses the current_path() function above to get the script’s current working directory if nothing is passed to it.
Here’s how you can pass a directory name to the function call to have it return all of the file names:
1 2 3 4 5 | # pass a directory (relative path) to function call all_files = get_files_in_dir("test-folder") # total number of files to index print ("TOTAL FILES:", len( all_files )) |
Define a function that yields Elasticsearch documents from the files
The following function will yield Elasticsearch documents when it’s passed to the Elasticsearch client’s helpers.bulk() method call. At the beginning of the function you need to use an iterator, like enumerate(), to iterate over the list of file names:
1 2 3 4 5 | # define a function that yields an Elasticsearch document from file data def yield_docs(all_files): # iterate over the list of files for _id, _file in enumerate(all_files): |
The code in this article uses the _id integer counter, returned by the enuerate() function iterator, for the documents’ IDs.
Get the file’s name and meta data for the Elasticsearch document fields
This next section of code inside of the function will parse the file’s data, within each iteration, to get the create and modify timestamps for the file using the os.stat() method call:
1 2 3 4 5 6 7 8 9 | # use 'rfind()' to get last occurence of slash file_name = _file[ _file.rfind(slash)+1:] # get the file's statistics stats = os.stat( _file ) # timestamps for the file create_time = datetime.fromtimestamp( stats.st_birthtime ) modify_time = datetime.fromtimestamp( stats.st_mtime ) |
Get the file’s data for the Elasticsearch document _source data
The following code nests another function call (get_data_from_text_file()) to get each file iterations respective list of string data:
1 2 3 4 5 | # get the data inside the file data = get_data_from_text_file( _file ) # join the list of data into one string using return data = "".join( data ) |
The join() function will put the list of strings together into one, longer string.
Defining the Python function that uses ‘open()’ to get the file’s data
Here’s the code for the get_data_from_text_file() function from part 1 of this series:
1 2 3 4 5 6 7 8 9 10 11 12 13 | def get_data_from_text_file(file): # declare an empty list for the data data = [] # get the data line-by-line using os.open() for line in open(file, encoding="utf8", errors='ignore'): # append each line of data to the list data += [ str(line) ] # return the list of data return data |
If goes through the file, line-by-line, to get all of the string data and puts them in a list, and then returns the list object after the iteration is complete.
Assemble the Elasticsearch document’s ‘_source’ data using a Python dictionary
Python’s dict object type is a key-value data type that can map an Elasticsearch JSON document perfectly. Here’s some code that will take a file’s meta data and put it into a Python dictionary that can later be used for the Elasticsearch document’s _source field data:
1 2 3 4 5 6 7 | # create the _source data for the Elasticsearch doc doc_source = { "file_name": file_name, "create_time": create_time, "modify_time": modify_time, "data": data } |
Use a Python ‘yield’ generator to put the Elasticsearch document together
Here’s some code that passes the doc_source object to the "_source" field in a yield{} generator for each Elasticsearch document being indexed:
1 2 3 4 5 6 7 | # use a yield generator so that the doc data isn't loaded into memory yield { "_index": "my_files", "_type": "some_type", "_id": _id + 1, # number _id for each iteration "_source": doc_source } |
NOTE The _id field is optional, because Elasticsearch will dynamically create an alpha-numeric ID for the document if your code doesn’t explicitly provide one. The parameter for the _id field will register the ID as a string, regardless of whether an integer, float, or string is passed to it.
Pass the file data to the Elasticsearch helpers library’s bulk() method call
The last step is to pass the yield_docs() function defined above to the client’s helpers.bulk() API method call. The following code passes the client object instance and the entire function call to the bulk() method:
1 2 3 4 5 6 7 8 9 10 | try: # make the bulk call using 'actions' and get a response resp = helpers.bulk( client, yield_docs( all_files ) ) print ("\nhelpers.bulk() RESPONSE:", resp) print ("RESPONSE TYPE:", type(resp)) except Exception as err: print("\nhelpers.bulk() ERROR:", err) |
It should return a tuple response object if the API call was successful.
Caveat about indexing images to Elasticsearch
It’s not recommended that you attempt to index image files using the code in this article. Check out the article we wrote on uploading images to an Elasticsearch index for more information on how to do that.
Conclusion
Run the Python script using the python3 command. You should get a response that resembles the following:
1 2 3 4 | TOTAL FILES: 5 helpers.bulk() RESPONSE: (5, []) RESPONSE TYPE: <class 'tuple'> |
Use Kibana to verify that the files were indexed using Python
If you have Kibana installed and running on your Elasticsearch cluster you can the Kibana Console UI (found in the Dev Tools section) to make the following HTTP request to verify that the files were uploaded and indexed to the cluster:
1 2 3 4 5 6 | GET my_files/_search { "query": { "match_all": {} } } |
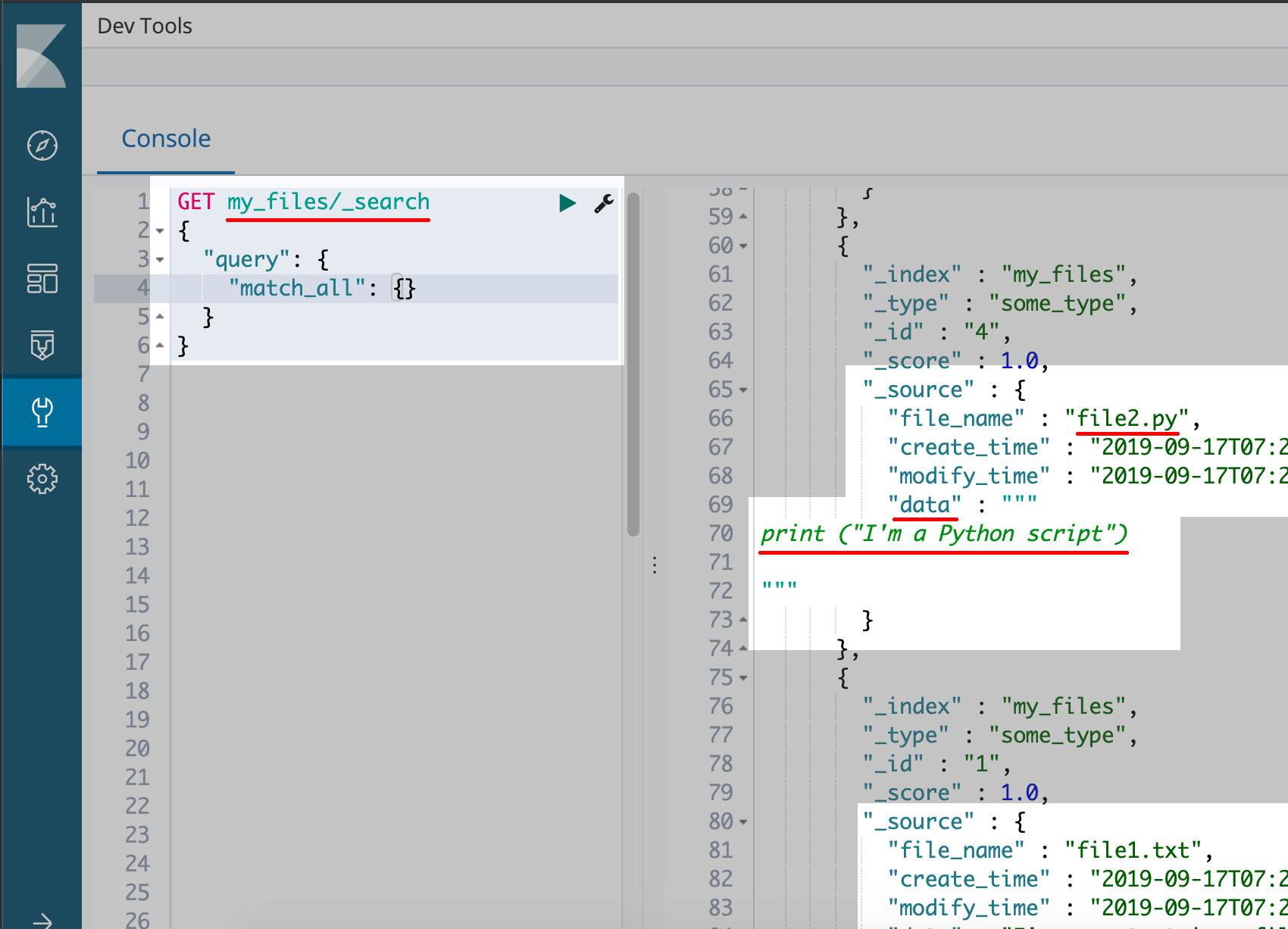
This concludes the series explaining how you can use Python’s built-in libraries to grep for files in a directory in order to index their data into Elasticsearch as document data. The complete code from both of the articles can be found below.
Just the Code
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 | #!/usr/bin/env python3 #-*- coding: utf-8 -*- # import Datetime for the document's timestamp from datetime import datetime # import glob and os import os, glob # use the elasticsearch client's helpers class for _bulk API from elasticsearch import Elasticsearch, helpers # declare a client instance of the Python Elasticsearch library client = Elasticsearch("http://localhost:9200") # posix uses "/", and Windows uses "" if os.name == 'posix': slash = "/" # for Linux and macOS else: slash = chr(92) # '\' for Windows def current_path(): return os.path.dirname(os.path.realpath( __file__ )) # default path is the script's current dir def get_files_in_dir(self=current_path()): # declare empty list for files file_list = [] # put a slash in dir name if needed if self[-1] != slash: self = self + slash # iterate the files in dir using glob for filename in glob.glob(self + '*.*'): # add each file to the list file_list += [filename] # return the list of filenames return file_list def get_data_from_text_file(file): # declare an empty list for the data data = [] # get the data line-by-line using os.open() for line in open(file, encoding="utf8", errors='ignore'): # append each line of data to the list data += [ str(line) ] # return the list of data return data # pass a directory (relative path) to function call all_files = get_files_in_dir("test-folder") # total number of files to index print ("TOTAL FILES:", len( all_files )) """ PART 2 STARTS HERE """ # define a function that yields an Elasticsearch document from file data def yield_docs(all_files): # iterate over the list of files for _id, _file in enumerate(all_files): # use 'rfind()' to get last occurence of slash file_name = _file[ _file.rfind(slash)+1:] # get the file's statistics stats = os.stat( _file ) # timestamps for the file create_time = datetime.fromtimestamp( stats.st_birthtime ) modify_time = datetime.fromtimestamp( stats.st_mtime ) # get the data inside the file data = get_data_from_text_file( _file ) # join the list of data into one string using return data = "".join( data ) # create the _source data for the Elasticsearch doc doc_source = { "file_name": file_name, "create_time": create_time, "modify_time": modify_time, "data": data } # use a yield generator so that the doc data isn't loaded into memory yield { "_index": "my_files", "_type": "some_type", "_id": _id + 1, # number _id for each iteration "_source": doc_source } try: # make the bulk call using 'actions' and get a response resp = helpers.bulk( client, yield_docs( all_files ) ) print ("\nhelpers.bulk() RESPONSE:", resp) print ("RESPONSE TYPE:", type(resp)) except Exception as err: print("\nhelpers.bulk() ERROR:", err) |


Pilot the ObjectRocket Platform Free!
Try Fully-Managed CockroachDB, Elasticsearch, MongoDB, PostgreSQL (Beta) or Redis.
Get Started