Build an Elasticsearch Web Application in Python (Part 2)
Introduction to Elasticsearch web applications in Python
This article is part two of an article series that will show you how to build a Python web application designed to return Elasticsearch information. The first part of the series demonstrated how to create the web server using the Bottle framework. It also provided some example code that connected to Elasticsearch (using the Python low-level client) in order to return its cluster information.
This next part will show you how you can return all of the cluster’s indices (and their respective document data) to the front end of a website using the Bottle framework in Python.
Create an HTML file for the Elasticsearch document data
This article will use Python’s built-in codecs library to open the HTML file and retrieve its data for first part of the web page that will display the Elasticsearch document data.
Open a terminal window and use the code command for VB Code, subl for the Sublime editor, or a terminal-based text editor (like vim, nano, or gedit) to open or create an HTML file:
1 | code index.html |
Put the meta and header tags into the HTML file
Put the following code into the file to begin the HTML for the tables for the Elasticsearch document data:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 | <!DOCTYPE html> <html lang="en"> <head> <meta name="viewport" content="width=device-width, initial-scale=1, shrink-to-fit=no"> <meta charset="UTF-8"> <!-- bootstrap 4 href --> <link rel="stylesheet" href="https://stackpath.bootstrapcdn.com/bootstrap/4.3.1/css/bootstrap.min.css" integrity="sha384-ggOyR0iXCbMQv3Xipma34MD+dH/1fQ784/j6cY/iJTQUOhcWr7x9JvoRxT2MZw1T" crossorigin="anonymous"> <style> h3 { padding: 0.5rem; } .table-responsive { font-family: 'Trebuchet MS', 'Lucida Sans Unicode', 'Lucida Grande', 'Lucida Sans', Arial, sans-serif, Helvetica, sans-serif; border-collapse: collapse; padding: 0.5rem; } .table-responsive td, .table-responsive th { border: 0.2rem solid #27282a; padding: 0.5rem; } .table-responsive tr:nth-child(even) { background-color: #8a8c84; } .table-responsive td:hover { background-color:#5b5c5e; color: #b9b9b9; } .table-responsive th { padding: 1rem; text-align: center; background-color: #71747d; color: #ffffff; } </style> </head> <body> <div style="margin-left:0rem" class="container"> <h1>ObjectRocket Tutorials</h1> <h2>Elasticsearch Indices</h2> </div> |
NOTE: The Bootstrap stylesheet link and the CSS within the <style> tag are optional, and just help to “prettify” the table data. The <meta charset="UTF-8"> meta tag is necessary if you’d like to display Elasticsearch data that includes Unicode characters outside of the 128-character ASCII range.
Create a Python script for the Elasticsearch web application
Create a Python script (e.g. elastic_app.py) that will query Elasticsearch documents, and run the Bottle server as well.
Import the Elasticsearch and Bottle libraries for Python
Like in part one of this series, you’ll first have to import the necessary Python libraries for the Python web server to return Elasticsearch documents:
1 2 3 4 5 6 7 8 9 10 11 | # import the run and get methods from the bottle library from bottle import run, get # import the elasticsearch client library from elasticsearch import Elasticsearch # import Python's json library to format JSON responses import json # use codecs to open the existing HTML file import codecs |
In order to avoid an ImportError, you’ll have to make sure that you’ve installed the elasticsearch and bottle libraries, using the PIP package manager for Python, by executing the pip install (for Python 2.7), or pip3 install (for Python 3) commands in a terminal or command prompt window to install them.
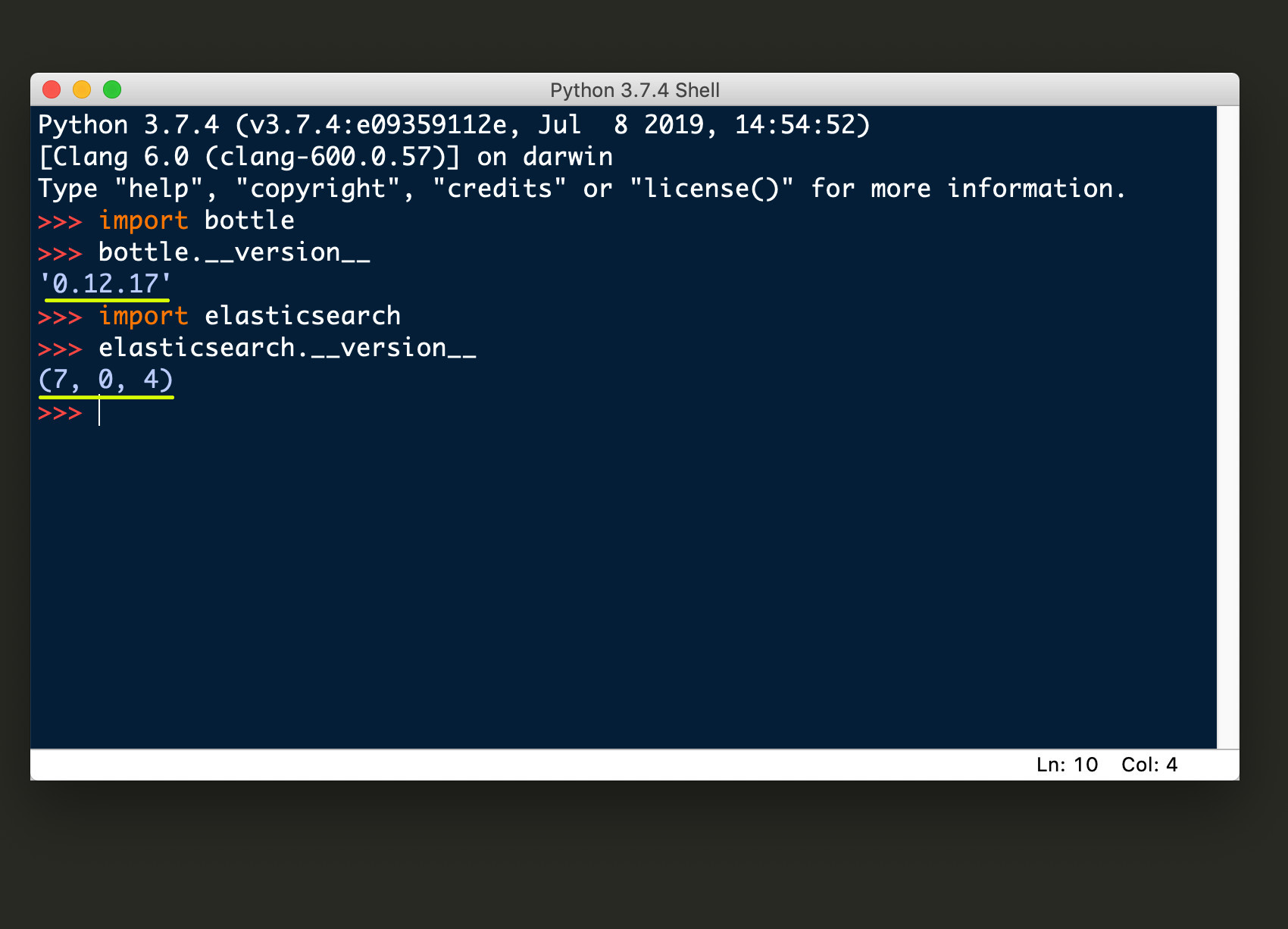
Version 0.13 (and greater) of the Bottle framework no longer supports Python versions that are 2.6 or older, and it should be noted that the code in this article has only been tested on Python 3. Access the Bottle and Elasticsearch libraries’ __version__ attribute if you’re unsure which versions are installed.
Create globals for the Elasticsearch and Bottle servers
The code in this article passes globals to the libraries’ method calls. The following code will set the Bottle server’s port to 1234, but you can set it to whatever you want:
1 2 3 4 5 | # globals for the Elasticsearch domain # ResourceWarning: unclosed <socket.socket> error if HTTP in domain DOMAIN = "localhost" ELASTIC_PORT = 9200 BOTTLE_PORT = 1234 |
NOTE: The default port for Elasticsearch is 9200, but this can be configured in your Elasticsearch installation’s elasticsearch.yml file, and it will take affect after you restart the service.
connect to Elasticsearch
Use the following code to attempt to connect to your server’s Elasticsearch cluster:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | try: # concatenate a string for the Elasticsearch connection domain_str = DOMAIN + ":" + str(ELASTIC_PORT) # declare a client instance of the Python Elasticsearch library client = Elasticsearch( domain_str ) # info() method raises error if domain or conn is invalid print (json.dumps( Elasticsearch.info(client), indent=4 ), "\n") except Exception as err: print ("Elasticsearch() ERROR:", err, "\n") # client is set to none if connection is invalid client = None |
It will set the client library instance to None in the case of an exception, or if the cluster is not running.
Return Elasticsearch documents from every index stored on the cluster
The following code defines a Python function that will get all of the cluster’s indices, and their respective _mapping fields and document data, and it will return the data in a nested Python dictionary object called all_docs:
1 2 3 | def get_elasticsearch_data(client, query={}, page=0): # create a dict for the Elasticsearch docs all_docs = {} |
Get all of the Elasticsearch cluster’s index names
This part of the function will check if the client object instance is valid, and, if that’s the case, it will pass the * wildcard to the indices.get_alias() method call to get all of the index names in a list:
1 2 3 4 5 | # make API call if client is not None if client != None: # returns a list of all the cluster's indices all_indices = client.indices.get_alias("*") |
Iterate over the Elasticsearch index names
Now we can iterate over the index names using a for loop to get the _mapping schema fields and document data for all of the user-created indices that are not system indices (indices starting with a period, like .kibana):
1 2 3 4 5 6 7 8 9 10 11 | # iterate over the index names for ind in all_indices: # skip hidden indices with '.' in name if "." not in ind[:1]: # nest another dictionary for index inside all_docs[ ind ] = {} # print the index name print ( "\nindex:", ind ) |
Get the Elasticsearch documents for each index
Pass the index name object (ind) to the Elasticsearch client’s search() method to have it return some documents:
1 2 3 4 5 6 7 8 9 10 11 | # get 10 of the Elasticsearch documents from index docs = client.search( from_ = page, # for pagination index = ind, body = { 'size' : 10, 'query': { # pass query paramater 'match_all' : query } }) |
NOTE: Since indices may have thousands of documents, the above code will return only 10 documents (using the 'size' parameter) so that the server, user, and web page won’t be overwhelmed with documents. You can modify the code in this article to support pagination by passing an integer value to the from_ parameter, otherwise it will always only return the index’s first 10 documents.
Put the Elasticsearch documents into the Python dictionary
Access the ["hits"]["hits"] nested value to get the document data. The following code will take this document data and put it into another dictionary (nested inside of all_docs) under the "docs" key:
1 2 3 4 5 6 7 8 | # get just the doc "hits" docs = docs["hits"]["hits"] # print the list of docs print ("index:", ind, "has", len(docs), "num of docs.") # put the list of docs into a dict key all_docs[ ind ]["docs"] = docs |
Get the Elasticsearch _mapping schema for the indices
The last step is to pass the index name to the client’s indices.get_mapping() method to have it return the nested mapping schema. Use the following code to have the function put this data into the dictionary under the "fields" key:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | try: # returns dict object of the index _mapping schema raw_data = client.indices.get_mapping( ind ) print ("get_mapping() response type:", type(raw_data)) # returns dict_keys() obj in Python 3 mapping_keys = raw_data[ ind ]["mappings"].keys() print ("\n_mapping keys():", mapping_keys) # get the index's doc type doc_type = list(mapping_keys)[0] print ("doc_type:", doc_type) # get the schema by accessing index's _doc type schema = raw_data[ ind ]["mappings"][ doc_type ]["properties"] print (json.dumps(schema, indent=4)) print ("\n# of fields in _mapping:", len(schema)) print ("all fields:", list(schema.keys()) ) all_docs[ ind ]["fields"] = schema all_docs[ ind ]["doc_type"] = doc_type except Exception as err: print ("client.indices error:", err) all_docs[ ind ]["fields"] = {} all_docs[ ind ]["doc_type"] = doc_type |
NOTE: As you can see from the above code, the "fields" and "doc_type" keys will just have an empty dictionary assigned to them in the case of an exception.
Now all we have to do is return the all_docs nested dictionary object after the iteration is complete:
1 2 | # return all of the doc dict return all_docs |
Convert Elasticsearch document data into an HTML string
This next function, called html_elasticsearch(), will parse all of the Elasticsearch data returned by the above get_elasticsearch_data() function and concatenate an HTML string in the form of a table.
Create a function that will create an HTML string from the Elasticsearch data
The first step is to declare the function, and to use the codec library’s open() method to access the HTML file that we created earlier:
1 2 3 4 5 | # gef a function that will return HTML string for frontend def html_elasticsearch(): html_file = codecs.open("index.html", 'r') html = html_file.read() |
Call the get_elasticsearch_data() function to get the Elasticsearch data
Now pass the client object instance to the get_elasticsearch_data() function that we created earlier to get the cluster’s data:
1 2 3 4 5 6 7 | # get all of the Elasticsearch indices, field names, & documents elastic_data = get_elasticsearch_data(client) # if there's no client then show on frontend if client != None: print ("html_elasticsearch() client:", client) |
Append the Elasticsearch data to the HTML string
Iterate over the each index and its document data and append <th> (table header) and <tr> (table row) elements to the HTML string, with each iteration, for the index’s name and fields:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | # iterate over the index names for index, val in elastic_data.items(): # create a new HTML table from the index name html += '<br><h3>Index name: ' + str(index) + '</h3>' html += '<table id="' + str(index) + '" class="table table-responsive">' # grab the "fields" list attribute created in get_elasticsearch_data() fields = source_data = elastic_data[index]["fields"] print ("\n\nfields:", fields) # new table row html += '\n<tr>' # enumerate() over the index fields for num, field in enumerate(fields): html += '<th>' + str(field) + '</th>' # close the table row for the Elasticsearch index fields html += '\n</tr>' |
Create a table row (<tr>) for each Elasticsearch document as well. The following code will iterate over the index’s documents and put each them inside of <tb> tags:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | # get all of the docs in the Elasticsearch index all_docs = elastic_data[index]["docs"] print ("\nall_docs type:", type(all_docs)) # enumerate() over the list of docs for num, doc in enumerate(all_docs): print ("\ndoc:", doc) # new row for each doc html += '<tr>\n' # iterate over the _source dict for the doc for f, val in doc["_source"].items(): html += '<td>' + str(val) + '</td>' html += '</tr>' |
Return an HTML warning if the connection to Elasticsearch is invalid
The last step in this part of the process is to close the <table> tag, and append a warning message to the HTML string if no data was returned, or if the client object is invalid:
1 2 3 4 5 6 7 | # close the table tag for the Elasticsearch index html += '</table><br>' elif client == None: html += '<h3 style="color:red">Warning: Elasticsearch cluster is not running on' html += ' port: ' + str(ELASTIC_PORT) + '</h3>' elif elastic_data == {}: html += '<h3>Elasticsearch did not return index information</h3>' |
This last part of the function will return the HTML string along with closing tags for the <body> and <html> elements:
1 2 | # return the HTML string return html + "</body></html>\n\n" |
Run the Elasticsearch web application using Python’s Bottle Framework
We can call then call the html_elasticsearch() function inside of the Bottle framework’s GET HTTP protocol function, and also pass the global parameters to the Bottle library’s run() method:
1 2 3 4 5 6 7 8 9 10 11 | @get('/') def elastic_app(): # call the func to return HTML to framework return html_elasticsearch() # pass a port for the framework's server run( host = DOMAIN, port = BOTTLE_PORT, debug = True ) |
Conclusion to creating an Elasticsearch web application in Python
Run the web application using the python3 command followed by the script name:
1 | python3 elastic_app.py |
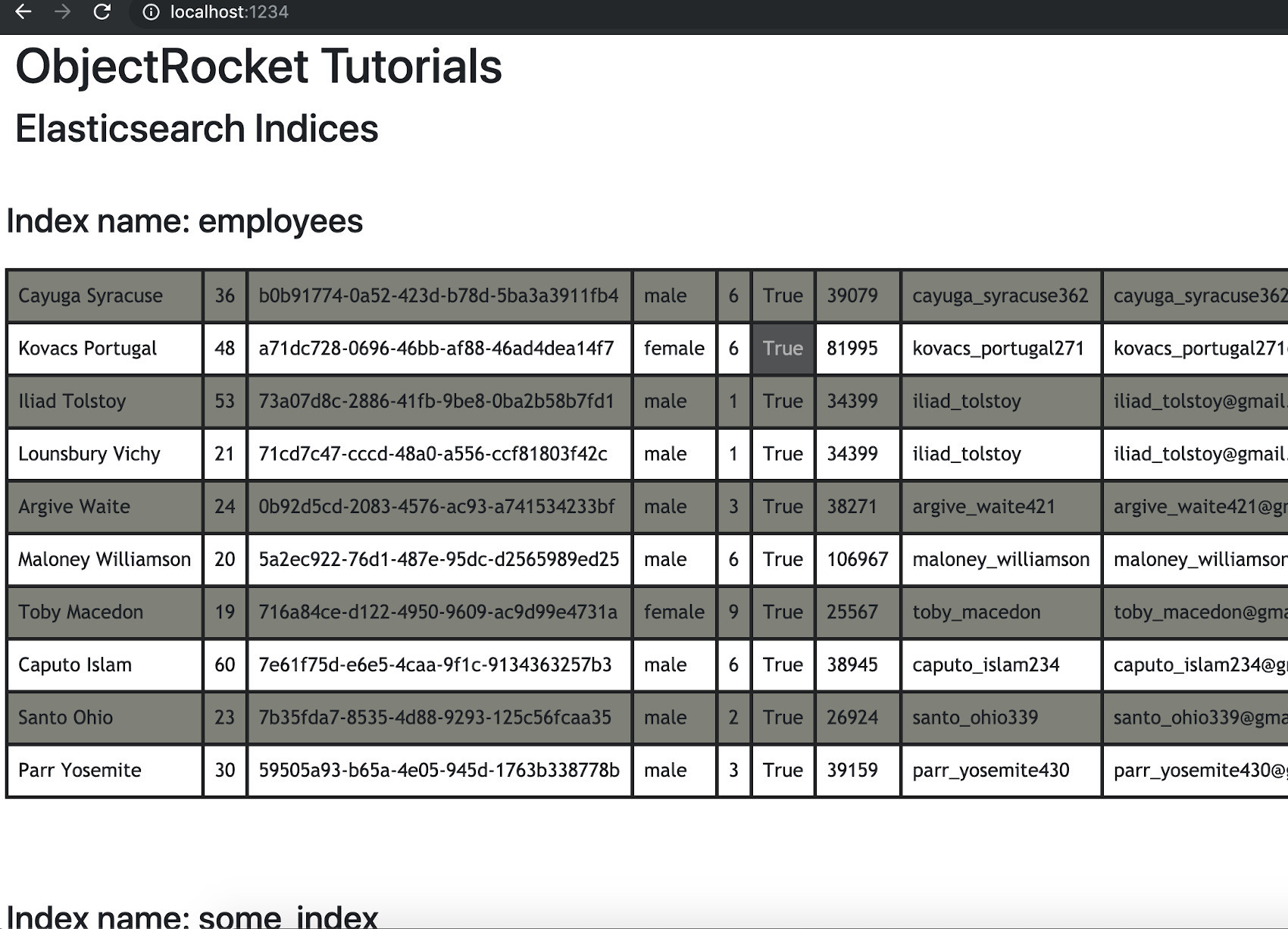
You should see Python return something like the following in your terminal window:
1 2 | Listening on http://localhost:1234/ Hit Ctrl-C to quit. |
Restarting the Elasticsearch web application
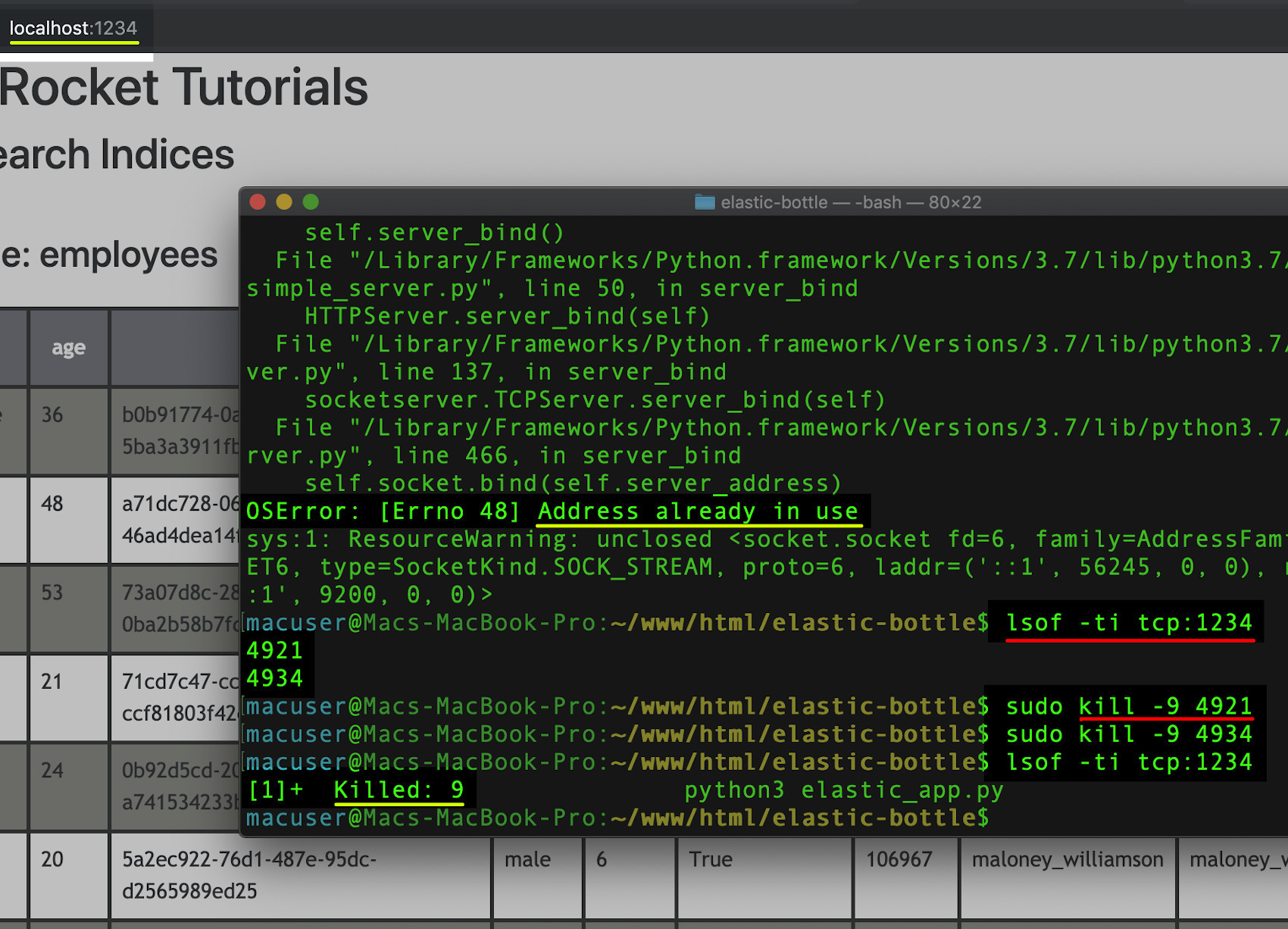
If Python returns an error saying: OSError: [Errno 48] Address already in use, then type lsof -ti tcp:1234 to search for the process using the open port. Once you get the PID (Process ID) for the process just use the kill -9 command (followed by the PID) to kill it before attempting to run the script again.
This concludes the two-part series explaining how you can build a simple Elasticsearch web application in Python using the Bottle framework. Below you can find the complete Python code used in this article.
Just the Code
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 | #!/usr/bin/env python3 #-*- coding: utf-8 -*- # import the run and get methods from the bottle library from bottle import run, get # import the elasticsearch client library from elasticsearch import Elasticsearch # import Python's json library to format JSON responses import json # use codecs to open the existing HTML file import codecs # globals for the Elasticsearch domain # ResourceWarning: unclosed <socket.socket> error if HTTP in domain DOMAIN = "localhost" ELASTIC_PORT = 9200 BOTTLE_PORT = 1234 try: # concatenate a string for the Elasticsearch connection domain_str = DOMAIN + ":" + str(ELASTIC_PORT) # declare a client instance of the Python Elasticsearch library client = Elasticsearch( domain_str ) # info() method raises error if domain or conn is invalid print (json.dumps( Elasticsearch.info(client), indent=4 ), "\n") except Exception as err: print ("Elasticsearch() ERROR:", err, "\n") # client is set to none if connection is invalid client = None def get_elasticsearch_data(client, query={}, page=0): # create a dict for the Elasticsearch docs all_docs = {} # make API call if client is not None if client != None: # returns a list of all the cluster's indices all_indices = client.indices.get_alias("*") # iterate over the index names for ind in all_indices: # skip hidden indices with '.' in name if "." not in ind[:1]: # nest another dictionary for index inside all_docs[ ind ] = {} # print the index name print ( "\nindex:", ind ) # get 20 of the Elasticsearch documents from index docs = client.search( from_ = page, # for pagination index = ind, body = { 'size' : 10, 'query': { # pass query paramater 'match_all' : query } }) # get just the doc "hits" docs = docs["hits"]["hits"] # print the list of docs print ("index:", ind, "has", len(docs), "num of docs.") # put the list of docs into a dict key all_docs[ ind ]["docs"] = docs try: # returns dict object of the index _mapping schema raw_data = client.indices.get_mapping( ind ) print ("get_mapping() response type:", type(raw_data)) # returns dict_keys() obj in Python 3 mapping_keys = raw_data[ ind ]["mappings"].keys() print ("\n_mapping keys():", mapping_keys) # get the index's doc type doc_type = list(mapping_keys)[0] print ("doc_type:", doc_type) # get the schema by accessing index's _doc type schema = raw_data[ ind ]["mappings"][ doc_type ]["properties"] print ("all fields:", list(schema.keys()) ) all_docs[ ind ]["fields"] = schema all_docs[ ind ]["doc_type"] = doc_type except Exception as err: print ("client.indices error:", err) all_docs[ ind ]["fields"] = {} all_docs[ ind ]["doc_type"] = doc_type # return all of the doc dict return all_docs # gef a function that will return HTML string for frontend def html_elasticsearch(): html_file = codecs.open("index.html", 'r') html = html_file.read() # get all of the Elasticsearch indices, field names, & documents elastic_data = get_elasticsearch_data(client) # if there's no client then show on frontend if client != None: print ("html_elasticsearch() client:", client) # iterate over the index names for index, val in elastic_data.items(): # create a new HTML table from the index name html += '<br><h3>Index name: ' + str(index) + '</h3>' html += '<table id="' + str(index) + '" class="table table-responsive">' # grab the "fields" list attribute created in get_elasticsearch_data() fields = source_data = elastic_data[index]["fields"] print ("\n\nfields:", fields) # new table row html += '\n<tr>' # enumerate() over the index fields for num, field in enumerate(fields): html += '<th>' + str(field) + '</th>' # close the table row for the Elasticsearch index fields html += '\n</tr>' # get all of the docs in the Elasticsearch index all_docs = elastic_data[index]["docs"] print ("\nall_docs type:", type(all_docs)) # enumerate() over the list of docs for num, doc in enumerate(all_docs): print ("\ndoc:", doc) # new row for each doc html += '<tr>\n' # iterate over the _source dict for the doc for f, val in doc["_source"].items(): html += '<td>' + str(val) + '</td>' html += '</tr>' # close the table tag for the Elasticsearch index html += '</table><br>' elif client == None: html += '<h3 style="color:red">Warning: Elasticsearch cluster is not running on' html += ' port: ' + str(ELASTIC_PORT) + '</h3>' elif elastic_data == {}: html += '<h3>Elasticsearch did not return index information</h3>' # return the HTML string return html + "</body></html>\n\n" @get('/') def elastic_app(): # call the func to return HTML to framework return html_elasticsearch() # pass a port for the framework's server run( host = DOMAIN, port = BOTTLE_PORT, debug = True ) |


Pilot the ObjectRocket Platform Free!
Try Fully-Managed CockroachDB, Elasticsearch, MongoDB, PostgreSQL (Beta) or Redis.
Get Started