Index a Bytes String into Elasticsearch with Python
Introduction to Elasticsearch and Python
The Python low-level REST client for Elasticsearch maps closely to the Java API for the Elasticsearch client. This article demonstrates how you can use the client to create a _mapping schema for a document with an encoded bytes string, and then index an encoded dictionary. The article will demonstrate how to encode and decode the data as well. Now let’s jump into how to index a bytes string into Elasticsearch with Python.
Prerequisites to index a bytes string into Elasticsearch using Python
The code in this article requires that you have Python 3 and its PIP package manager installed on the machine or server executing the script. Use the
python3 -Vandpip3 -Vcommands to check if they’re installed by having them return their respective version numbers.Use the PIP3 package manager to install the Elasticsearch client distribution for Python with the following command:
pip3 install elasticsearch.Check if the Elasticsearch cluster is running on your localhost by making a cURL request in a terminal or command prompt with:
curl 127.0.0.1:9200.
Importing the Elasticsearch packages into a Python script
Create a new Python script and import the Elasticsearch, base64, json, and other libraries that will assist in processing the data to be indexed:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | # import the built-in JSON library import json # import Datetime for the document's timestamp from datetime import datetime # import the sleep library from time import sleep # import base64 to encode/decode data import base64 # import the Elasticsearch client library from elasticsearch import Elasticsearch |
Declare a Python instance of the Elasticsearch client library
Pass your cluster’s host settings, as a string, to the Elasticsearch() method call to instantiate an instance of the client which you will use to make API calls:
1 2 | # declare a client instance of the Python Elasticsearch library client = Elasticsearch("http://localhost:9200") |
Create a ‘_mapping’ schema for an Elasticsearch index
Creating a _mapping schema for the index is optional (since Elasticsearch will dynamically create one for you when you index the document), but, for the sake of data integrity and consistency, it’s a good idea to create one nonetheless.
Use a Python ‘dict’ object for the Elasticsearch index’s ‘_mapping’ schema
Python dictionary’s are JSON compliant and are ideal for passing data to the client API. The following example code shows how you can create a _mapping schema for your index in Python:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | # declare a _mapping schema using a Python dict schema = { "mappings": { "properties": { "string field": { "type": "text" # formerly "string" }, "integer field": { "type": "integer" }, "boolean field": { "type": "boolean" }, "encoded field": { "type": "binary" # for Python 'bytes' data type }, "timestamp": { "type": "date", "format": "yyyy-MM-dd HH:mm:ss.SSSSSS" # data format for Python's datetime.now() method } } } } |
NOTE: Encoded byte strings (bytes data type in Python) require that you use the "binary" field value in the Elasticsearch schema.
Use the Python client’s ‘indices’ library to create an Elasticsearch schema
The next example creates an Elasticsearch index by passing the _mapping dictionary schema to the client’s indices.create() method call via the body parameter:
1 2 3 4 5 6 | # get a response from the Elasticsearch cluster resp = client.indices.create( index = "some_index", body = schema ) print ("_mapping response:", json.dumps(resp, indent=4), "\n") |
NOTE: Unless you pass a the optional ignore = 400 parameter to the method call, the Elasticsearch cluster will raise an "index_already_exists_exception" error if the index specified already exists.
Serialize some Python data for an Elasticsearch document
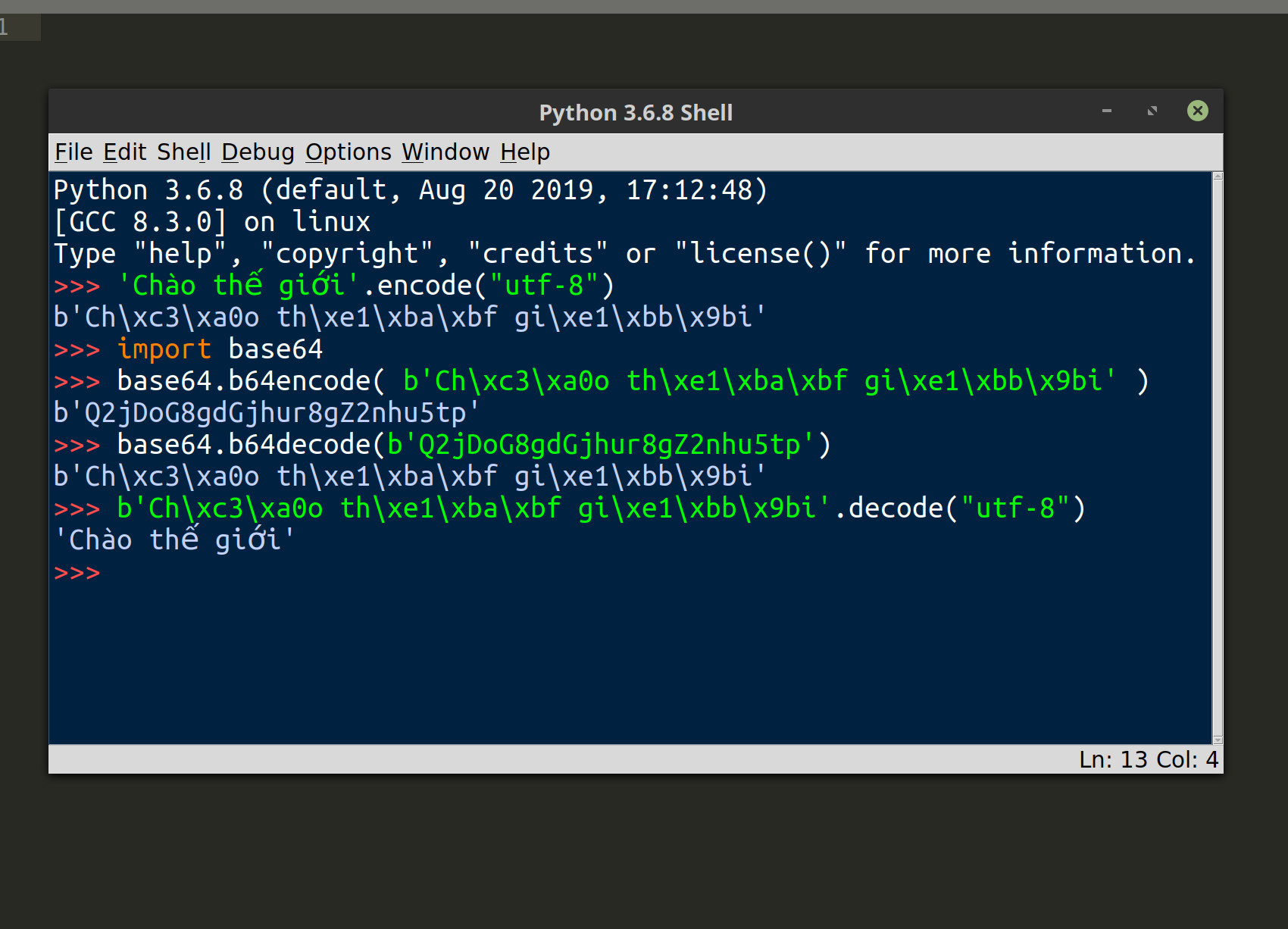
Now that the index and schema are created you can index some document data to it. Here’s how you can encode a dict object using Python’s encode() method call:
1 2 3 4 5 6 7 8 9 10 | # declare a data object to be serialized data = {"hello": "world", "some num": 987654} # use the json library to convert dict object to a JSON string json_str = json.dumps( data ) # encode the JSON string to a bytes strings json_bytes = json_str.encode('utf-8') print ("json_bytes:", json_bytes) print ("type json_bytes:", type(json_bytes), "\n") |
Use Python’s ‘base64’ library to encode the byte string
Use the base64.b64encode() method to encode your data, using the Base64 algorithm, before nesting it inside of an Elasticsearch document’s _source field:
1 2 3 4 5 6 7 8 9 10 | # TypeError: a bytes-like object is required, not 'dict' encoded_data = base64.b64encode( json_bytes ) print ("encoded_data:", encoded_data) print ("type encoded_data:", encoded_data, "\n") # cast the bytes object as a string encoded_str = str( encoded_data ) # remove b'' to avoid UnicodeDecodeError encoded_str = encoded_str[2:-1] |
NOTE: The last line of code slices the encoded string in order to remove the b'' from the string so that you don’t get a UnicodeDecodeError while deserializing the document data later on.
Index the serialized data as an Elasticsearch document
It’s not time to create the document’s _source data. Here’s an example of how you can pass the encoded Base64 string to another Python dictionary that will then get indexed to Elasticsearch:
1 2 3 4 5 6 7 8 9 | # dictionary object for the Elasticsearch document _source doc_source = { "string field": "Chào thế giới", "integer field": 12345, "boolean field": True, "encoded field": encoded_str, "timestamp": str(datetime.now()) # create timestamp } print ("doc_source:", json.dumps(doc_source, indent=4), "\n") |
Pass the nest dictionary object to the Elasticsearch client’s ‘index()’ method call
The following example passes the dict document object to the method’s body parameter and returns a response from the Elasticsearch cluster:
1 2 3 4 5 6 7 | # pass the doc source to the client's index() method resp = client.index( index = "some_index", id = 1111, body = doc_source ) print ("client.index() response:", resp, "\n") |
Get the Elasticsearch document and deserialize its data
You can use the Python time library’s sleep() method to force the script to briefly pause before making another API call. This will allow the cluster enough time before another call is made to retrieve the document:
1 2 | # pause the script for one second sleep(1) |
NOTE: The sleep() method allows you to pass floats, as well as integers, to its method call. Pass 0.5 to it instead if you’d like the script to “sleep” for only half a second.
Use the Python client once more to get the Elasticsearch document
Pass the Elasticsearch document _id to the client’s get() method to have the cluster return the document in the response:
1 2 3 4 5 6 | # get the document just indexed doc = client.get( index = 'some_index', id = 1111 ) print ("\ndoc:", json.dumps(doc, indent=4)) |
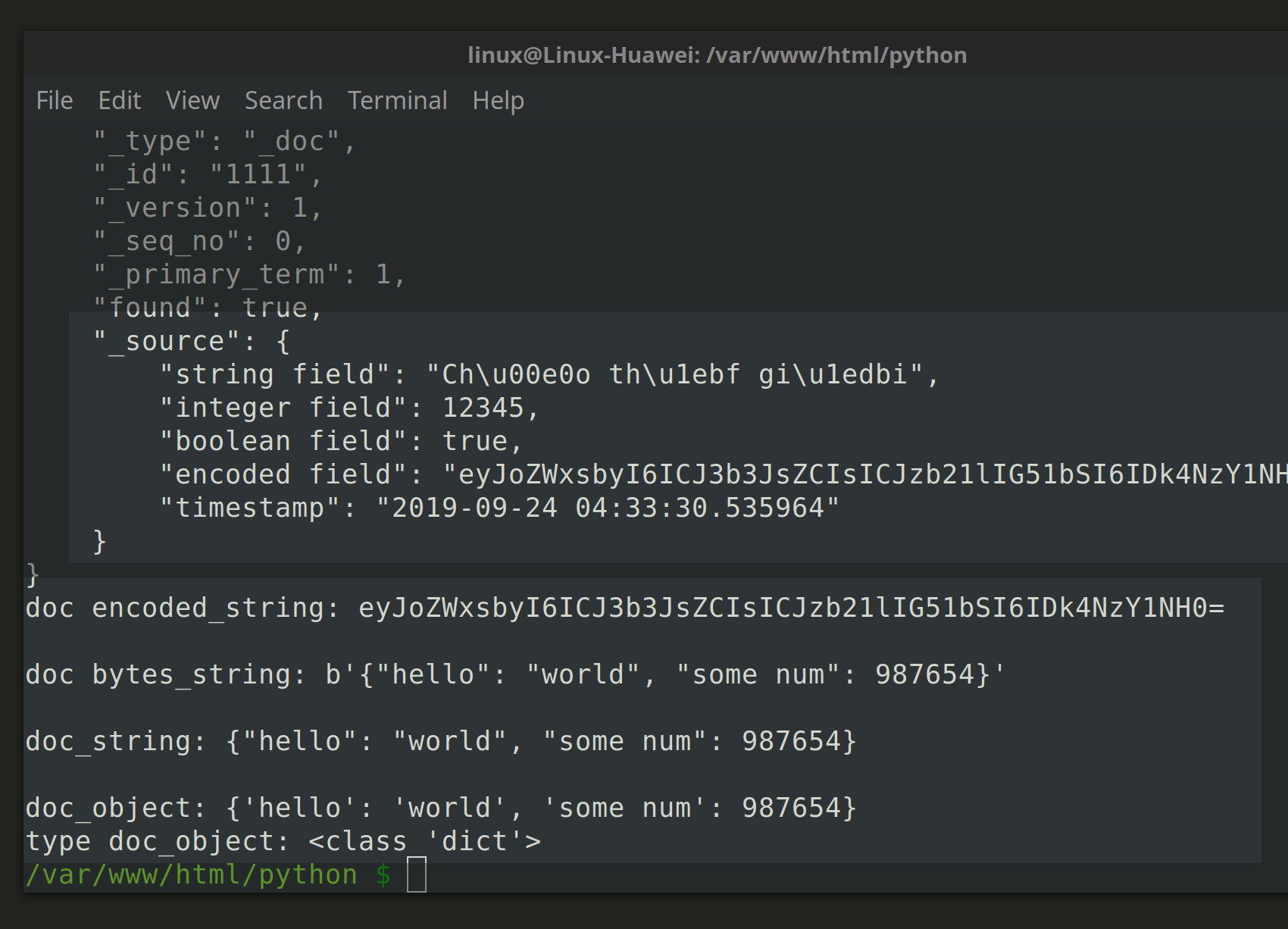
The encoded string from earlier will be nested inside the dictionary response’s "_source" key:
1 2 3 | # get the encoded bytes string from the doc _source encoded_string = doc["_source"]["encoded field"] print ("doc encoded_string:", encoded_string, "\n") |
Use Base64 again to decode the Python bytes string
Pass the data stored inside the "encoded field" key to the Base64 library’s b64decode() method to have it return a decoded bytes string :
1 2 3 4 | # use base64 to decode the string bytes_string = base64.b64decode( encoded_string ) print ("doc bytes_string:", bytes_string, "\n") |
Use Python’s JSON library to convert the string to a dictionary object
Use Python’s json library to convert the string object into a dictionary by invoking its loads() method call:
1 2 3 4 5 6 7 8 | # decode the bytes string doc_string = bytes_string.decode("utf-8") print ("doc_string:", doc_string, "\n") # use json.loads() to create a dict object from string doc_object = json.loads( doc_string ) print ("doc_object:", doc_object) print ("type doc_object:", type(doc_object)) |
Conclusion to indexing a bytes string into Elasticsearch
Encoding the data on your NoSQL database helps, not only to compress your data and save space on your server, but also to keep your data safe, and make your search algorithms run more efficiently.
Python conveniently has built-in libraries that can help you to encode and serialize your sensitive data, and the client library for Elasticsearch makes it really easy to index the encoded data as documents.
Just the Code
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 | #!/usr/bin/env python3 #-*- coding: utf-8 -*- # import the built-in JSON library import json # import Datetime for the document's timestamp from datetime import datetime # import the sleep library from time import sleep # import base64 to encode/decode data import base64 # import the Elasticsearch client library from elasticsearch import Elasticsearch # declare a client instance of the Python Elasticsearch library client = Elasticsearch("http://localhost:9200") # declare a _mapping schema using a Python dict schema = { "mappings": { "properties": { "string field": { "type": "text" # formerly "string" }, "integer field": { "type": "integer" }, "boolean field": { "type": "boolean" }, "encoded field": { "type": "binary" }, "timestamp": { "type": "date", "format": "yyyy-MM-dd HH:mm:ss.SSSSSS" # data format for Python's datetime.now() method } } } } # get a response from the Elasticsearch cluster resp = client.indices.create( index = "some_index", body = schema ) print ("_mapping response:", json.dumps(resp, indent=4), "\n") # declare a data object to be serialized data = {"hello": "world", "some num": 987654} # use the json library to convert dict object to a JSON string json_str = json.dumps( data ) # encode the JSON string to a bytes strings json_bytes = json_str.encode('utf-8') print ("json_bytes:", json_bytes) print ("type json_bytes:", type(json_bytes), "\n") # TypeError: a bytes-like object is required, not 'dict' encoded_data = base64.b64encode( json_bytes ) print ("encoded_data:", encoded_data) print ("type encoded_data:", encoded_data, "\n") # cast the bytes object as a string encoded_str = str( encoded_data ) # remove b'' to avoid UnicodeDecodeError encoded_str = encoded_str[2:-1] # dictionary object for the Elasticsearch document _source doc_source = { "string field": "Chào thế giới", "integer field": 12345, "boolean field": True, "encoded field": encoded_str, "timestamp": str(datetime.now()) # create timestamp } print ("doc_source:", json.dumps(doc_source, indent=4), "\n") # pass the doc source to the client's index() method resp = client.index( index = "some_index", id = 1111, body = doc_source ) print ("client.index() response:", resp, "\n") # pause the script for one second sleep(1) # get the document just indexed doc = client.get( index = 'some_index', id = 1111 ) print ("\ndoc:", json.dumps(doc, indent=4)) # get the encoded bytes string from the doc _source encoded_string = doc["_source"]["encoded field"] print ("doc encoded_string:", encoded_string, "\n") # use base64 to decode the string bytes_string = base64.b64decode( encoded_string ) print ("type bytes_string:", type(bytes_string)) print ("doc bytes_string:", bytes_string, "\n") # decode the bytes string doc_string = bytes_string.decode("utf-8") print ("doc_string:", doc_string, "\n") # use json.loads() to create a dict object from string doc_object = json.loads( doc_string ) print ("doc_object:", doc_object) |

Pilot the ObjectRocket Platform Free!
Try Fully-Managed CockroachDB, Elasticsearch, MongoDB, PostgreSQL (Beta) or Redis.
Get Started