Elasticsearch and Scroll in Python
Introduction
Scrolling in Elasticsearch allows you retrieve a large number of documents, in steps or iterations, similar to pagination or a “cursor” in relational databases. In this article we’ll explore the Elasticsearch concept of scrolling, and how we can implement it in an application using the Python low-level client’s “helpers” library.
Let’s go over how to get documents from Elasticsearch with Scroll and Python.
Prerequisites
You’ll need to install the Elasticsearch service and start the cluster on your machine or server. Make sure that you have admin or sudo privileges so that you can install Python 3 or Elasticsearch if necessary.
Install Elasticsearch on Linux, Windows, and macOS
On a Linux distro that uses systemd you’ll have to download and install the archive and then use the systemctl utility to enable or start the service. Otherwise you can download the MSI installer for Windows, or use Homebrew’s brew command to tap and install the elastic repository on macOS.
Check that the Elasticsearch cluster is running
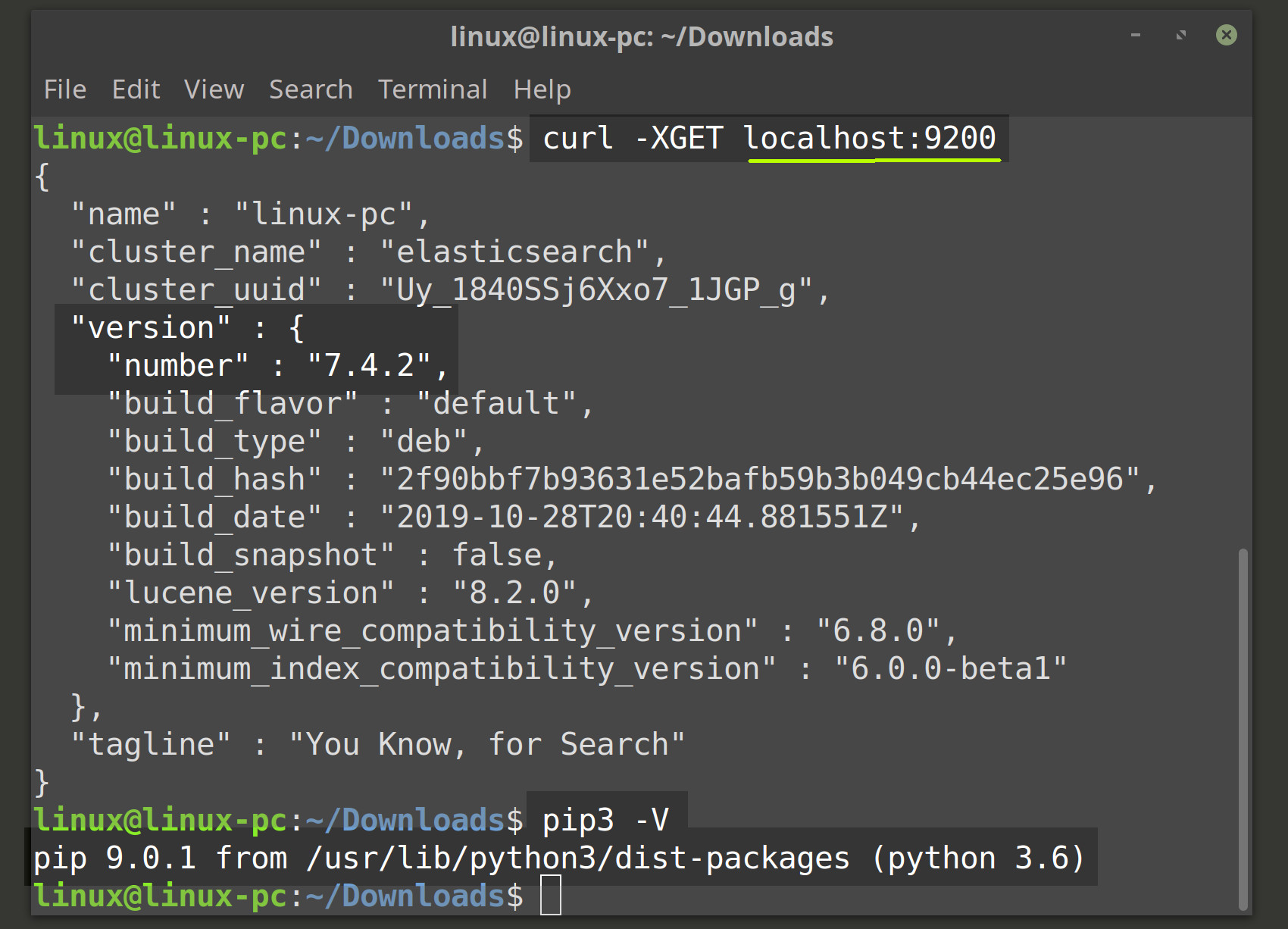
You should now be able to get a JSON response from your Elasticsearch cluster running on the default port of 9200. Navigate to localhost:9200 in a browser tab, if you’re developing locally, or use the following cURL request in a terminal or command prompt window to verify that the cluster is running:
1 | curl -XGET localhost:9200 |
The code used in this article has been designed and tested with Python version 3 in mind. The easiest way to install Python 3 modules is with the PIP package manager (pip3). Use the pip3 -V command to verify that the package manager is installed and working, and then use the following command to install the Elasticsearch client for Python:
1 | pip3 install elasticsearch |
Elasticsearch documents for the Scroll API
You’ll also need an index on your Elasticsearch cluster with a massive number of documents on it that you can use to test Elasticsearch’s Scroll API in Python. Check out our article about bulk indexing Elasticsearch documents in Python for more information.
Elasticsearch Scroll API
In a cURL or Kibana request you’d use an HTTP POST request to create a new index for that particular Elasticsearch scroll. The following is an example of such a request made in the Kibana Console UI and it should return the scroll’s "scroll_id" in the right panel:
1 2 3 4 | POST index_name/_search?scroll=3m { "size": 10 } |
NOTE: The 3m value in the above HTTP request is the time value that you’d like Elasticsearch to scroll for. You can use m for milliseconds and s for seconds, and, depending on the size of the documents and the overall index, a few milliseconds typically suffices.
Then all you have to do is make another HTTP request using the scroll ID, and this time you can use GET or POST, and you should omit the index name since it will be stored in the scroll index itself:
1 2 3 4 | GET /_search/scroll { "scroll_id" : "DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAANT4WaGc1NmFOV2JTLU9zUUZBVHEwc1c2Zw==" } |
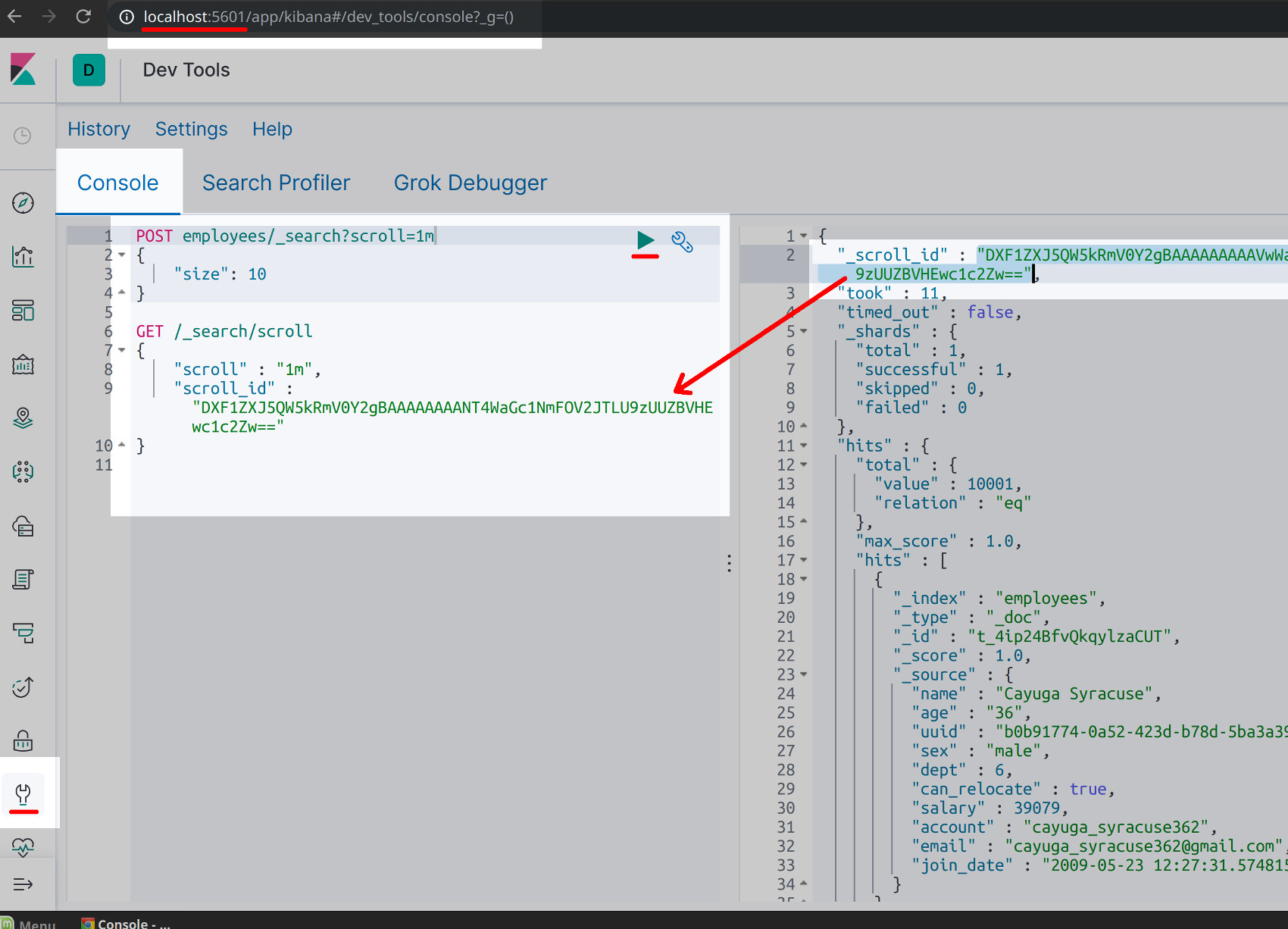
NOTE: The scroll ID will change if you make another scroll POST request with different parameters.
Scroll API in Python
There are three different ways to scroll Elasticsearch documents using the Python client library—using the client’s search() method, the helpers library’s scan() method, or the client’s scroll() method.
Scrolling Elasticsearch documents in Python
You can execute a regular search query that’s limited in size and has a scrolling time limit passed to it, or you can also use the client’s low-level scroll() method designed to work with Elastic’s Scroll API. The third option is to use the client’s helpers.scan() which works in a similar fashion to scroll().
Import the Python modules for Elasticsearch
The following Python code will import the Elasticsearch client and some of its libraries into the Python script:
1 2 3 4 | from elasticsearch import Elasticsearch, helpers, exceptions # import Python's json library to format JSON responses import json |
Connect to Elasticsearch in Python
1 2 3 4 5 | domain = "localhost" port = 9200 # concatenate host string from values host = domain + ":" + str(port) |
Once you’ve concatenated the string for the domain host you can pass it to the Elasticsearch() method and it should return a valid client instance connected to the cluster:
1 | client = Elasticsearch( host ) |
You can use the following code to validate the connection to the cluster:
1 2 3 4 5 6 7 8 9 10 11 | # set client to 'None' if client is invalid try: # get information on client client_info = Elasticsearch.info(client) print ('Elasticsearch client info:', json.dumps(client_info, indent=4)) except exceptions.ConnectionError as err: print ('Elasticsearch client error:', err) client = None if client != None: |
If you’re host string is correct, and if the Elasticsearch cluster is running properly, then the above code should print the cluster information, otherwise it will set the client instance to None.
Scrolling Elasticsearch documents with search()
Now let’s learn about using the client’s search() method to scroll through Elasticsearch documents. The first step is to create a JSON object (using a dict object in Python) with the search size and query Elasticsearch fields for the dictionary keys:
cURL
1 2 3 4 5 6 | search_body = { "size": 42, "query": { "match_all": {} } } |
The above dictionary example will match all of the index’s documents to provide enough data for scrolling, and it will return just 42 documents.
Call the Elasticsearch client’s search() method
Now pass the search_body dictionary declared above to the client instance’s search() method and make sure to specify the index name as a parameter:
1 2 3 4 5 6 7 8 | resp = client.search( index = "index_name", body = search_body, scroll = '3m', # time value for search ) # get the number of docs with len() print ("total docs:", len(resp["hits"]["hits"])) |
The above code will scroll for just 3 milliseconds. Make sure to increase that time for larger documents, or for a scroll procedure returning more documents.
We can now get the scroll ID from the response by accessing its _scroll_id key:
1 | scroll_id = resp['_scroll_id'] |
Scrolling Elasticsearch documecURL nts with scroll()
The second option is to use the client’s scroll() method, and now that we have a scroll ID we can pass it to its method call to continue the query:
1 2 3 4 5 6 | resp = client.scroll( scroll_id = scroll_id, scroll = '1s', # time value for search ) print ('scroll() query length:', len(resp)) |
The method’s parameters are body, rest_total_hits_as_int, scroll, and scroll_id. Unlike the helper library’s scan() method, scroll() does not accept a size parameter, but the optional scroll ID parameter should come in handy.
NOTE: The Boolean parameter rest_total_hits_as_int was introduced in version 7.0, and when set to True is will return the total number of document “hits” as an integer value.
Scrolling Elasticsearch documents with helpers.scan()
The last scan() method is a part of the client’s helpers library, and it’s basically a wrapper for the aforementioned scroll() method. The key difference us that helpers.scan() will return a generator instead of a JSON dictionary response.
cURL
One interesting feature of scan is that the index name is optional. The following is an example of how you can use it to scan for all the documents on the cluster:
1 2 3 4 5 6 7 8 9 | # call the helpers library's scan() method to scroll resp = helpers.scan( client, scroll = '3m', size = 10, ) # returns a generator object print (type(resp)) |
As mentioned earlier, the method should return a generator object. The following code will explicitly cast the generator as a list in order to get its length with len() so that we can see how many documents were returned:
1 | print ('\nscan() scroll length:', len( list( resp ) )) |
We can also enumerate the documents using the following example code:
1 2 | for num, doc in enumerate(resp): print ('\n', num, '', doc) |
The following is a model of all the possible parameters, and their respective default values, that you can pass to the scan() method:
1 2 3 4 5 6 7 8 9 10 11 12 | elasticsearch.helpers.scan( client, query = None, scroll = '5m',cURL raise_on_error = True, preserve_order = False, size = 1000, request_timeout = None, clear_scroll = True, scroll_kwargs = None, **kwargs ) |
Execute the Python script
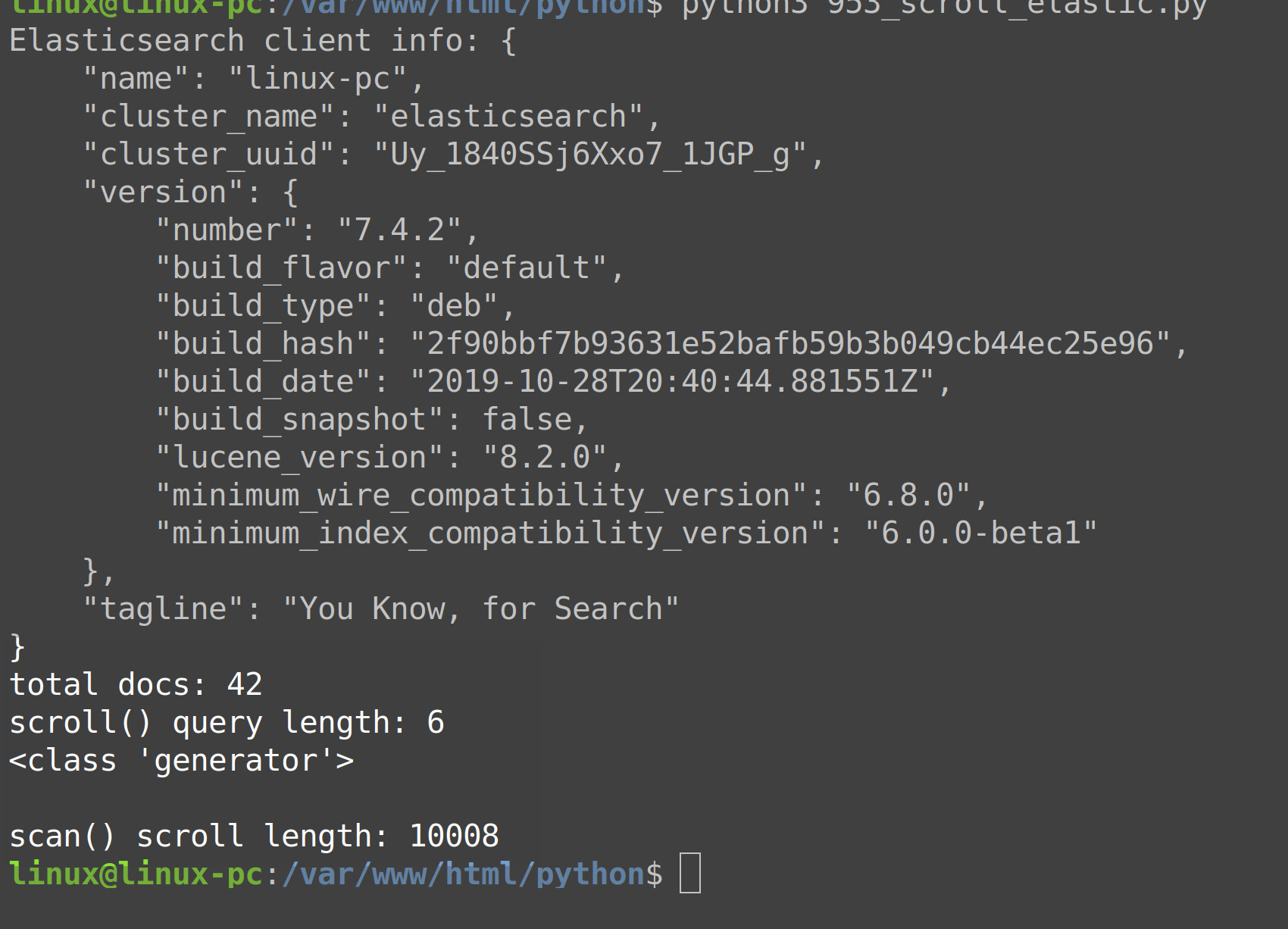
Now, make sure to save the code in your Python script and use the python3 command in a terminal window to execute the script. Python should print some results that look something like the following:
1 2 3 4 5 6 | $ python3 scroll_test.py total docs: 42 scroll() query length: 6 <class 'generator'> scan() scroll length: 10008 |
Conclusion to the Scroll API
We’ve covered three different ways to scroll or scan through Elasticsearch documents using the Python low-level client library. The most common use case for scrolling documents is to reindex or copy an Elasticsearch index. Check out the example Python code in its entirety below.
Just the Code
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 | #!/usr/bin/env python3 #-*- coding: utf-8 -*- from elasticsearch import Elasticsearch, helpers, exceptions # import Python's json library to format JSON responses import json # globals for the client connection domain = "localhost" port = 9200 # concatenate host string from values host = domain + ":" + str(port) # declare an instance of the Elasticsearch library client = Elasticsearch( host ) # set client to 'None' if invalid try: # get information on client client_info = Elasticsearch.info(client) print ('Elasticsearch client info:', json.dumps(client_info, indent=4)) except exceptions.ConnectionError as err: print ('Elasticsearch client error:', err) client = None if client != None: # JSON body for the Elasticsearch query search_body = { "size": 42, "query": { "match_all": {} } } # make a search() request to scroll documents resp = client.search( index = "employees", body = search_body, scroll = '3m', # time value for search ) print ("total docs:", len(resp["hits"]["hits"])) # get the JSON response's scroll_id scroll_id = resp['_scroll_id'] # scroll Elasticsearch docs with scroll() method resp = client.scroll( scroll_id = scroll_id, scroll = '1s', # time value for search ) print ('scroll() query length:', len(resp)) # get the JSON response's scroll_id scroll_id = resp['_scroll_id'] # call the helpers library's scan() method to scroll resp = helpers.scan( client, scroll = '3m', size = 10, ) # returns a generator object print (type(resp)) # cast generator as list to get length print ('\nscan() scroll length:', len( list( resp ) )) # enumerate the documents for num, doc in enumerate(resp): print ('\n', num, '', doc) |


Pilot the ObjectRocket Platform Free!
Try Fully-Managed CockroachDB, Elasticsearch, MongoDB, PostgreSQL (Beta) or Redis.
Get Started