Use Python To Query Elasticsearch In A Terminal Window
Introduction
If you’re using Elasticsearch to store and search your data, it’s important to know that you can query your data from a number of different sources. One way to to query documents is to pass an Elasticsearch index and a query term to a Python script from a terminal window, having Python return an Elasticsearch API query response. In this article, we’ll walk through an example of having Python query Elasticsearch from a terminal window.
Prerequisites
Let’s review a few prerequisites that need to be taken care of before we jump into the Python code:
- First, the Elasticsearch cluster should be installed and running on the same server or machine running the Python script that will be making the query requests. Elasticsearch typically runs on the default port of
9200, and you can use cURL to get a response from the cluster using the following command:
1 | curl -XGET localhost:9200 |
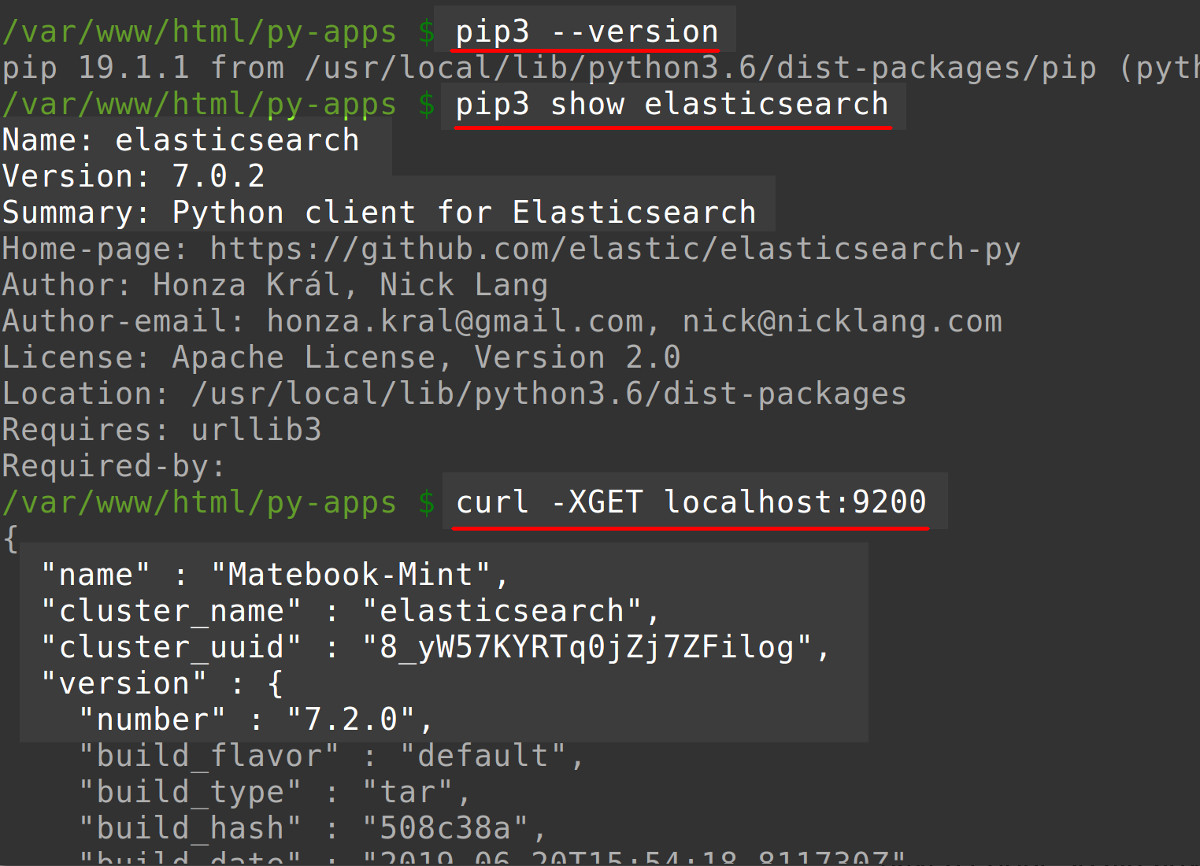
You’ll need to make sure PIP for Python 3 is installed and working properly. Use the command
pip3 --versionto see if PIP is installed.You’ll need to have access to a UNIX-based terminal for the Elasticsearch cluster’s server or machine. In Linux you can press CTRL+Alt+T to open a new terminal window; otherwise, you can just open a new Finder window in macOS, navigate to the “Utilities” folder and open
Terminal.appfrom there:
- You’ll also need to install the Python client library for Elasticsearch using
pip3if you haven’t done so already:
1 | pip3 install elasticsearch |
You can use the pip3 show elasticsearch command to get additional information on the Elasticsearch library for Python.
- Last but not least, you’ll need to have a few documents stored in an Elasticsearch index that you can query. Make sure the index name is spelled correctly when you call the Python script and pass it as an argument.
Create a Python script that will make requests to Elasticsearch
Once all the prerequisites are in place, we can start working on our Python script. In a terminal window, navigate to your Elasticsearch project folder or somewhere on the main node or server that runs the cluster, and create a new Python script that will be used to make Elasticsearch requests. Our script will be named query.py:
1 | touch query.py |
Import the packages needed to make requests to the Elasticsearch cluster
You can write your script in an IDE that supports Python syntax, or you can use a terminal-based editor like nano, gedit, or vim. The first code we’ll add to our script is used to import all the packages we’ll need:
1 2 3 4 5 6 7 8 | #!/usr/bin/env python3 #-*- coding: utf-8 -*- # use sys for system arguments passed to script import sys, json # import the Elasticsearch client library from elasticsearch import Elasticsearch |
The native sys and json Python packages, as well as Elastic’s elasticsearch library, will be used in our script to query Elasticsearch.
Instantiate an Elasticsearch client in the Python script
Next, let’s have the Elasticsearch class return a client instance. When you do this, don’t forget to pass the appropriate domain name and port in the URL string. You can leave the string empty if your cluster is on the default localhost:9200:
1 2 | # create a client instance of Elasticsearch client = Elasticsearch("http://localhost:9200") |
Get the Elasticsearch index name from one of the system arguments passed
When we call our Python script, we’ll have to pass some arguments to it so that Elasticsearch will know what to query and what index to query. Each argument should be delimited by a space.
In this example, after the name of the script itself, we’ll pass the name of the Elasticsearch index that we want to query. Later in the script, you’ll see that we also pass two additional arguments that represent the field name and the query itself:
1 2 3 4 5 6 | # second arg [1] is for the Elasticsearch index's name try: INDEX_NAME = sys.argv[1] except IndexError as err: print ("IndexError - Script needs the Elasticsearch index name:", err) quit() |
Declare a Python function that will make a query request to Elasticsearch
In the function shown below, we check to make sure the specified index exists at the beginning because the query won’t work if the index doesn’t exist. This function needs to have a filter Python dictionary passed to it as a parameter:
1 2 3 4 5 6 7 | def make_query(filter): index_exists = client.indices.exists(index=INDEX_NAME) # check if the index exists if index_exists == True: print ("INDEX_NAME:", INDEX_NAME, "exists.") print ("FILTER:", filter, "\n") |
Make an API query request to Elasticsearch in a try-except block
Next, we’ll call the Elasticsearch client’s search() method in a try-except exception block. We’ll make sure to pass the INDEX_NAME variable to it as the index parameter along with the filter query dictionary object as the body parameter:
1 2 3 4 5 6 | try: # use JSON for literal string arguments #filter = json.loads(filter) # pass filter query to the client's search() method response = client.search(index=INDEX_NAME, body=filter) |
Iterate the API response returned by Elasticsearch
The function will iterate over the response object that’s returned by the Elasticsearch cluster, and it will print the document "hits" that match the query:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | # print the query response print ('response["hits"]:', len(response["hits"])) print ('response TYPE:', type(response)) # iterate the response hits print ("\nDocument %d hits:" % response['hits']['total']['value']) for hit in response['hits']['hits']: print(hit["_source"]) except Exception as err: print ("search(index) ERROR", err) response = {"error": err} # return an empty dict if index doesn't exist else: response = {} return response |
Declare the main() function and check the query arguments passed in the terminal window
The next step is to declare a main() function, which the Python interpreter will call when running the script. We’ll get the sys.argv list of arguments that get passed to it in the terminal, then we’ll pass the first item in that list to the pop() function. We do this to remove the Python script name, which is always the first argument in the list, because we won’t be needing it:
1 2 3 4 5 6 7 | def main(): # declare variable for system arguments list sys_args = sys.argv # remove Python script name from args list sys_args.pop(0) |
Make sure that there are exactly three arguments passed
In order for our Elasticsearch query to work, there needs to be exactly three arguments when calling the Python script’s main() function:
1 2 3 4 5 | # quit the script if there are not exactly 3 arguments if len(sys_args) != 3: print ("Three arguments needed. You provided:", sys_args) print ("First argument is index, and next two are the field and query:", sys_args) quit() |
Pass a filter dict to the make_query()
If we verify that there were three system arguments passed to the script via the terminal command, then we proceed to create a new filter Python dictionary object from the argument values:
1 2 3 4 5 6 7 8 9 10 11 12 13 | else: # get the field name and query value from sys args field_name = sys_args[1] value = sys_args[2] # pass the field name and value args to filter dict filter = { 'query': { 'match': { field_name: value } } } |
Then, we pass the filter dict to the make_query() function that was declared earlier outside of the main() function:
1 2 | # pass the filter dict to the make_query() function resp = make_query(filter) |
Have the Python interpreter call the main() function when the script is run
The final step in creating our script is to instruct the Python interpreter to call the main() module:
1 2 | if __name__ == "__main__": main() |
Conclusion
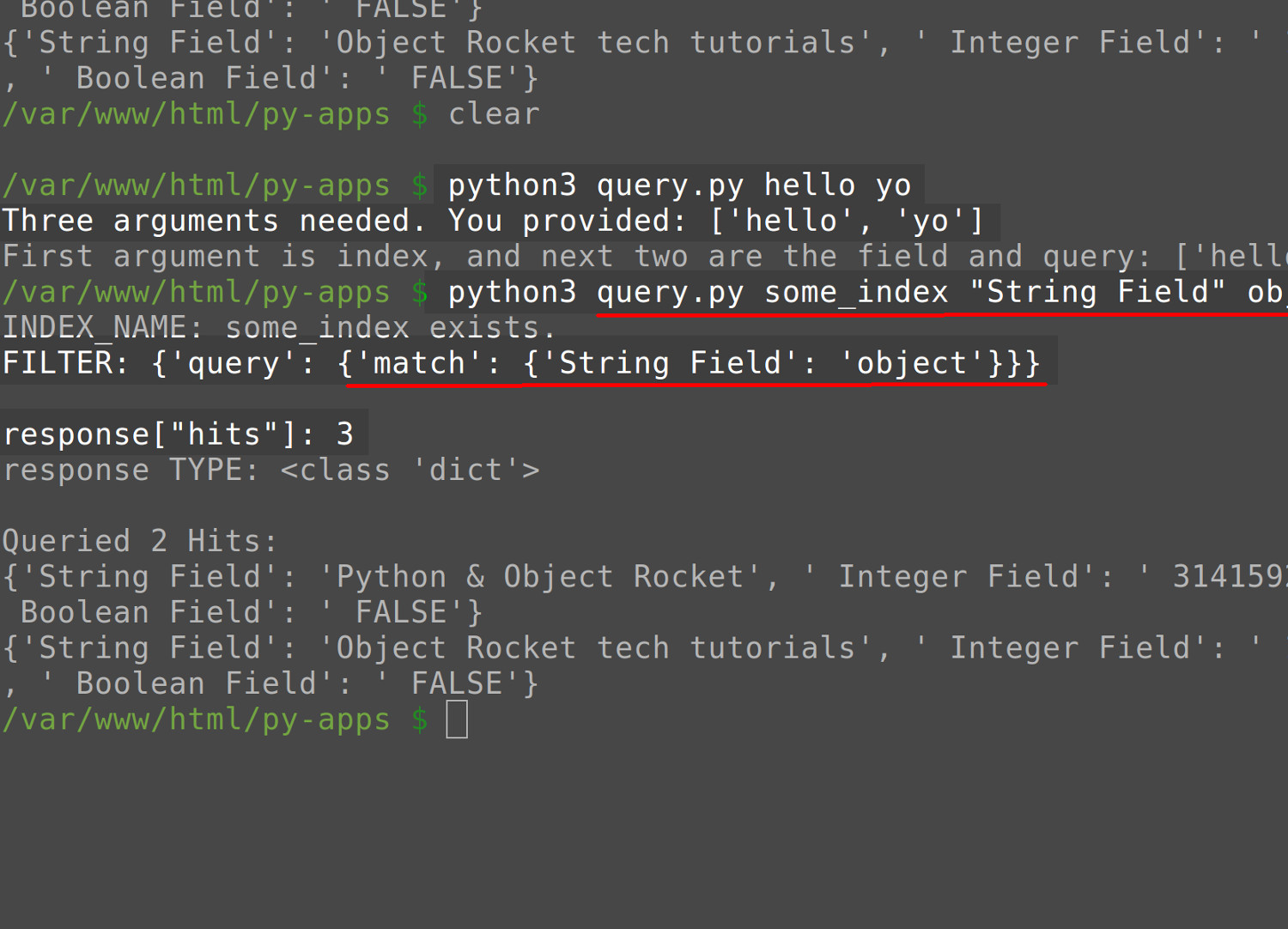
Now that our script is complete, all we need to do is run it. To do this, open a terminal window and use the python3 command to run the Python script, passing three arguments delimited by spaces—- the Elasticsearch index name, the field being queried and the partial match query string. Make sure to enclose the query in quotation marks if any of these arguments is made up of more than one word.
1 2 | # python3 script_name.py "Index Name" "Field Name" "search for this" python3 query.py some_index "String Field" object |
Assuming that there are no errors and there are matching documents in Elasticsearch, the output should look something like this:
1 2 3 4 5 6 7 8 9 | INDEX_NAME: some_index exists. FILTER: {'query': {'match': {'String Field': 'object'}}} response["hits"]: 3 response TYPE: <class 'dict'> Queried 2 Hits: {'String Field': 'Python & Object Rocket', ' Integer Field': ' 31415926535', ' Boolean Field': ' FALSE'} {'String Field': 'Object Rocket tech tutorials', ' Integer Field': ' 16180339', ' Boolean Field': ' FALSE'} |
Make Elasticsearch queries by passing arguments to a Python script in a terminal prompt
Use Kibana to search all of the documents in an Elasticsearch index
If you’re running the Kibana service on the cluster, you can open Kibana’s Console UI and verify the documents in the some_index Elasticsearch index. Just navigate to the Dev Tools section and make the following request to search for all of the some_index Elasticsearch index’s documents:
1 | GET some_index/_search |
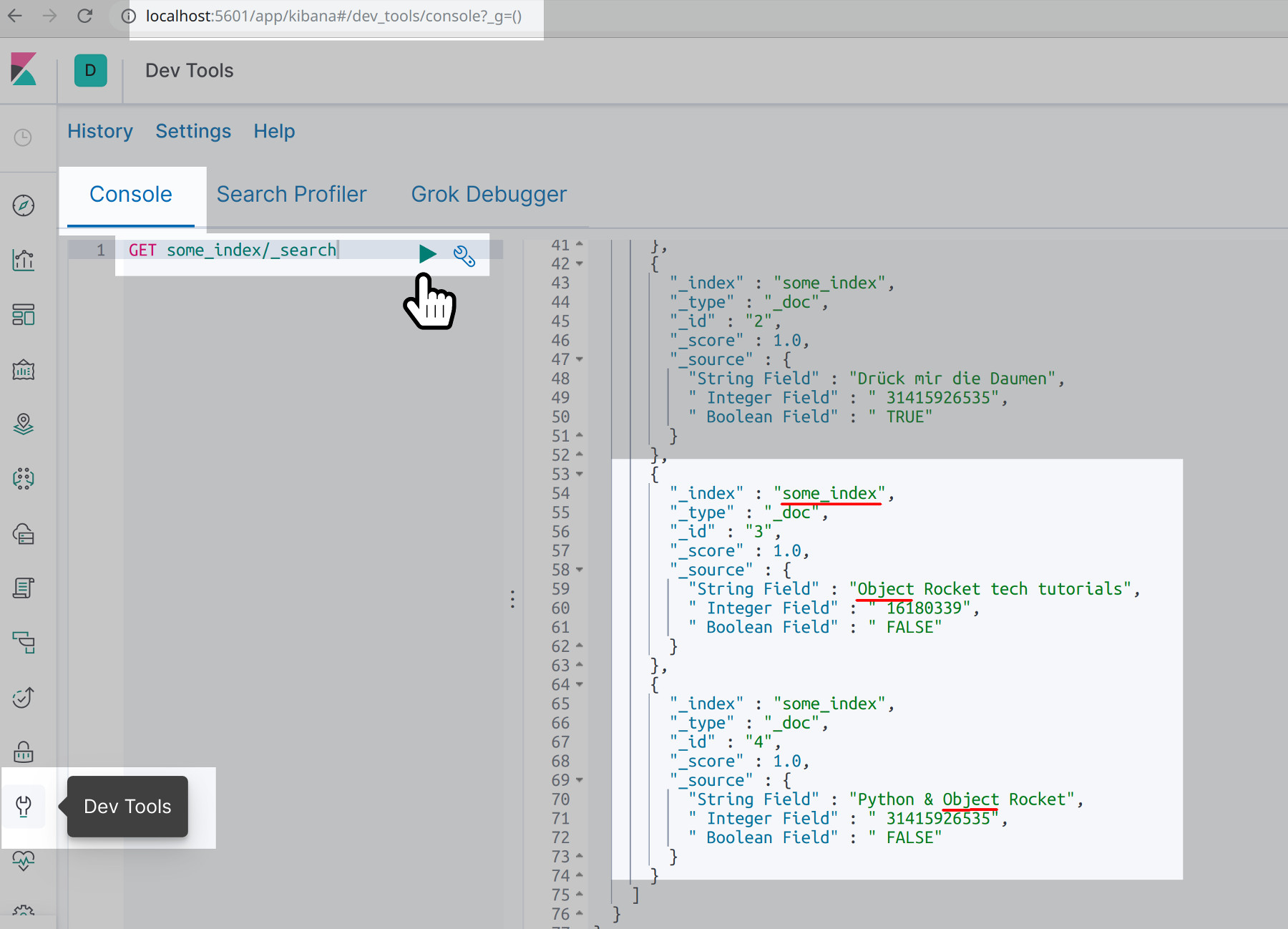
Notice that the search query is not case-sensitive, nor is it an exact match, because a query of just “object” returned the two documents shown in the screenshot.
Just the Code
We’ve looked at quite a bit of Python code throughout this tutorial. Shown below is the example script in its entirety:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 | #!/usr/bin/env python3 #-*- coding: utf-8 -*- # use sys for system arguments passed to script import sys, json # import the Elasticsearch client library from elasticsearch import Elasticsearch # create a client instance of Elasticsearch client = Elasticsearch("http://localhost:9200") # The script name is the first arg [0], but the second arg [1] # can be used for the Elasticsearch index's name try: INDEX_NAME = sys.argv[1] except IndexError as err: print ("IndexError - Script needs the Elasticsearch index name:", err) quit() def make_query(filter): index_exists = client.indices.exists(index=INDEX_NAME) # check if the index exists if index_exists == True: print ("INDEX_NAME:", INDEX_NAME, "exists.") print ("FILTER:", filter, "\n") try: # use JSON for literal string arguments #filter = json.loads(filter) # pass filter query to the client's search() method response = client.search(index=INDEX_NAME, body=filter) # print the query response print ('response["hits"]:', len(response["hits"])) print ('response TYPE:', type(response)) # iterate the response hits print ("\nDocument %d hits:" % response['hits']['total']['value']) for hit in response['hits']['hits']: print(hit["_source"]) except Exception as err: print ("search(index) ERROR", err) response = {"error": err} # return an empty dict if index doesn't exist else: response = {} return response def main(): # declare variable for system arguments list sys_args = sys.argv # remove Python script name from args list sys_args.pop(0) # quit the script if there are not exactly 3 arguments if len(sys_args) != 3: print ("Three arguments needed. You provided:", sys_args) print ("First argument is index, and next two are the field and query:", sys_args) quit() else: # get the field name and query value from sys args field_name = sys_args[1] value = sys_args[2] # pass the field name and value args to filter dict filter = { 'query': { 'match': { field_name: value } } } # pass the filter dict to the make_query() function resp = make_query(filter) # have interpreter call the main() func if __name__ == "__main__": main() |

Pilot the ObjectRocket Platform Free!
Try Fully-Managed CockroachDB, Elasticsearch, MongoDB, PostgreSQL (Beta) or Redis.
Get Started