Use Python To Index Files Into Elasticsearch - Index All Files in a Directory (Part 1)
Introduction
One useful feature of Python is its built-in os and glob libraries that allow you to get files in a directory and read their content. This article will show you how to use Python to index files and their content, found using glob, in order to index the data in an Elasticsearch index.
Let’s jump straight in and learn how to use Python to index files into Elasticsearch, specifically indexing all files in a directory.
Prerequisites
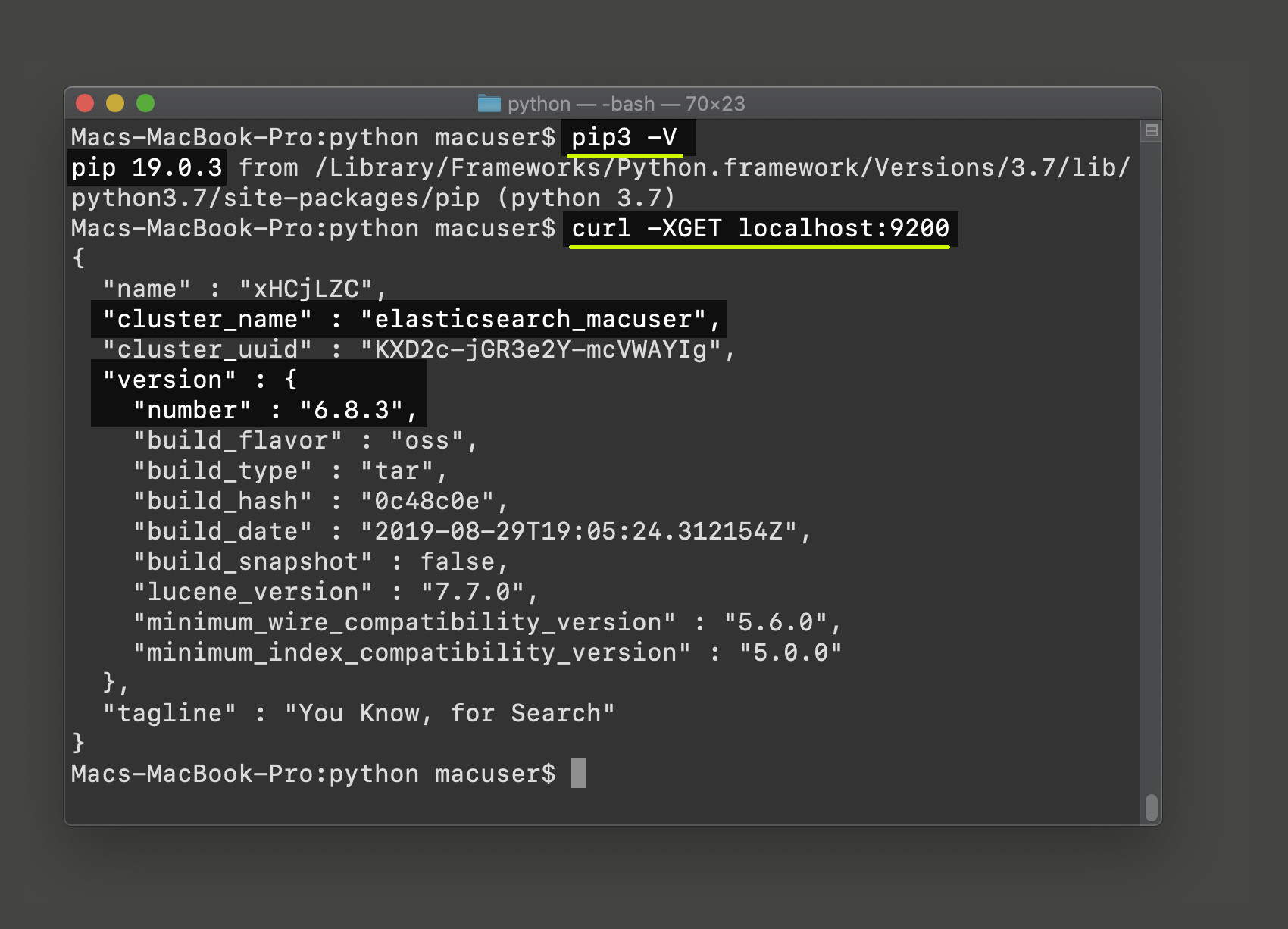
We recommend that you use Python 3.4 or newer since Python 2.7 is now deprecated and losing much of its support by 2020. Use the following commands to check if Python 3, and its PIP package manager, are installed:
1 2 | python3 -V pip3 -V |
Once PIP3 is installed you can use it to install the elasticsearch low-level Python client for Elasticsearch by invoking its install command:
1 | pip3 install elasticsearch |
The Elasticsearch service needs to be running on your server. Use the following cURL request, if you have Elasticsearch running on your machine’s localhost server, to get a cluster response:
1 | curl -XGET localhost:9200 |
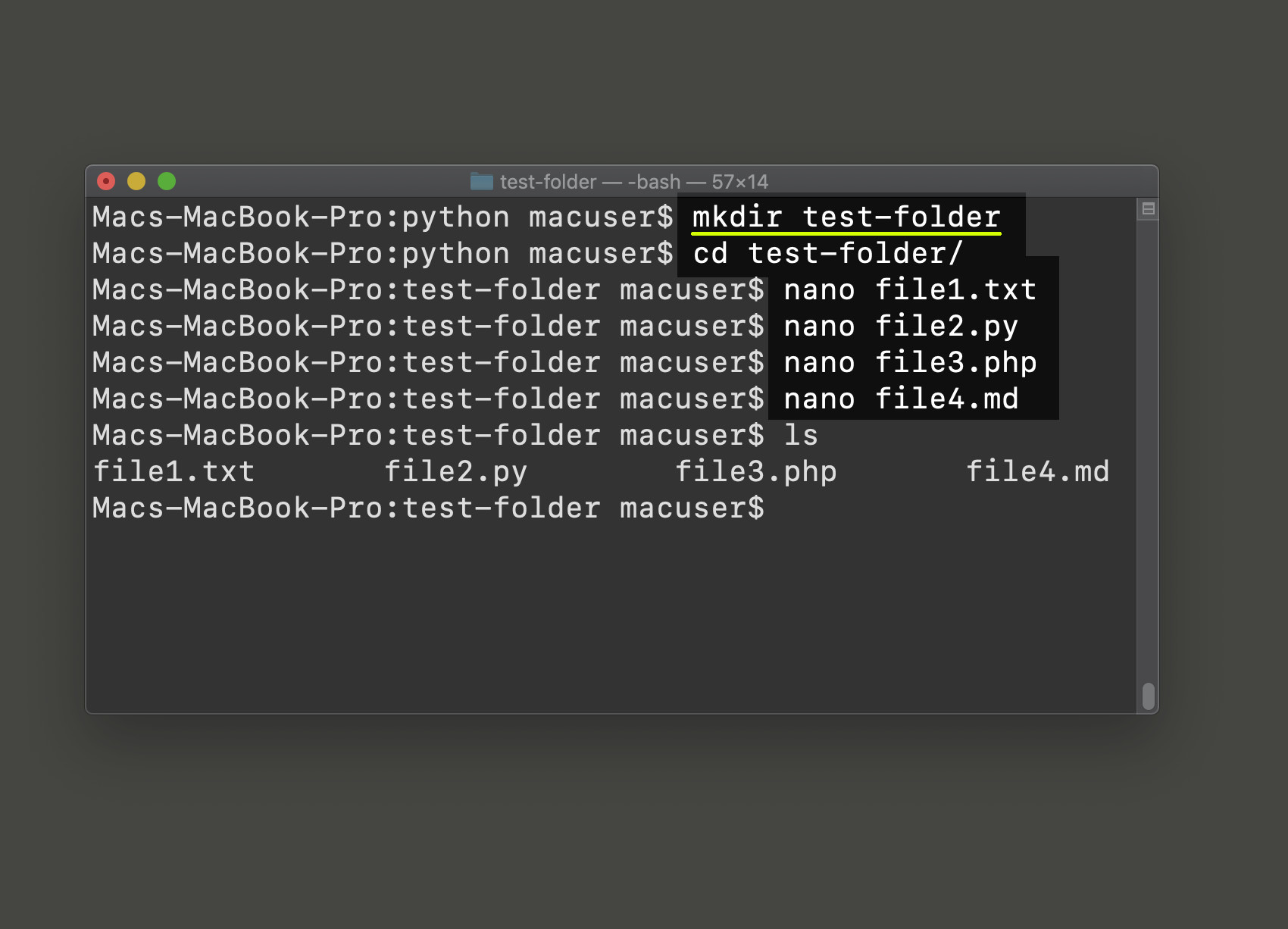
Create some files in a directory to index into Elasticsearch
Create a directory (use the mkdir command in a UNIX-based terminal) at the same location that the Python script will be run, and put some files, with some text in them, into that directory. The code in this article is designed to “crawl” a specific directory for files and it will put each file’s respective content and metadata into an Elasticsearch document’s _source field.
Go into the directory (using the cd command) and use the touch command to create a file, or use a terminal-based editor (like nano or gedit) to create some text files or coding script, and put some content into them.
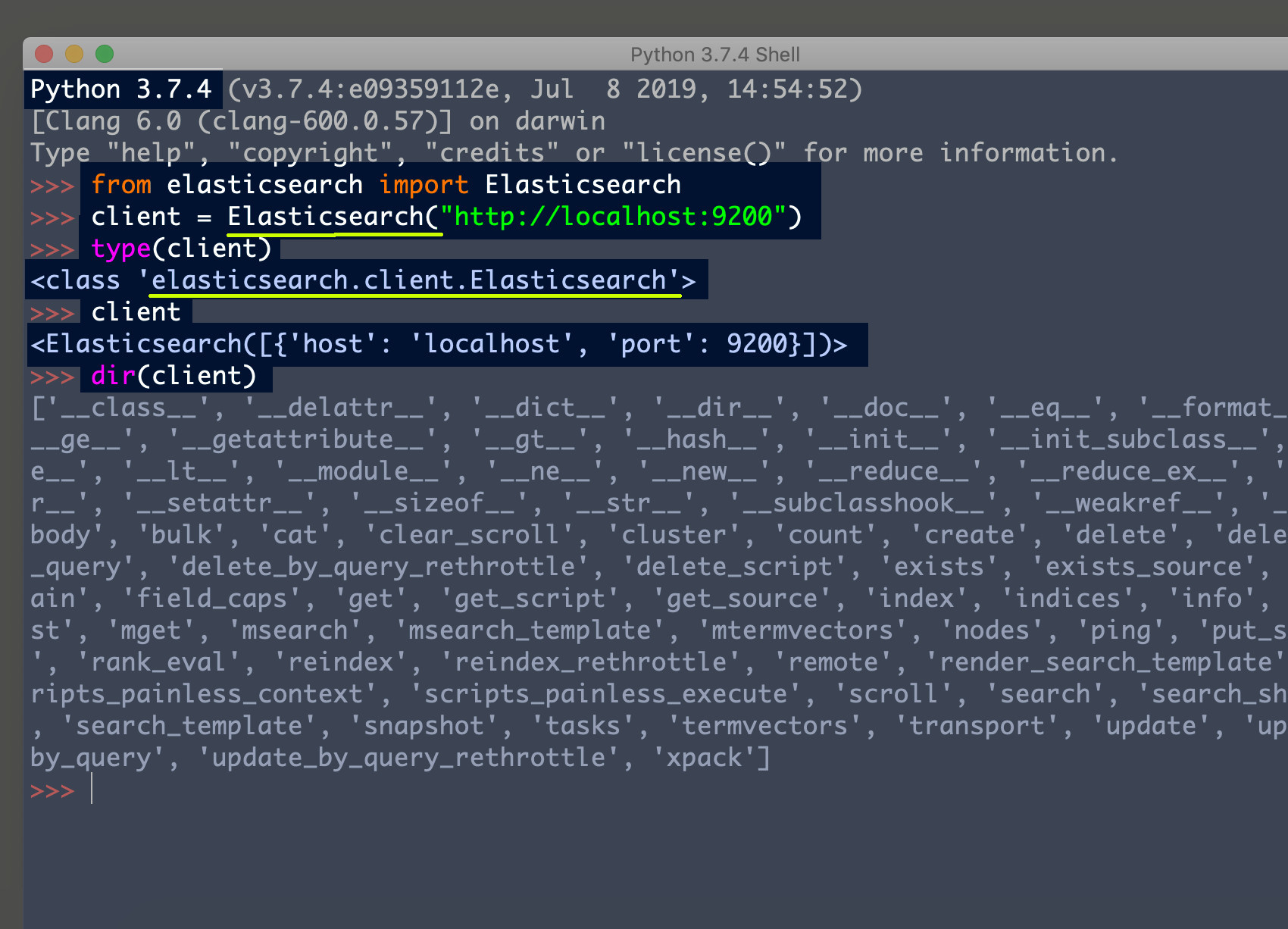
Create a Python script and import Elasticsearch
Either go back into the root directory from earlier (with cd .., or cd.. if you’re using Windows) and create a Python script:
1 | touch index_files.py |
Import Elasticsearch and the Python libraries needed to open files
1 2 3 4 5 6 7 8 | # import Datetime for the document's timestamp from datetime import datetime # import glob and os import os, glob # use the elasticsearch client's helpers class for _bulk API from elasticsearch import Elasticsearch, helpers |
Create an instance of the Elasticsearch low-level Python client
After you’ve imported the libraries you can declare an instance of the Elasticsearch() client by passing your cluster’s domain and port string to the method library and it should return a elasticsearch.client.Elasticsearch object that will allow you to make RESTful API calls to the cluster.
The following code allows you to connect to the Elasticsearch cluster, running on the default port of 9200, in a local web server:
1 2 | # declare a client instance of the Python Elasticsearch library client = Elasticsearch("http://localhost:9200") |
Get the correct ‘slash’ for your operating system
Windows file systems use backslashes whereas Linux, macOS, and all other operating systems use a forward slashes (/). In order to make this Python script operating system “agnostic” you will need to tell Python which slash to use based on the OS running the script.
Python’s os library has a name attribute that returns a string label for the file system type. Both Linux and macOS should return "posix" when you access that attribute.
The following code uses the os.name string to figure out which slash to use:
1 2 3 4 5 | # posix uses "/", and Windows uses "" if os.name == 'posix': slash = "/" # for Linux and macOS else: slash = chr(92) # backslash '\' for Windows |
NOTE: Python’s chr() function returns a character string based on the integer value passed to it, and 92 is the ASCII table number for a backslash character.
Define a function that returns the current directory path
The following code will define a Python function that returns a string of the absolute directory path for the current directory of Python script:
1 2 | def current_path(): return os.path.dirname(os.path.realpath( __file__ )) |
Define a function that returns the file names in a directory
Python’s glob library can be used to crawl for files. The following code defines a Python function that looks for all the files in a specific directory:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | # default path is the script's current dir def get_files_in_dir(self=current_path()): # declare empty list for files file_list = [] # put a slash in dir name if needed if self[-1] != slash: self = self + slash # iterate the files in dir using glob for filename in glob.glob(self + '*.*'): # add each file to the list file_list += [filename] # return the list of filenames return file_list |
NOTE: The wildcard string *.* is appended to the end of the path so that it will find all files. If you’d like to only index a specific type of file then just change that part of the code to *. plus the file extension (e.g. *.php for PHP files).
If no parameter is passed to the function it will search the current directory by default.
Define a function that returns the content of a file
The last function you must define will get all of the contents in the file, line-by-line, and put them in a list.
Sometimes Python will return an encoding error while using the open() method to get data in a file. The code in this function passes an 'ignore' string to the os.open() function’s errors parameter in order to ignore characters with ASCII encoding errors:
1 2 3 4 5 6 7 8 9 10 11 12 13 | def get_data_from_text_file(file): # declare an empty list for the data data = [] # get the data line-by-line using os.open() for line in open(file, encoding="utf8", errors='ignore'): # append each line of data to the list data += [ str(line) ] # return the list of data return data |
Get all of the file names in the directory
The last step is to call the functions to get all of the data. Pass a directory path (relative to the script) to the get_files_in_dir() function call to have it return all of the file names in a Python list object.
Here’s some example code that calls the function to get all of the files in a directory, relative to the Python script, called test-folder, and then prints the total document count:
1 2 3 4 5 | # pass a directory (relative path) to function call all_files = get_files_in_dir("test-folder") # total number of files to index print ("TOTAL FILES:", len( all_files )) |
Conclusion
Make sure to save the code in the Python script and then run it, from the same directory, using the python3 command:
1 | python3 index_files.py |
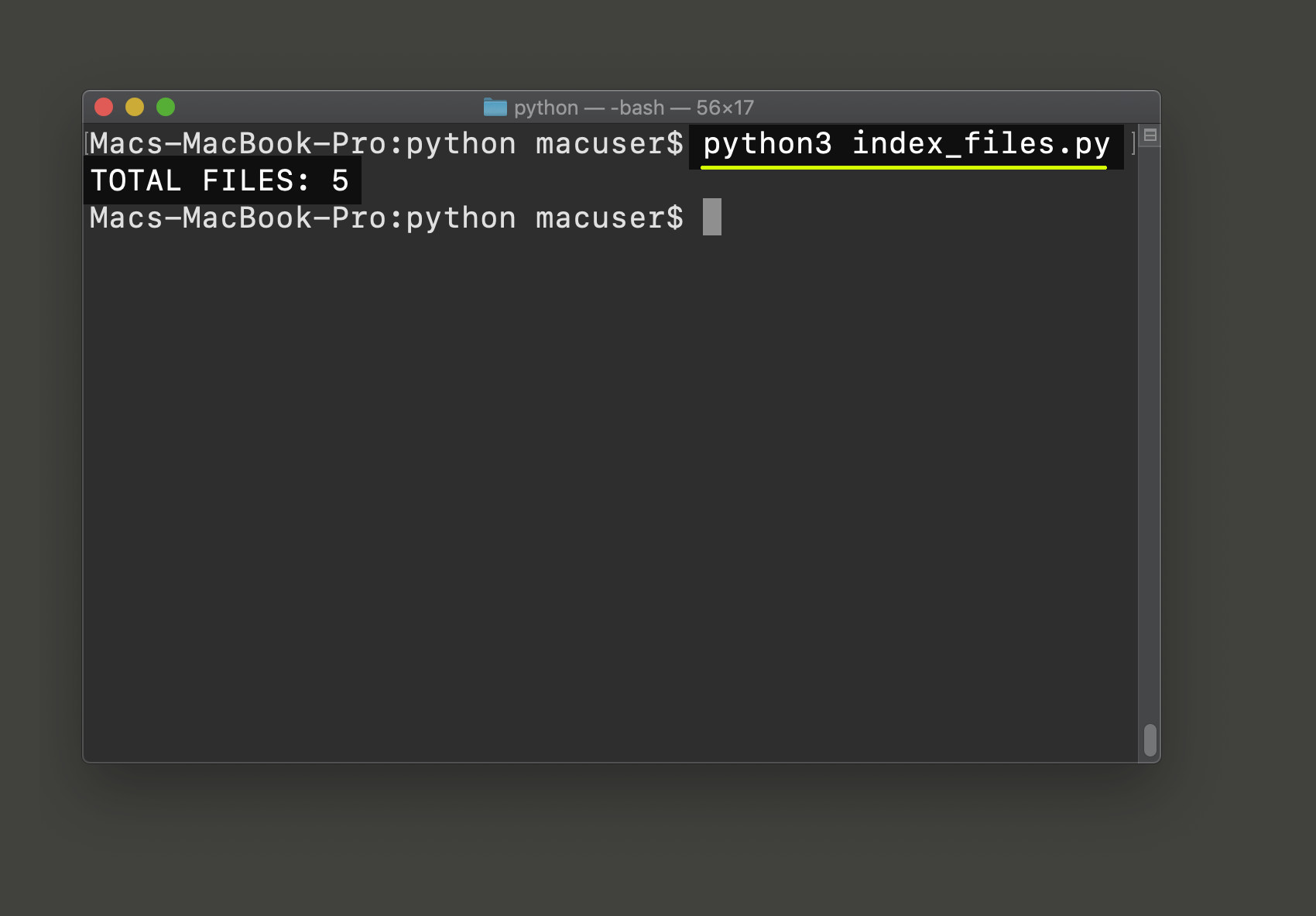
This concludes part one if this series explaining how to index files as Elasticsearch documents. You should now have a good idea of how to find files (using Python’s glob library), and opening them to retrieve their content data. Check out part two of this series to see how to index each file as an Elasticsearch document.
Just the Code
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 | #!/usr/bin/env python3 #-*- coding: utf-8 -*- # import Datetime for the document's timestamp from datetime import datetime # import glob and os import os, glob # use the elasticsearch client's helpers class for _bulk API from elasticsearch import Elasticsearch, helpers # declare a client instance of the Python Elasticsearch library client = Elasticsearch("http://localhost:9200") # posix uses "/", and Windows uses "" if os.name == 'posix': slash = "/" # for Linux and macOS else: slash = chr(92) # '\' for Windows def current_path(): return os.path.dirname(os.path.realpath( __file__ )) # default path is the script's current dir def get_files_in_dir(self=current_path()): # declare empty list for files file_list = [] # put a slash in dir name if needed if self[-1] != slash: self = self + slash # iterate the files in dir using glob for filename in glob.glob(self + '*.*'): # add each file to the list file_list += [filename] # return the list of filenames return file_list def get_data_from_text_file(file): # declare an empty list for the data data = [] # get the data line-by-line using os.open() for line in open(file, encoding="utf8", errors='ignore'): # append each line of data to the list data += [ str(line) ] # return the list of data return data # pass a directory (relative path) to function call all_files = get_files_in_dir("test-folder") # total number of files to index print ("TOTAL FILES:", len( all_files )) |

Pilot the ObjectRocket Platform Free!
Try Fully-Managed CockroachDB, Elasticsearch, MongoDB, PostgreSQL (Beta) or Redis.
Get Started