Use Python To Check If An Elasticsearch Cluster Is Running 657
Introduction
When you use the Python programming language to make an API method call to an Elasticsearch cluster, you’ll want things to go as smooth as possible. To increase your instances of successful connections and reduce returning exceptions, perform these Python check Elasticsearch cluster running verification steps. Follow the training in this tutorial to learn exactly how it’s done.
If you already know the steps and want to skip the details of this tutorial, go to Just the Code.
Prerequisites
- Get Python 3, Elasticsearch’s low-level client (Use PIP3 to install it, then run it.
1 | pip3 install elasticsearch |
Use cURL and make an XGET request
You can check if a cluster in Elasticsearch is running with the integral
requestslibrary. Alternatively, you can use a method of Elasticsearch’s library low-level client.Try this cURL rquest to check if a cluster in Elasticsearch is active.
1 | curl -XGET "localhost:9200" |
- If the cluster is running, you’ll see information returned; otherwise, you’ll see a “failed to connect” response. The latter means it’s not active or the parameters of the port are wrong. A failed connection response will look something like this one here:
1 | curl: (7) Failed to connect to localhost port 9200: Connection timed out |
Connect with the ‘RequestsHttpConnection’ library in Python
- Try to connect using the
RequestsHttpConnectionlibrary of Python’s client.

Get the ‘RequestsHttpConnection’ library’s class attributes
- Access the
RequestsHttpConnectionlibrary’s class attributes like this:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | class RequestsHttpConnection( self, host="localhost", port=9200, http_auth=None, use_ssl=False, verify_certs=True, ssl_show_warn=True, ca_certs=None, client_cert=None, client_key=None, headers=None, cloud_id=None, **kwargs ): |
- You’ll get a
ConnectionTimeout caused by - ReadTimeouterror if the cluster connection didn’t work.
Do a Connection library importation
- Import the
Connectionlibrary packages to verify the cluster and machine or server and address of the port.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | # import the Elasticsearch low-level client and Connection methods from elasticsearch import Elasticsearch, Connection # import JSON library to return a readable string of the Elasticsearch connection responses import json # import the elasticsearch.connection class as an alias import elasticsearch.connection as conn # used to make HTTP requests to the Elasticsearch cluster import requests |
The responses that are returned from the HTTP will confirm if the cluster is running on the indicated port.
We’ll use
conn, short forelasticsearch.connection. It’s brief and simpler to use it. If you don’t want to do that, you can use theperform_request()to make the method call with this script here:
1 | elasticsearch.connection.RequestsHttpConnection.perform_request() |
Make a port value and domain name Elasticsearch string
- Construct an API method call string for the port and domain in Elasticsearch.
1 2 3 4 5 6 7 | # declare global variables for the domain and port domain = "http://localhost" port = 9200 elastic_url = domain + ":" + str(port) |
Test the cluster in Elasticsearch
- A object from the method
RequestsHttpConnection()of theconnectionlibrary in Python will be returned to check the status of the cluster. Test it like this:
1 2 3 4 5 | # instantiate an elasticsearch.connection.http_requests.RequestsHttpConnection object req_conn = conn.RequestsHttpConnection(Connection) print ("RequestsHttpConnection TYPE:", type(req_conn)) |
Modify the port string and the cluster in Elasticsearch
- Make the attribute
base_urlof the connection object the same as the instantiated string completed just a little while ago:
1 2 3 4 5 6 7 | # change the Connection object's base_url to match the cluster domain and port req_conn.base_url = elastic_url # elasticsearch.connection RequestsHttpConnection print ("req_conn.base_url:", req_conn.base_url, "n") |
Call the method perform_request() and set a timeout
Make a
GETrequest to obtain a cluster HTTP response when you pass the object instancereq_conn.Next, set a seconds-based
timeout. Use an integer for the maximum duration of wait time to get a connection to conduct a Python check Elasticsearch cluster running:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | # check the Elasticsearch cluster connection in a try-catch indentation try: # pass the RequestsHttpConnection object to perform_request() method resp = conn.RequestsHttpConnection.perform_request( req_conn, method = "GET", url = "", timeout = 2 # set the timeout to 2 seconds ) |
>NOTE Ten seconds is the default timeout if you don’t set it.
- Elasticsearch’s HTTP response should be a parsable
tuplePython object.
Prepare to parse Elasticsearch’s object that was returned
Three compositions of the tuple response object of the RequetsHTTPConnection connection method. They are:
- Elasticsearch HTTP status code
- A response JSON header
- Status code HTTP
Do a response object tuple iteration and print the results
- Perform an iteration over Elasticsearch’s object tuple elements, and then run a printout.
1 2 3 4 5 6 7 8 9 10 11 12 13 | # print the response object's type() print ("nRequestsHttpConnection response object:", type(resp)) # iterate over the tuple response object elements for i in range(len(resp)): print ("ELE POS:", i) print ("TYPE:", type(resp[i])) print ("DATA:", resp[i], "n") |
- You should see similar to this:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 | RequestsHttpConnection response object: <class 'tuple'="'tuple'"> ELE POS: 0 TYPE: <class 'int'="'int'"> DATA: 200 ELE POS: 1 TYPE: <class 'requests.structures.caseinsensitivedict'="'requests.structures.CaseInsensitiveDict'"> DATA: {'content-type': 'application/json; charset=UTF-8', 'content-length': '505'} ELE POS: 2 TYPE: <class 'str'="'str'"> DATA: { "name" : "Matebook-Mint", "cluster_name" : "elasticsearch", "cluster_uuid" : "8_yW57KYRTq0jZj7ZFilog", "version" : { "number" : "7.2.0", "build_flavor" : "default", "build_type" : "tar", "build_hash" : "508c38a", "build_date" : "2019-06-20T15:54:18.811730Z", "build_snapshot" : false, "lucene_version" : "8.0.0", "minimum_wire_compatibility_version" : "6.8.0", "minimum_index_compatibility_version" : "6.0.0-beta1" }, "tagline" : "You Know, for Search" } |
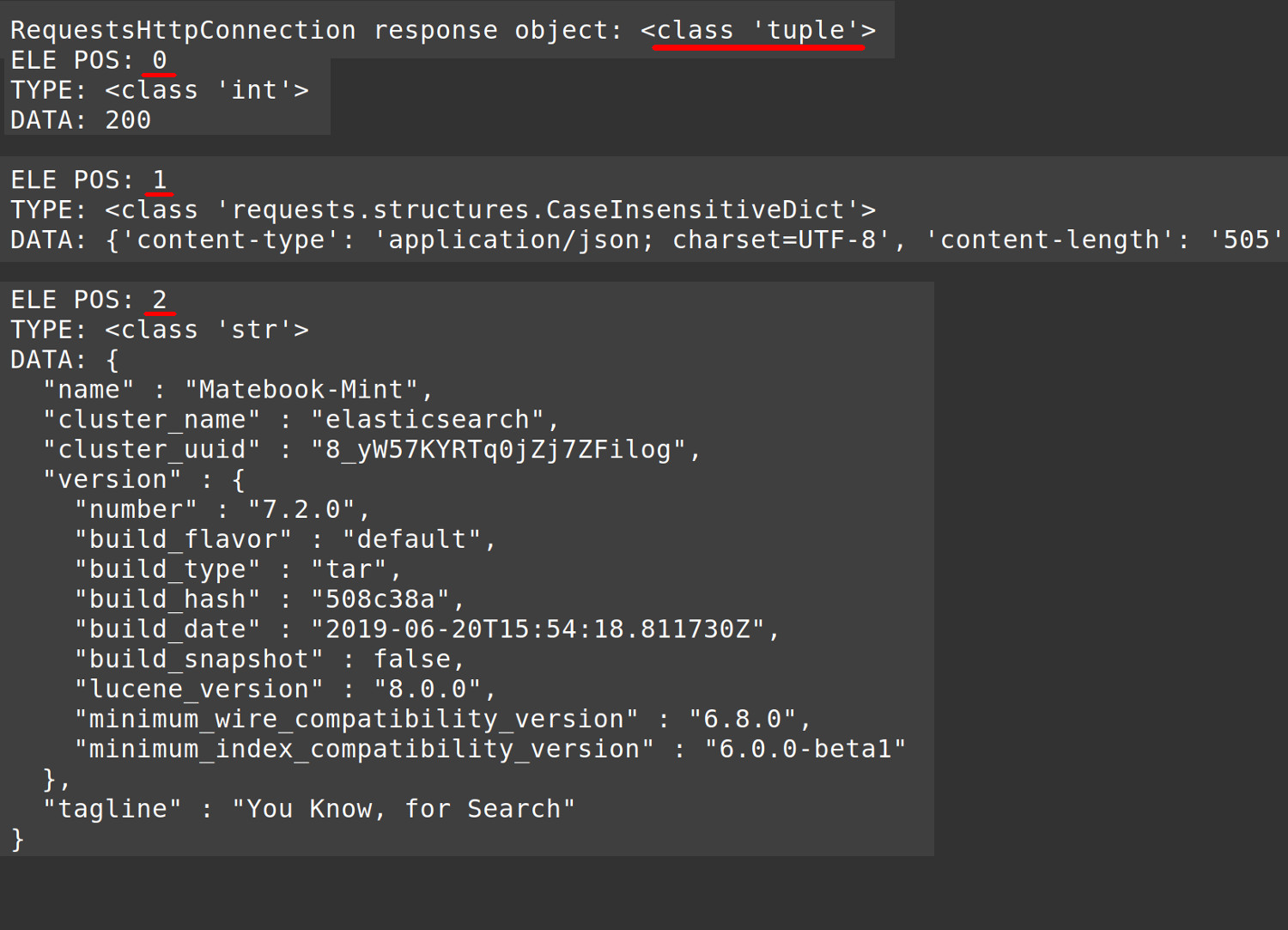
Analyze the response HTTP first element
The status code is the element at the beginning of the tuple response that Elasticsearch returned.
Perform a status code HTTP and header JSON parsing.
- Analyze the request’s status by obtaining the value of the element like this:
1 2 3 | # get the HTTP status code element http_code = resp[0] |
- Retrieve the
dictPython object; however, it’s important to cast theCaseInsensitiveDictof the JSON header first.
1 2 3 4 5 6 7 8 9 10 11 | # explicitly cast the CaseInsensitiveDict JSON header as a dict resp_header = dict(resp[1]) # create JSON dumps() indentation string from dict response json_header = json.dumps(resp_header, indent=4) # print the JSON response returned by the Elasticsearch http_requests library print ("JSON response header:", json_header) |
Verify that 200 is the status code HTTP
- The indented block try-except contains the code. Analyze the parsed integer of the status code HTTP. You’re looking for a 200 response because that means that the connection is ready for more API calls.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | # 200 status code means "OK" if http_code == 200: # cluster is ready to connect print ("Elasticsearch cluster status is OK:", http_code) # Elasticsearch HTTP response did NOT return 200 status code else: # the client object will be 'None' if there's no 200 status code print ("ERROR: The Elasticsearch cluster returned a status of:", http_code) except Exception as err: # print any errors print ("search() ERROR:", err) print (vars(err)) # in the case of Python or API errors set code to "Bad Request" http_code = 400 |
- Anything other than a 200 for the integer of the status code means that the connection didn’t happen.
Make a connection if 200 is the status code HTTP
- Since some information was returned in the case of a 200 HTTP status code when you performed a Python check Elasticsearch cluster running. Now, make an Elasticsearch instance and use it to make additional API method calls.
1 2 3 4 5 6 7 8 9 10 11 12 13 | # check if the library created an Elasticsearch client instance if http_code == 200: # pass URL and declare a client instance of Elasticsearch() client = Elasticsearch(elastic_url) print ("You can now make Elasticsearch API calls to:", client) else: print ("Unable to connect to Elasticsearch at:", elastic_url) |
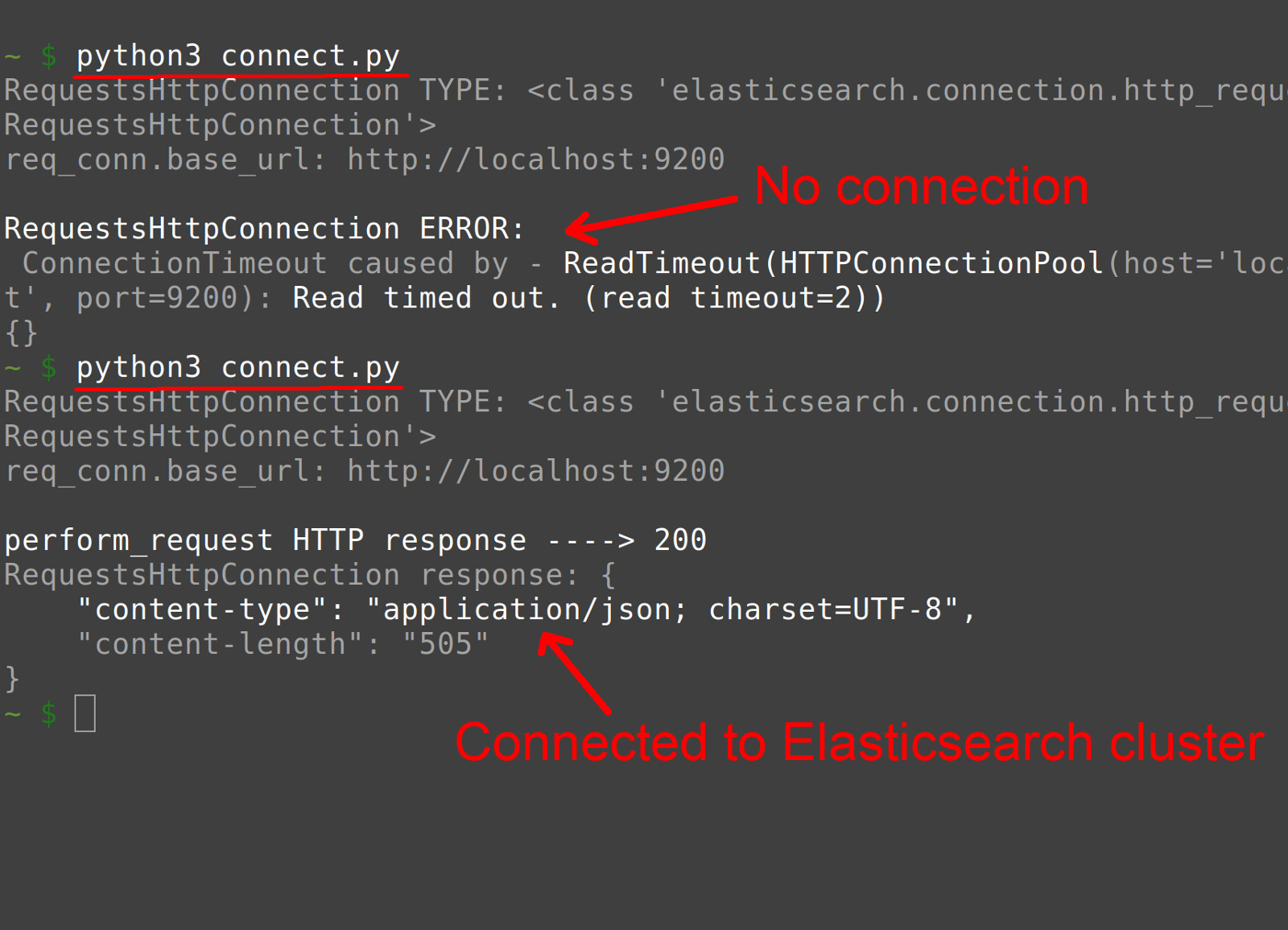
- API method calls are possible when 200 is the status code HTTP. There are no exceptions. Anything other than 200 won’t. Here’s an example of the script output:
1 2 3 4 5 6 7 8 9 10 11 | JSON response header: { "content-type": "application/json; charset=UTF-8", "content-length": "505" } Elasticsearch cluster status is OK: 200 You can now make Elasticsearch API calls to: <elasticsearch([{'host': 'localhost',="'localhost'," 9200}])="9200}])"> |
If an exception was raised, or if the domain or port values are incorrect, or if the Elasticsearch cluster isn’t running properly, then the Python script should print the following:
1 2 3 4 5 6 7 8 9 | RequestsHttpConnection TYPE: <class 'elasticsearch.connection.http_requests.requestshttpconnection'="'elasticsearch.connection.http_requests.RequestsHttpConnection'"> req_conn.base_url: http://localhost:9200 search() ERROR: ConnectionTimeout caused by - ReadTimeout(HTTPConnectionPool(host='localhost', port=9200): Read timed out. (read timeout=2)) {} Unable to connect to Elasticsearch at: http://localhost:9200 |
Conclusion
This tutorial showed you how to Python check Elasticsearch cluster running. You learned different ways of connecting to an Elasticsearch cluster using Python. You also discovered the number of the integer in the status code HTTP that represents a successful connection. Now you can confidently use these steps in all of your Elasticsearch projects.
Just the Code
Here’s the complete sample code for Python check Elasticsearch cluster running.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 | #!/usr/bin/env python3 #-*- coding: utf-8 -*- # import the Elasticsearch low-level client and Connection methods from elasticsearch import Elasticsearch, Connection # import JSON library to return string of Elasticsearch responses import json # import the elasticsearch.connection class as an alias import elasticsearch.connection as conn # used to make HTTP requests to the Elasticsearch cluster import requests # declare global variables for the domain and port domain = "http://localhost" port = 9200 elastic_url = domain + ":" + str(port) # instantiate a elasticsearch.connection.http_requests.RequestsHttpConnection object req_conn = conn.RequestsHttpConnection(Connection) print ("RequestsHttpConnection TYPE:", type(req_conn)) # change the Connection object's base_url to match cluster domain and port req_conn.base_url = elastic_url # elasticsearch.connection RequestsHttpConnection print ("req_conn.base_url:", req_conn.base_url) # check the Elasticsearch cluster connection in a try-catch indentation try: # pass the RequestsHttpConnection object to perform_request() method resp = conn.RequestsHttpConnection.perform_request( req_conn, method = "GET", url="", timeout = 2 ) # print the response object's type() print ("nRequestsHttpConnection response object:", type(resp)) # iterate over the tuple response object for i in range(len(resp)): print ("ELE POS:", i) print ("TYPE:", type(resp[i])) print ("DATA:", resp[i], "n") # get the HTTP status code element http_code = resp[0] # explicitly cast the CaseInsensitiveDict JSON header as a dict resp_header = dict(resp[1]) # create JSON dumps() indentation string from dict response json_header = json.dumps(resp_header, indent=4) # print the JSON response returned by the Elasticsearch http_requests library print ("JSON response header:", json_header) # 200 status code means "OK" if http_code == 200: # cluster is ready to connect print ("Elasticsearch cluster status is OK:", http_code) # Elasticsearch HTTP response did NOT return 200 status code else: # the client object will be 'None' if there's no 200 status code print ("ERROR: The Elasticsearch cluster returned a status of:", http_code) except Exception as err: # print any errors print ("search() ERROR:", err) print (vars(err)) # in the case of Python or API errors set code to "Bad Request" http_code = 400 # check if the library created an Elasticsearch client instance if http_code == 200: # pass URL and declare a client instance of Elasticsearch() client = Elasticsearch(elastic_url) print ("You can now make Elasticsearch API calls to:", client) else: print ("Unable to connect to Elasticsearch at:", elastic_url) |

Pilot the ObjectRocket Platform Free!
Try Fully-Managed CockroachDB, Elasticsearch, MongoDB, PostgreSQL (Beta) or Redis.
Get Started