Parse Elasticsearch Cluster And Index Information Using The Python Client Library
Introduction
Parsing data results in the string information being separated and processed into manageable types of data. The outcome is that the data components are tagged, easily retrieved, and ready to be analyzed in the response results from your queries.
Know that parsing is a process. The Python client library uses the methods indices.stats() and info() to gather general and detailed information on indices.
This tutorial shows you how to parse Elasticsearch cluster index information Python client library in the smoothest way. If you already know the steps on how to parse in Elasticsearch using Python, and want to skip over this tutorial, you can go directly to Just the Code.
Prerequisites
- Install Elasticsearch on your host machine locally or server.
Verify the cluster
Your domain’s default port is
9200. Go there or open a tab in your browser to check that the cluster Elasticsearch is running.Alternatively, to confirm Elasticsearch is active, make a cURL request similar to this one:
1 | curl -XGET localhost:9200 |
NOTE: If you’re using the Secure Socket Shell (SSH) to construct the request and it’s hosted remotely, change the
localhostto the name of your server’s domain.
Use
pip3to install Python 3, the client low-level Elasticsearch for it, or a higher version if one is available. Python 2.7 is out of date and support for it will soon end.Here’s
pip3command to use for the installation:
1 | pip3 install elasticsearch |
- Create an index with a few documents. You’ll use it to test the cluster Elasticsearch API Python examples in this tutorial.
Get ready to test some Python APIs
- You can either experiment using the Python command
idle3, which stands for Integrated Development Environment (IDLE) or typepython3from a window terminal.
Obtain information about a cluster in Elasticsearch
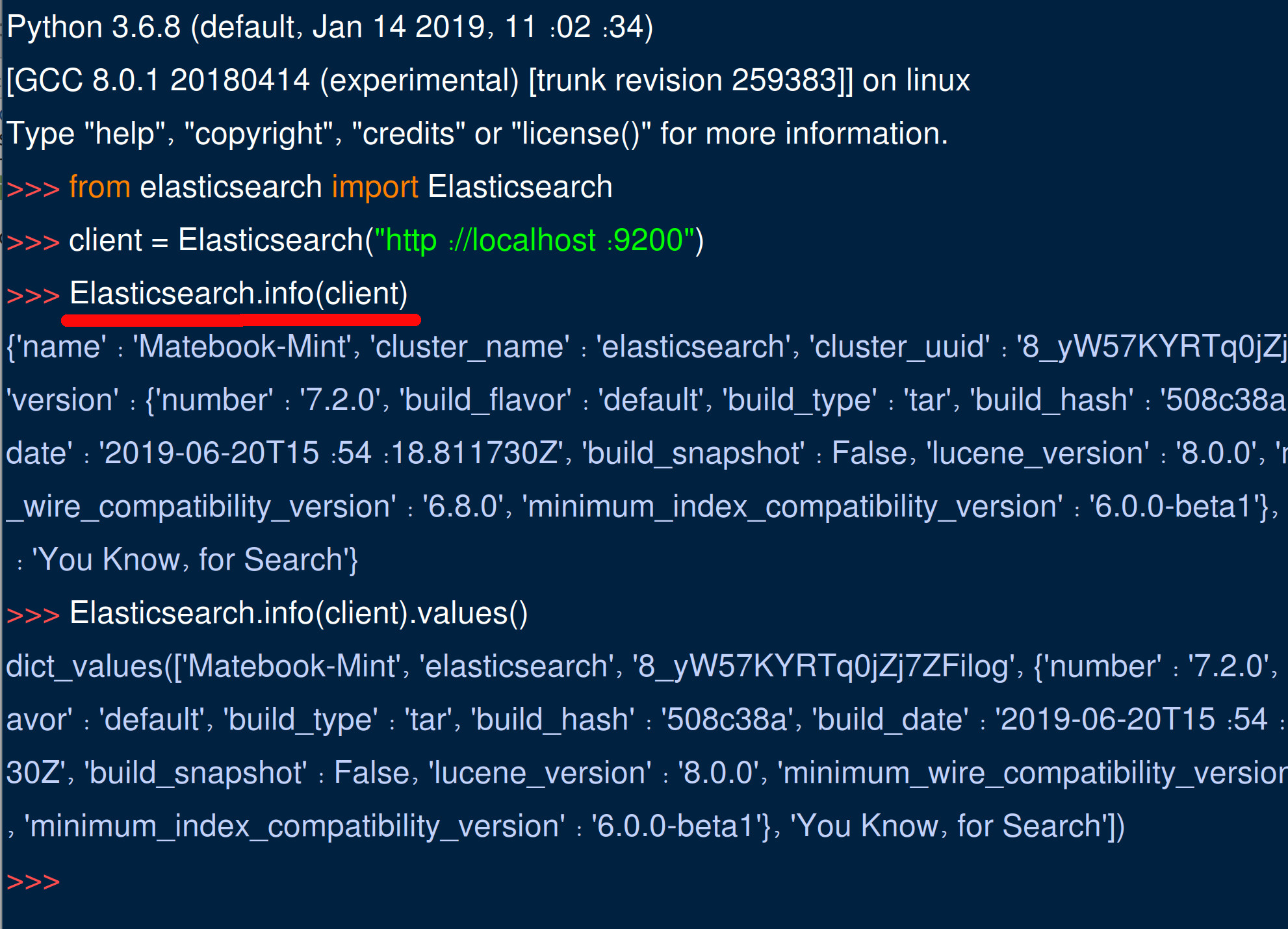
- Import Elasticsearch to test API calls so you can soon parse Elasticsearch cluster index information Python client library.
1 2 3 4 | from elasticsearch import Elasticsearch client = Elasticsearch("http://localhost:9200") Elasticsearch.info(client) Elasticsearch.info(client).values() |
- The response
dictbelow is something similar to what you should see after you make the API request:
1 | {'name': 'Matebook-Mint', 'cluster_name': 'elasticsearch', 'cluster_uuid': '8_yW57KYRTq0jZj7ZFilog', 'version': {'number': '7.2.0', 'build_flavor': 'default', 'build_type': 'tar', 'build_hash': '508c38a', 'build_date': '2019-06-20T15:54:18.811730Z', 'build_snapshot': False, 'lucene_version': '8.0.0', 'minimum_wire_compatibility_version': '6.8.0', 'minimum_index_compatibility_version': '6.0.0-beta1'}, 'tagline': 'You Know, for Search'} |
Get the JSON and Elasticsearch library packages you need for Python
- In order to make successful Elasticsearch cluster API requests, do importation of the library low-level Elasticsearch client and Python’s JSON library:
1 2 3 4 5 | # use the JSON library to prettify Elasticsearch JSON responses import json # import the Elasticsearch client library from elasticsearch import Elasticsearch |
The best way to obtain cluster Elasticsearch data
- An Elasticsearch library client instance is the best way to generate your API requests to gather both index and cluster data. You’ll be able to parse Elasticsearch cluster index information Python client library.
Construct a Python script that has an Elasticsearch library client instance
- Make a declaration of the Elasticsearch library client instance:
1 2 | # declare a client instance of the Python Elasticsearch library client = Elasticsearch("http://localhost:9200") |
Use the method info() to pass the Elasticsearch library client instance
- By the method call
info(), pass the Elasticsearch library client instance. It should return every bit of information on the Elasticsearch cluster.
1 2 | # pass client object to info() method elastic_info = Elasticsearch.info(client) |
Perform a dictionary values information cluster parsing
- There is distinctive information for the cluster on each dictionary key and that data is available for retrieving and parsing.
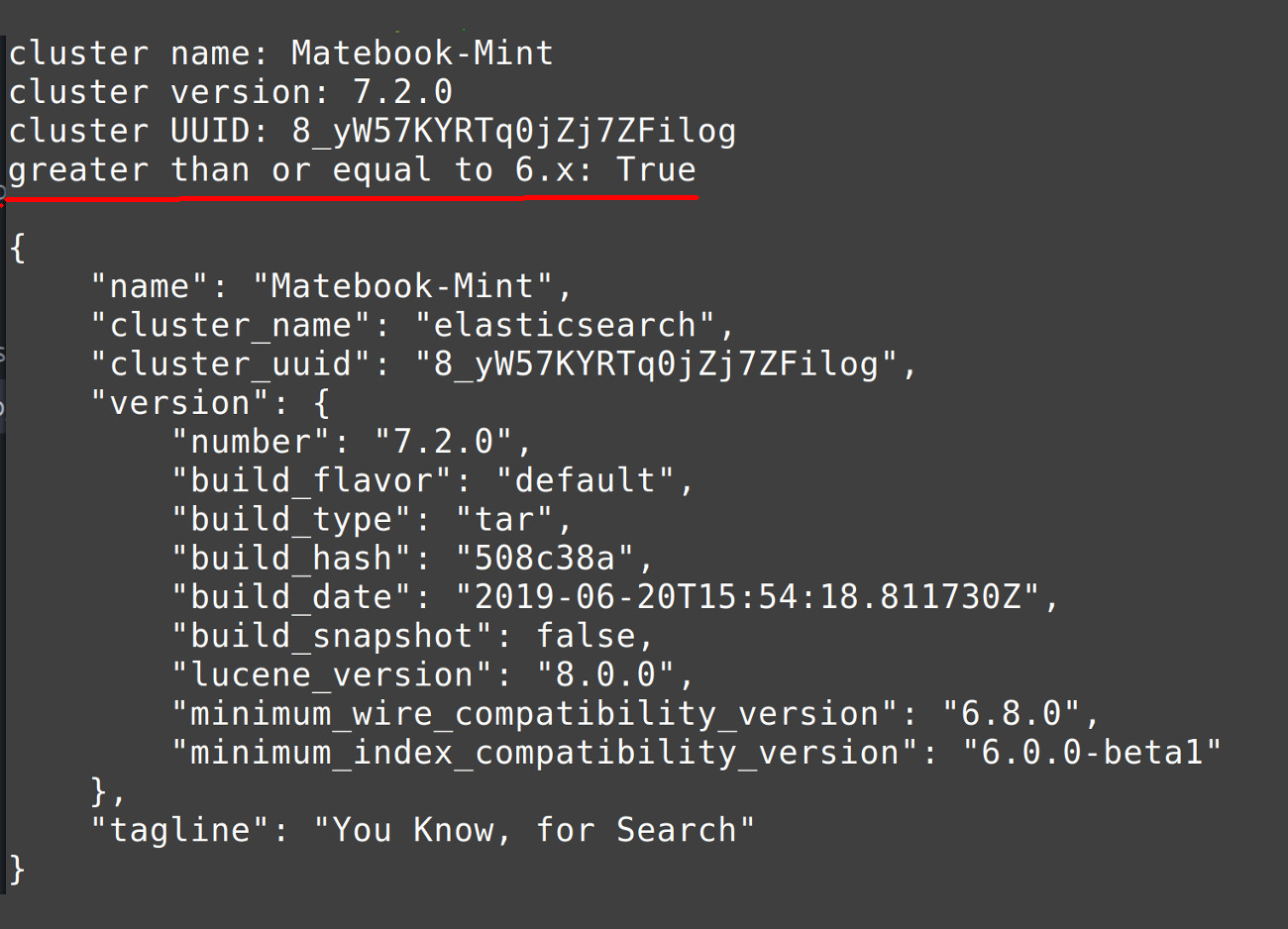
1 2 3 4 5 6 7 | # get the Elasticsearch cluster name cluster_name = elastic_info["name"] print ("cluster name:", cluster_name) # get the Elasticsearch cluster UUID cluster_uuid = elastic_info["cluster_uuid"] print ("cluster UUID:", cluster_uuid) |
Check the version of the Elasticsearch cluster for compatibility
- You can verify the version number of the cluster by conducting a cluster first integer parsing. Find out if the version number is equal to or more than
6:
1 2 3 4 5 6 7 8 9 | # get the Elasticsearch cluster version number cluster_ver = elastic_info["version"]["number"] print ("cluster version:", cluster_ver) # check if the Elasticsearch cluster is >= v6.x first_num = cluster_ver[:cluster_ver.find(".")] # evaluate the version string by type casting with int() print ("greater than or equal to 6.x:", int(first_num) >= 6, "\n") |
- The placement of the character is revealed when you use the function
find().NOTE: The function
int()is inherent. Be sure to make the integer the major version number of the Elasticsearch cluster prior to assessing the character placement.
Print Pretty using library JSON in Python
- The method
dumps()uses the indent parameter to make the Elasticsearch cluster information print prettified.
1 2 3 | # get a pretty print (using json.dumps) of the cluster information info_str = json.dumps(elastic_info, indent=4) print (info_str) |
NOTE: The number of indents named in the parameter
indentmatches the spaces.
Print the object dict_values of the method called values()
- Return the object
dict_valuesof the methodvalues()and print it. You’ll be able to parse and iterate the information on the Elasticsearch cluster:
1 2 3 4 5 6 | # return a dict_values object of the Elasticsearch client values() client_values = Elasticsearch.info(client).values() # return a list of the Elasticsearch client values print ("\n", list(client_values)) print ("client_values TYPE:", type(client_values)) |
Use the function enumerate() for the dict_values iteration
- Python’s convenient function
enumerate()is what you use to perform thedict_values()list iteration:
1 2 3 4 5 6 7 | # iterate the list of Elasticsearch client values for num, val in enumerate(client_values): # only dict objects can be passed to JSON dumps() if type(val) == dict: # pretty print of the Elasticsearch cluster info dict print (json.dumps(val, indent=4)) |
NOTE: With
json.dumps(), if you use any format other than JSON, you’ll raise an exception, specifically aValueErrorone.
Get statistical information on every index of the clusters
The indices of the clusters in Elasticsearch have data that is more comprehensive and you can obtain it through the method indices.stats() from the client instance.
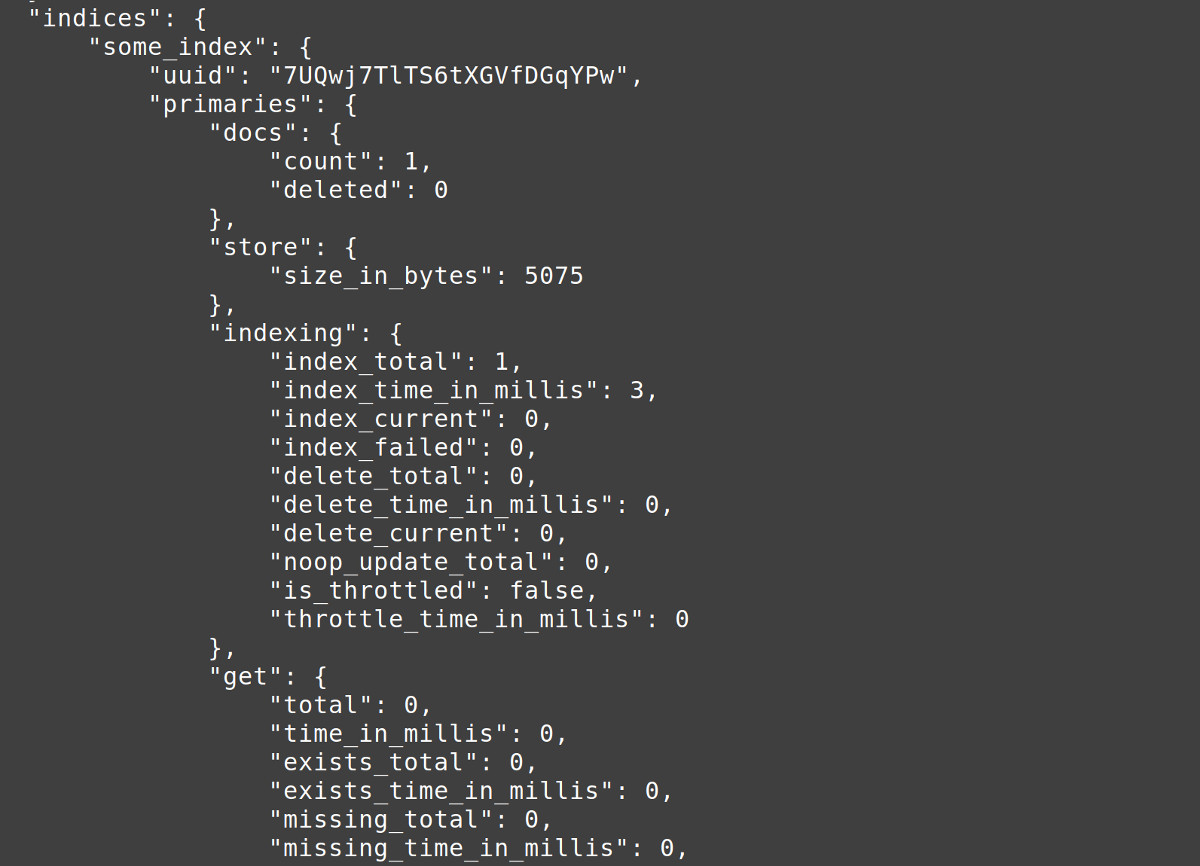
Call the method indices.stats() to return a dictionary Python object
- When you use the
indices.stats()method, you’ll get the specifics of the cluster data in thedict()object. Here’s how:
1 2 3 4 5 6 | # get indices stats information from the client stats = client.indices.stats() # format the stats dictionary and print the information stats_str = json.dumps(stats, indent=4) print ("\n", stats_str) |
Use Python’s ‘json’ library to make the JSON string legible for reading in a terminal window
- The data of the dictionary is converted into more decipherable data by the parameter
indent.
The object called stats allows you to obtain a list of the index names on the Elasticsearch cluster
- Use the method called
keys()to receive the dictionary index keys and make a list of the index names into a recognizable list.
1 2 3 | # get a list of the index names using the stats() dict keys indices = list(stats["indices"].keys()) print ("indices:", indices, "\n") |
Do an index name iteration to retrieve more thorough data all of the indexes on the Elasticsearch cluster
- The fastest way to iterate is with the function
enumerate():
1 2 | # iterate over the list of index names for i, index in enumerate(indices): |
Distinct information for each index can be accessed by using the name of its index
- The index key of each index name allows you to obtain specific data on the index. Print out a list:
1 2 3 4 5 6 7 8 9 | # print the index name for each index print ("\nindex name:", index, "-- num:", i) # print the UUID for each index print (stats["indices"][index]["uuid"]) # print the document count for the index count = stats["indices"][index]["primaries"]["docs"]["count"] print ("doc count:", count) |
Conclusion
This tutorial explained how to parse Elasticsearch cluster index information Python client library. You learned how to access data on each index using the info() and indices.stats methods. The latter gives you more specific information about an index on a cluster in Elasticsearch. The more you know about your stored data, the better it can serve you in improving your productivity in search.
Just the Code
Here’s the complete sample code to parse Elasticsearch cluster index information Python library.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 | #!/usr/bin/env python3 #-*- coding: utf-8 -*- # use the JSON library to prettify Elasticsearch JSON responses import json # import the Elasticsearch client library from elasticsearch import Elasticsearch # declare a client instance of the Python Elasticsearch library client = Elasticsearch("http://localhost:9200") # pass client object to info() method elastic_info = Elasticsearch.info(client) # get the Elasticsearch cluster name cluster_name = elastic_info["name"] print ("cluster name:", cluster_name) # get the Elasticsearch cluster UUID cluster_uuid = elastic_info["cluster_uuid"] print ("cluster UUID:", cluster_uuid) # get the Elasticsearch cluster version number cluster_ver = elastic_info["version"]["number"] print ("cluster version:", cluster_ver) # check if the Elasticsearch cluster is >= v6.x first_num = cluster_ver[:cluster_ver.find(".")] print ("greater than or equal to 6.x:", int(first_num) >= 6, "\n") # get a pretty print (using json.dumps) of the cluster information info_str = json.dumps(elastic_info, indent=4) print (info_str) # return a dict_values object of the Elasticsearch client values() client_values = Elasticsearch.info(client).values() # return a list of the Elasticsearch client values print ("\n", list(client_values)) print ("client_values TYPE:", type(client_values)) # iterate the list of Elasticsearch client values for num, val in enumerate(client_values): # only dict objects can be passed to JSON dumps() if type(val) == dict: # pretty print of the Elasticsearch cluster info dict print (json.dumps(val, indent=4)) # get indices stats information from the client stats = client.indices.stats() # format the stats dictionary and print the information stats_str = json.dumps(stats, indent=4) print ("\n", stats_str) # get a list of the index names using the stats() dict keys indices = list(stats["indices"].keys()) # evaluate the version string by type casting with int() print ("indices:", indices, "\n") # iterate over the list of index names for i, index in enumerate(indices): # print the index name for each index print ("\nindex name:", index, "-- num:", i) # print the UUID for each index print (stats["indices"][index]["uuid"]) # print the document count for the index count = stats["indices"][index]["primaries"]["docs"]["count"] print ("doc count:", count) |

Pilot the ObjectRocket Platform Free!
Try Fully-Managed CockroachDB, Elasticsearch, MongoDB, PostgreSQL (Beta) or Redis.
Get Started