Make Curl Requests To Elasticsearch Using Python
Introduction
If you’re using Elasticsearch to store data, you know that making cURL requests is a common way to communicate with your Elasticsearch cluster. Python’s requests library can be used to make cURL requests to an Elasticsearch cluster, making it easy to communicate with Elasticsearch from a Python script. In this step-by-step tutorial, we’ll explain how to make cURL requests to Elasticsearch in Python.
Prerequisites
Before we attempt to make any curl requests in Python, it’s important to make sure certain prerequisites are in place. For this task, a few key system requirements include:
You’ll need to have an Elasticsearch cluster running. The examples shown in this article work best with Elasticsearch version 6.0 or newer.
Python must be installed on the system or server where the Elasticsearch cluster is running. The examples in this article were written with Python 3 in mind, as Python 2 is scheduled for deprecation.
It’s helpful to have some experience with Python syntax and be somewhat familiar with structuring and creating cURL requests.
The
elasticsearchPython library for the low-level Elasticsearch client must be installed for Python.
Install the Python modules for Elasticsearch and Requests
If you don’t already have the elasticsearch and requests modules installed, you’ll need to use Python’s PIP package manager to install them before proceeding:
Python 3 uses the command pip3 to install PIP packages:
1 2 | pip3 install elasticsearch pip3 install requests |
If you’re running Python 2, simply use pip to install them:
1 2 | pip install elasticsearch pip install requests |
Create the Python script used to make cURL requests
Once the necessary modules have been installed, create a directory if you haven’t done so already. You’ll also need to create a Python script that will be used to make the cURL requests. You can name them whatever you want, but our example will feature a directory named elastic-python and a script named curl_python.py:
1 2 | sudo mkdir elastic-python sudo touch curl_python.py |
Set up the Python script and import the Elasticsearch and Requests libraries:
Now it’s time to edit the Python script that you’ve just created. You can do this using the terminal-based text editor nano:
1 | sudo nano curl_python.py |
At the beginning of the script, you can add the line shown below to guide the system’s interpreter to the correct Python $PATH:
1 2 | #!/usr/bin/env python3 #-*- coding: utf-8 -*- |
Next, we’ll import a few Python libraries needed to make the requests:
1 2 3 4 5 6 | from elasticsearch import Elasticsearch import logging # for debugging purposes import requests # import 'json' to convert strings to JSON format import json |
If you’d like to debug the cURL requests made to Elasticsearch, you can use the http.client module (or httplib in Python 2). This module returns useful information about cURL requests, such as the header used and the HTTP response code from the request:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | # import the correct library depending on the Python version try: # Python 2 import httplib as http_client except (ImportError, ModuleNotFoundError) as error: # Python 3 print ("Python 3: Importing http.client:", error, '\n') import http.client as http_client # set the debug level http_client.HTTPConnection.debuglevel = 1 # initialize the logging to have the debugger return information logging.basicConfig() logging.getLogger().setLevel(logging.DEBUG) # store the DEBUG information in a 'requests_log' variable requests_log = logging.getLogger("requests.packages.urllib3") requests_log.setLevel(logging.DEBUG) requests_log.propagate = True |
The basic structure of a Requests call to Elasticsearch
Before we look at the next section of code, let’s take a moment to discuss the basic structure of a requests call to Elasticsearch. The method called from the Python requests class will depend on which HTTP verb is used. For example, you can make a GET request by calling requests.get() and a POST request by calling the requests.post() method, and so on.
Calling a method of Python’s Requests class:
1 2 3 4 5 6 7 8 9 10 11 | ''' make this Elasticsearch cURL request in Python: curl -XGET localhost:9200/_cat/indices?v ''' # use a Python tuple to pass header options to the request call param = (('v', ''),) # '-v' is for --verbose # call the class's method to get an HTTP response model resp = requests.get('http://localhost:9200/_cat/indices', params=param) # the call will return a `requests.models.Response` object |
After adding the code shown above, save the script, and then execute it in a terminal using the command python3 (if the elasticsearch module was installed using pip3), or the python command for Python 2:
1 | python3 curl_python.py |
NOTE: For Python 2 use: python curl_python.py
Running the script will produce the same result as making the following cURL request:
1 | curl -XGET localhost:9200/_cat/indices?v |
Print the HTTP response from the Requests call:
With just a few more lines of code in your script, you can print out the HTTP response returned from the Elasticsearch cluster:
1 2 3 | print ('\nHTTP code:', resp.status_code, '-- response:', resp, '\n') print ('dir:', dir(resp), '\n') print ('response text:', resp.text) |
Save the script again after adding this code, and run it in a terminal a second time. The response you receive should return information about the Elasticsearch cluster’s indices:
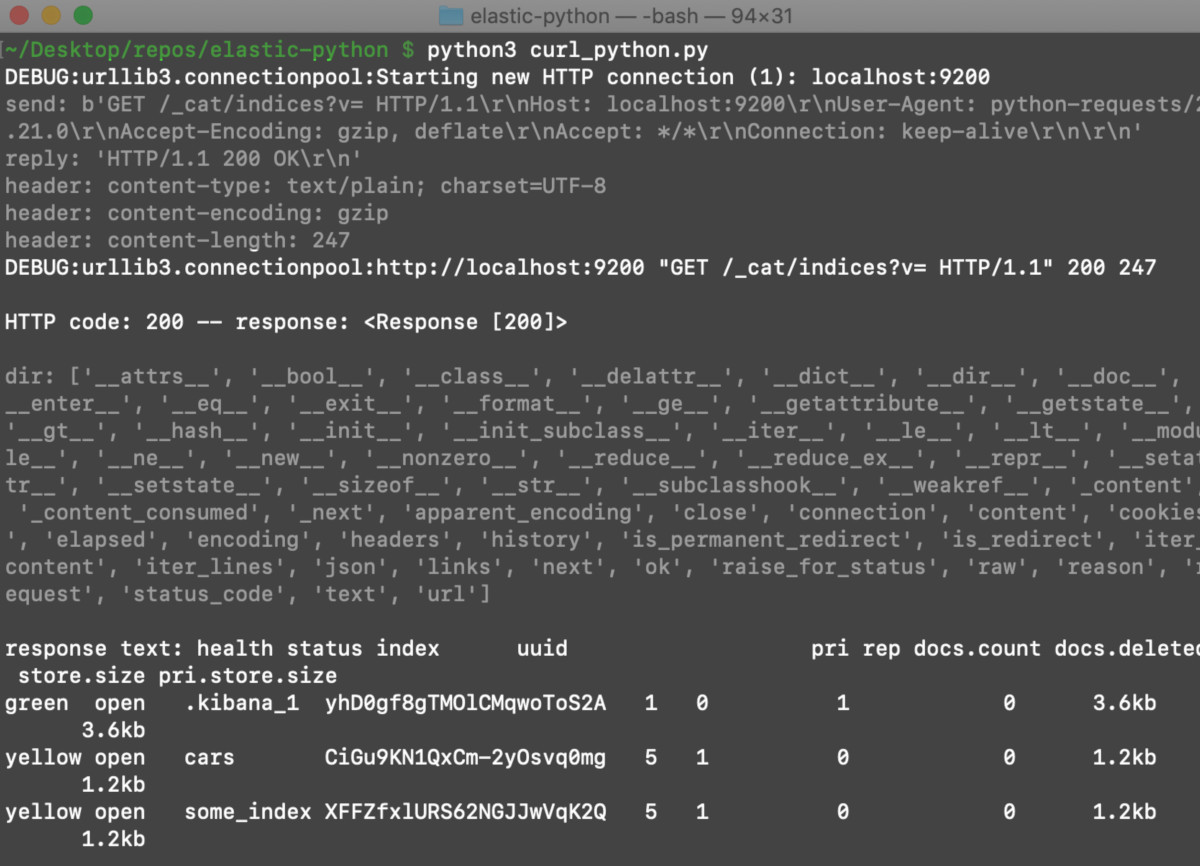
Create a Python function that makes cURL requests to Elasticsearch
Now that we understand the basics of the requests library, we can use it to create a function that’s designed with Elasticsearch in mind.
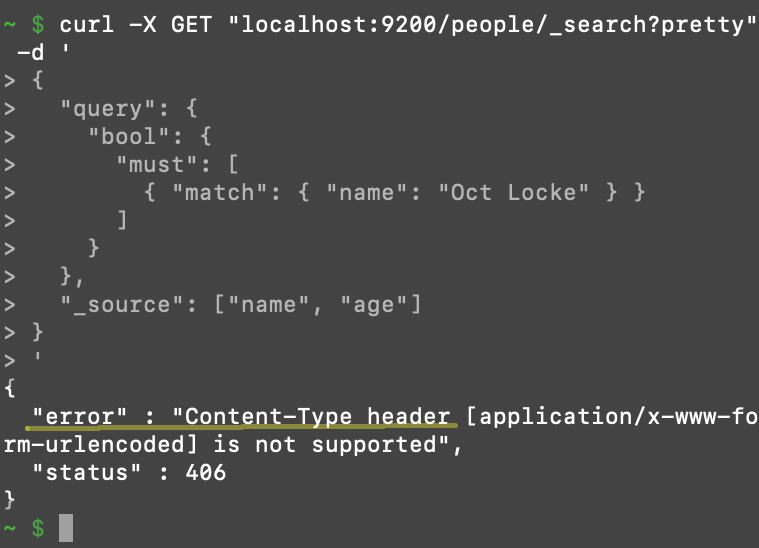
Avoid getting a 406 Content-Type error:
Elasticsearch requires that a header option be explicitly passed that specifies the request’s body type. For Elasticsearch requests, the body type will always be “JSON”.
In the Python request class, you can pass this header option as a parameter called header when making a request:
1 | requests.get(uri, data=query, headers='content-type:application/json') |
406 Content-Type error after making a query request to Elasticsearch that’s missing content-type:application/json in the request’s header:
Define a Python function for Elasticsearch cURL requests:
Here, we define a function to simplify calls made to the Requests class for Elasticsearch cURL requests. To be safe, the default HTTP verb is GET to avoid making unwanted changes to the Elasticsearch cluster:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | # function for the cURL requests def elasticsearch_curl(uri='http://localhost:9200/', json_body='', verb='get'): # pass header option for content type if request has a # body to avoid Content-Type error in Elasticsearch v6.0 headers = { 'Content-Type': 'application/json', } try: # make HTTP verb parameter case-insensitive by converting to lower() if verb.lower() == "get": resp = requests.get(uri, headers=headers, data=json_body) elif verb.lower() == "post": resp = requests.post(uri, headers=headers, data=json_body) elif verb.lower() == "put": resp = requests.put(uri, headers=headers, data=json_body) # read the text object string try: resp_text = json.loads(resp.text) except: resp_text = resp.text # catch exceptions and print errors to terminal except Exception as error: print ('\nelasticsearch_curl() error:', error) resp_text = error # return the Python dict of the request print ("resp_text:", resp_text) return resp_text |
This function breaks down all of the method calls for the request class and streamlines it in one call that uses more simplified parameters.
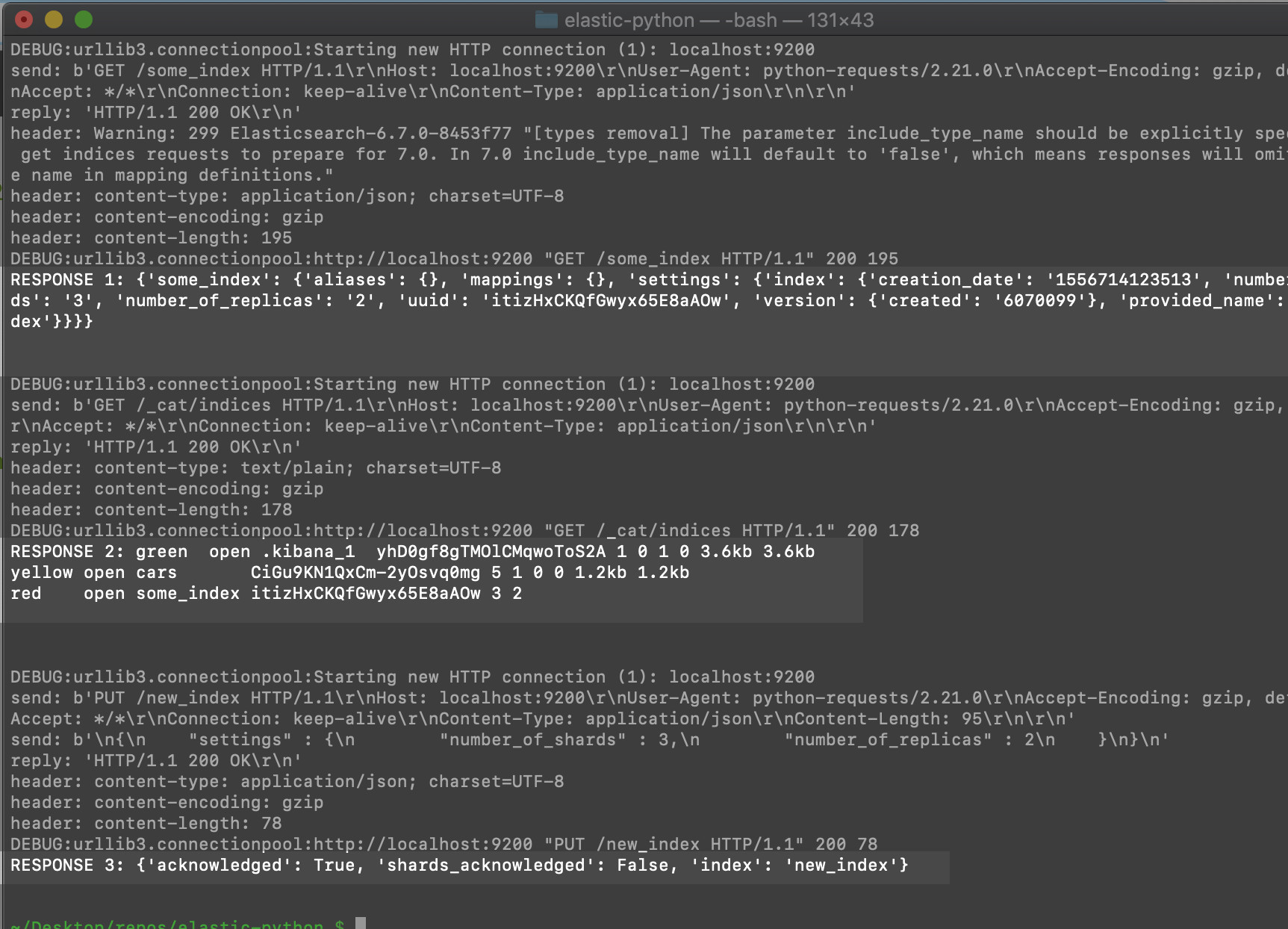
Here are a few examples that call the function to make cURL requests to the Elasticsearch cluster:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | print ('\n') response = elasticsearch_curl('http://localhost:9200/some_index') print ('RESPONSE 1:', response, '\n\n') response = elasticsearch_curl('http://localhost:9200/_cat/indices') print ('RESPONSE 2:', response, '\n\n') request_body = ''' { "settings" : { "number_of_shards" : 3, "number_of_replicas" : 2 } } ''' response = elasticsearch_curl( 'http://localhost:9200/new_index', verb='put', json_body=request_body ) print ('RESPONSE 3:', response, '\n\n') |
Conclusion
Making cURL requests to an Elasticsearch cluster is a simple and efficient way to communicate with Elasticsearch from a script. Python’s requests library can help automate the process of making cURL requests, which also results in cleaner, simpler code. With the step-by-step instructions included in this article, you’ll have no trouble making cURL requests to Elasticsearch using a Python script.
In this article, we looked at the example code one section at a time. Here’s the complete Python script, which includes the elasticsearch_curl() function, for making cURL requests to Elasticsearch:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 | #!/usr/bin/env python3 #-*- coding: utf-8 -*- # import the Elasticsearch client library from elasticsearch import Elasticsearch # for debugging purposes import logging # used to make HTTP requests to the Elasticsearch cluster import requests # import 'json' to convert strings to JSON format import json # catch import errors that arise from breaking version # changes from Python 2 and 3 try: # try Python 2 import httplib as http_client except (ImportError, ModuleNotFoundError) as error: # try Python 3 print ("Python 3: Importing http.client:", error, '\n') import http.client as http_client # set the debug level http_client.HTTPConnection.debuglevel = 1 # initialize the logging to have the debugger return information logging.basicConfig() logging.getLogger().setLevel(logging.DEBUG) # store the DEBUG information in a 'requests_log' variable requests_log = logging.getLogger("requests.packages.urllib3") requests_log.setLevel(logging.DEBUG) requests_log.propagate = True ''' make this Elasticsearch cURL request in Python: curl -XGET localhost:9200/_cat/indices?v ''' # use a Python tuple to pass header options to the request call param = (('v', ''),) # '-v' is for --verbose # call the class's method to get an HTTP response model resp = requests.get('http://localhost:9200/_cat/indices', params=param) # the call will return a `requests.models.Response` object print ('\nHTTP code:', resp.status_code, '-- response:', resp, '\n') print ('dir:', dir(resp), '\n') print ('response text:', resp.text) # function for the cURL requests def elasticsearch_curl(uri='http://localhost:9200/', json_body='', verb='get'): # pass header option for content type if request has a # body to avoid Content-Type error in Elasticsearch v6.0 headers = { 'Content-Type': 'application/json', } try: # make HTTP verb parameter case-insensitive by converting to lower() if verb.lower() == "get": resp = requests.get(uri, headers=headers, data=json_body) elif verb.lower() == "post": resp = requests.post(uri, headers=headers, data=json_body) elif verb.lower() == "put": resp = requests.put(uri, headers=headers, data=json_body) # read the text object string try: resp_text = json.loads(resp.text) except: resp_text = resp.text # catch exceptions and print errors to terminal except Exception as error: print ('\nelasticsearch_curl() error:', error) resp_text = error # return the Python dict of the request print ("resp_text:", resp_text) return resp_text print ('\n') response = elasticsearch_curl('http://localhost:9200/some_index') print ('RESPONSE 1:', response, '\n\n') response = elasticsearch_curl('http://localhost:9200/_cat/indices') print ('RESPONSE 2:', response, '\n\n') request_body = ''' { "settings" : { "number_of_shards" : 3, "number_of_replicas" : 2 } } ''' response = elasticsearch_curl( 'http://localhost:9200/new_index', verb='put', json_body=request_body ) print ('RESPONSE 3:', response, '\n\n') |


Pilot the ObjectRocket Platform Free!
Try Fully-Managed CockroachDB, Elasticsearch, MongoDB, PostgreSQL (Beta) or Redis.
Get Started