How To Use Python's JSON Library In Elasticsearch
Introduction
If you’re working with Python and Elasticsearch, it’s important to make sure you’ve lined up all the tools you need to get the job done efficiently. One key tool is Python’s JSON library. This built-in JSON library seamlessly converts Python dict (dictionary) type objects into JSON strings and vice versa, making it easy to pass data to Elasticsearch in the correct format. In this article, we’ll show you how to use the Python JSON library with Elasticsearch in your scripts. We’ll use Python to declare an Elasticsearch document as a Python dictionary. then convert that dictionary into a JSON string that can be passed to the Elasticsearch client’s API method calls.
Prerequisites
Let’s take a quick look at some key prerequisites that need to be taken care of before we can proceed with our task:
Make sure Python 3 is installed and working. Although Python 2.7 may still work for the code example in this article, this version of Python is deprecated and will ultimately lose support.
The PIP3 package manager for Python also needs to be installed on the Elasticsearch cluster that’s running the Python script. We’ll be using PIP3 to install the Elasticsearch client for Python:
1 | pip3 install elasticsearch |
- You’ll need to have some basic knowledge of Python and its syntax. We’ll cover some of Python’s keywords and functions, and the terminology and concepts may be confusing to a beginner Pythonista.
Create a Python script in the Elasticsearch project directory
Now that we’ve covered the prerequisites, let’s start working on our Python script. Navigate to the directory for your Elasticsearch project (use mkdir to create a new directory if needed):
1 | cd elasticsearch-project |
Use the touch command to create a Python script:
1 | touch elastic_json.py |
The new Python file should now be in your project directory. You can use a terminal-based editor such as vim, nano, or gedit; however, it’s best to use an IDE that supports Python indentation and syntax locally. This will help you avoid frustrating syntax or indentation errors.
Import the Python package libraries for JSON and Elasticsearch
The first thing we’ll do in our script is import the necessary libraries to avoid receiving an ImportError when calling a library’s attribute or method. Here are the libraries we’ll need:
1 2 3 4 5 6 7 8 | # import the built-in Python JSON library import json # import Datetime for the document's timestamp from datetime import datetime # import the Elasticsearch low-level client library from elasticsearch import Elasticsearch |
NOTE: The json library is native to Python 3; therefore, it doesn’t need to be installed with pip3. However, it still needs to be imported before you’re able to use it.
Get familiar with Python’s JSON library before using it with Elasticsearch
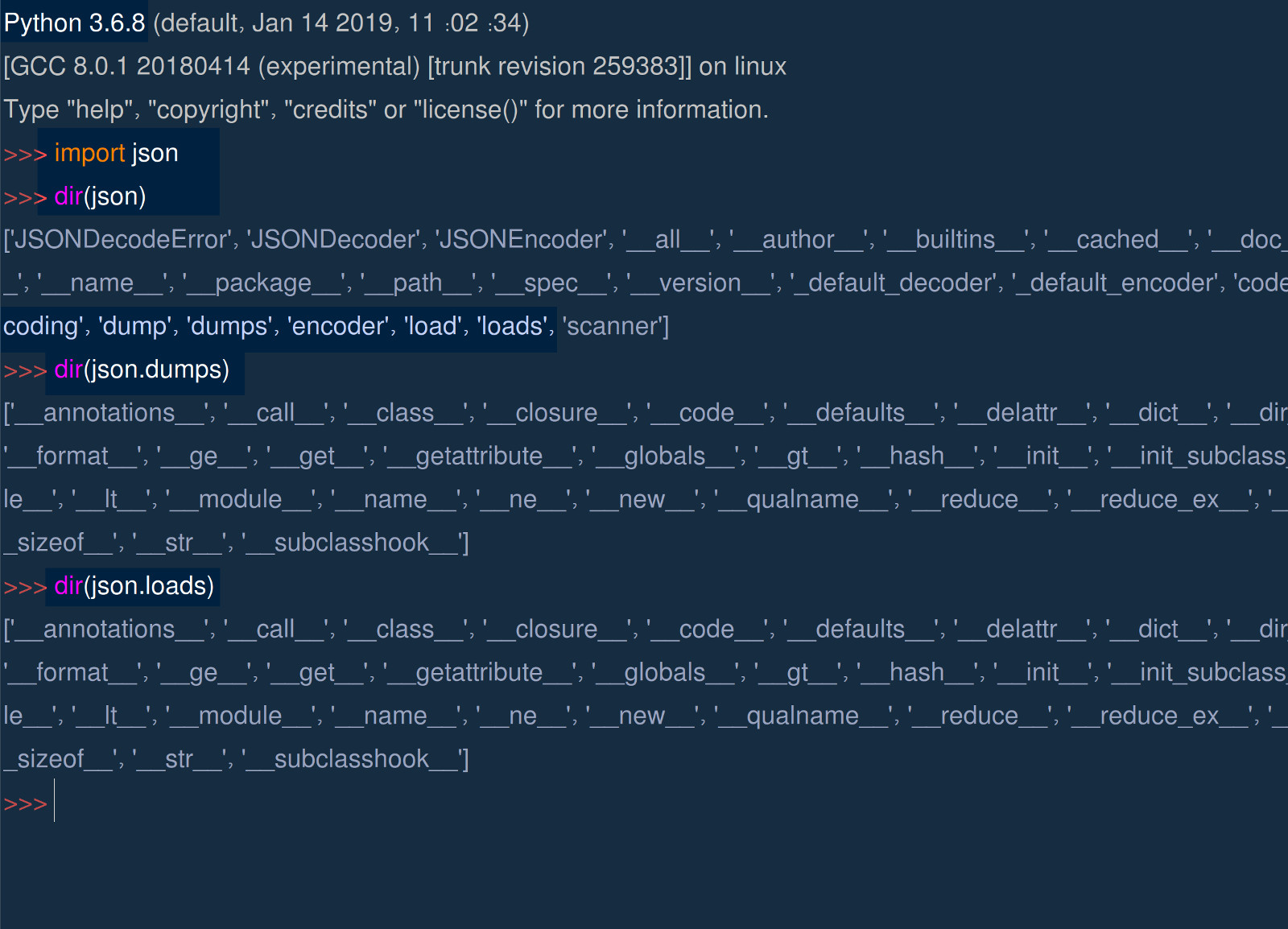
Before digging in to the code and trying to use the Python JSON library with Elasticsearch, it’s a good idea to play around with the JSON library and check out its attributes. You can type python3 in a terminal to use a Python interpreter or idle3 to use the IDLE Python environment. Two methods to take a closer look at are loads() and dumps():
1 2 3 4 | import json dir(json) dir(json.loads) dir(json.dumps) |
Python’s dir() function can be very useful for getting more attribute information about a particular package, library or method in Python.
When you call the json.dumps() method, it returns a JSON string of whatever Python dictionary was passed to it, but it will throw a ValueError if the JSON object is not valid. This is a great way to catch potential JSON errors before the data gets passed to Elasticsearch. Conversely, the json.loads() method will take a valid JSON string and return a Python dictionary.
Catch JSON errors using a try-except error handling block in Python
You can use Python to catch errors using its try-except indentation block. Let’s check out an example of an invalid JSON string being passed to json.loads(). This will raise a ValueError inside of the try-except block:
1 2 3 4 5 6 7 8 9 | # here's an example of an invalid JSON string bad_json = '{"this is": "missing the closing bracket"' # json.loads() will throw a ValueError if JSON is invalid try: json.loads(bad_json) except ValueError as error: print ("Error type:", type(error)) print ("json.loads() ValueError for JSON object:", error) |
Build an Elasticsearch JSON document with key-value pairs in a Python dictionary
Much like a JSON object, a Python dictionary is simply a set of key-value pairs. One dictionary can also be nested inside another dictionary value. Let’s look at an example of how we can build a nested Elasticsearch document in Python. In our example, we’ll build this nested document by passing the document’s _source data, in the form of a Python dict object, to the value of another dictionary’s object’s key. If this sounds a bit confusing, there’s no need to worry– it will become much clearer as we look at the code.
Declare a Python dictionary for the Elasticsearch document’s _source data
Notice that this example uses several different data types for its document fields and uses Python’s datetime library to create a valid timestamp:
1 2 3 4 5 6 7 8 | # _source data for the Elasticsearch document doc_source = { "string field": "Object Rocket articles", "integer field": 42, "boolean field": False, # must be string for JSON seralization "timestamp": str(datetime.now()) } |
NOTE: The datetime timestamp must be explicitly cast as a string; if not, the JSON library’s dumps() method will throw a TypeError:
1 | TypeError: Object of type 'datetime' is not JSON serializable |
Declare the Elasticsearch Python dictionary by nesting the _source data inside it
1 2 3 4 5 6 7 | # Elasticsearch document structure as a Python dict doc = { "_index": "some_index", "_id": 12345, "doc_type": "_doc", # doc type deprecated "_source": doc_source, } |
Create a JSON string of the Python dictionary using json.loads()
You can use the indent parameter to specify the number of spaces for each indentation in the JSON object. This serves to “prettify” the string, making it easier to read:
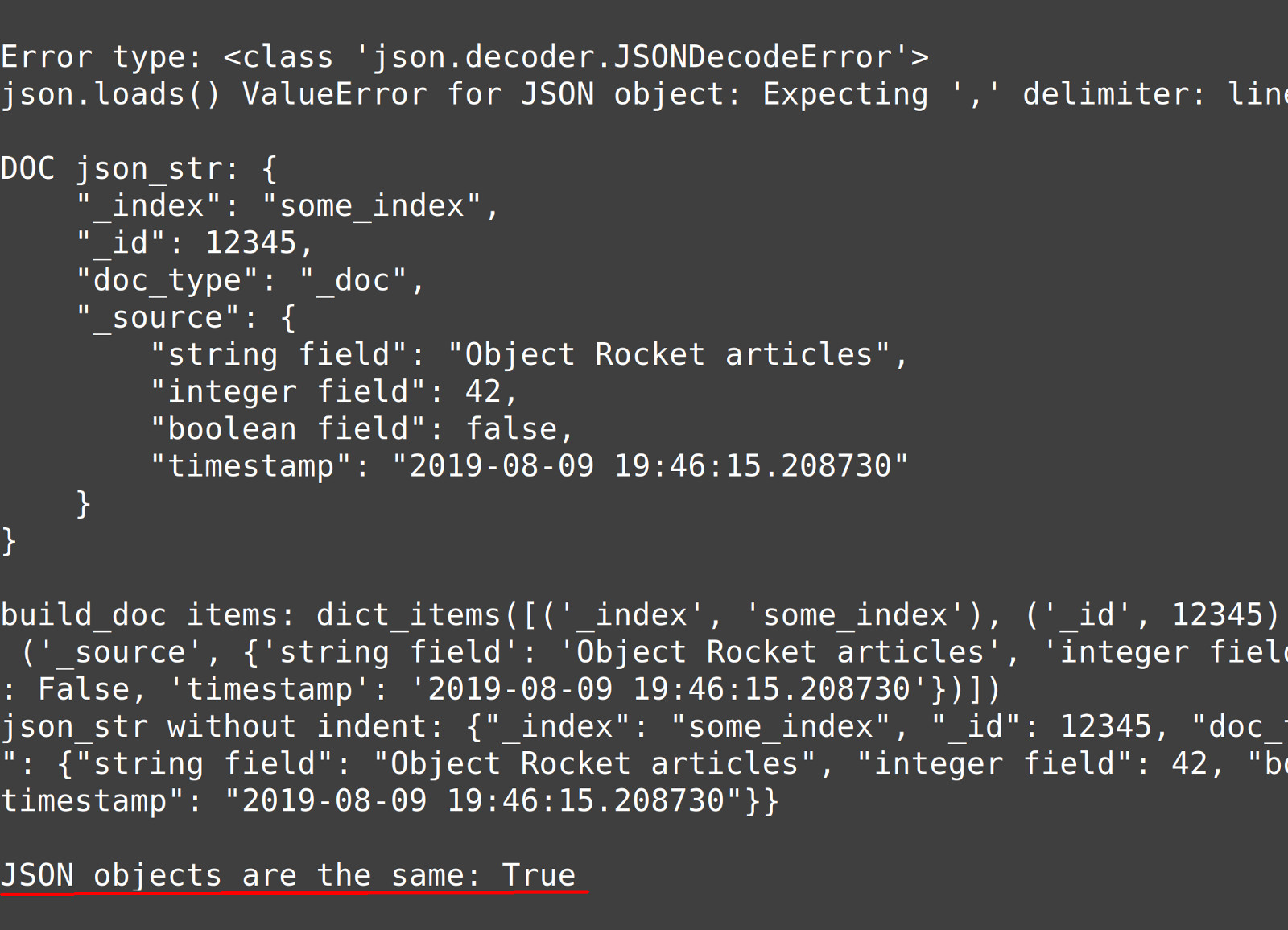
1 2 3 | # use the 'indent' parameter with json.dumps() for more readable JSON json_str = json.dumps(doc, indent=4) print ("\nDOC json_str:", json_str) |
Build an Elasticsearch JSON document from a simple Python dictionary
At this point, we’re ready to prepare the JSON document that we’ll be passing to the Elasticsearch client. This document will be built from our Python dictionary object:
1 2 3 4 5 6 7 8 9 10 11 | # build the Elasticsearch document from a dict build_doc = {} build_doc["_index"] = "some_index" build_doc["_id"] = 12345 build_doc["doc_type"] = "_doc" # doc type deprecated build_doc["_source"] = doc_source # print the mapping print ("\nbuild_doc items:", build_doc.items()) json_str = json.dumps(build_doc) print ("json_str without indent:", json_str) |
Compare the two JSON document dictionary objects in Python
1 2 | # compare this with the previous JSON dict print ("\nJSON objects are the same:", build_doc == doc) |
Create a JSON string of the Elasticsearch document dictionary and make an API call
Here, we create our JSON string using json.dumps() and make sure it doesn’t raise any errors:
1 2 3 4 5 6 | try: # create JSON string of doc _source data json_source = json.dumps(build_doc["_source"]) # get the dict object's _id json_id = build_doc["_id"] |
Finally, we make an API call to index this document in Elasticsearch:
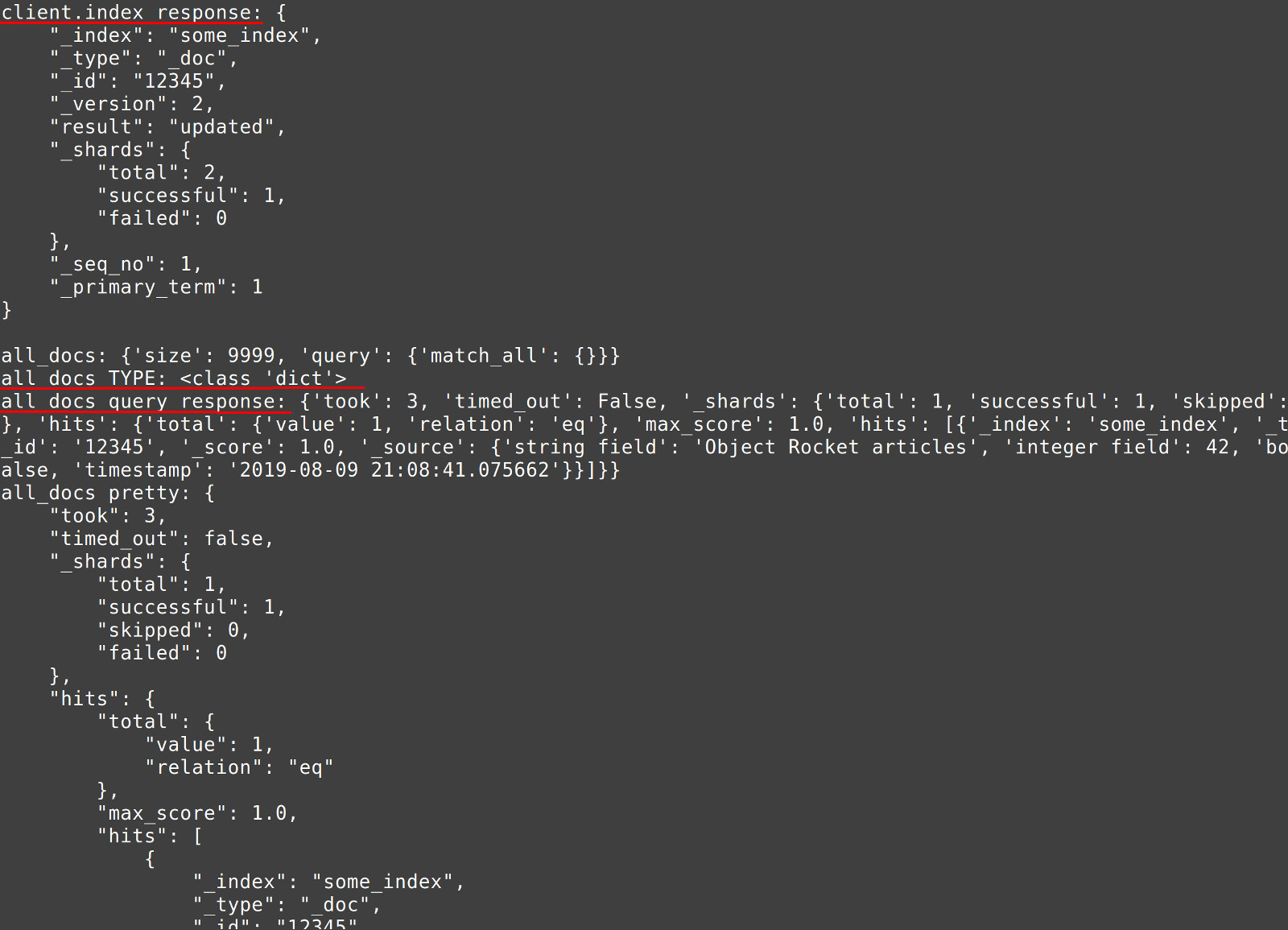
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | # make an API call to the Elasticsearch cluster response = client.index( index = 'some_index', doc_type = '_doc', id = json_id, body = json_source ) # print a pretty response to the index() method call response print ("\nclient.index response:", json.dumps(response, indent=4)) except Exception as error: print ("Error type:", type(error)) print ("client.index() ERROR:", error) |
Create a JSON Elasticsearch query using a Python dictionary
1 2 3 4 5 6 | # build a JSON Python dict to query all documents in an Elasticsearch index all_docs = {} all_docs["size"] = 9999 all_docs["query"] = {"match_all" : {}} print ("\nall_docs:", all_docs) print ("all_docs TYPE:", type(all_docs)) |
Pass the Python dictionary
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | # validate the JSON format using the loads() method try: # pass the JSON string in an API call to the Elasticsearch cluster response = client.search( index = "some_index", body = all_docs ) # print all of the documents in the Elasticsearch index print ("all_docs query response:", response) # use the dumps() method's 'indent' parameter to print a pretty response print ("all_docs pretty:", json.dumps(response, indent=4)) except Exception as error: print ("Error type:", type(error)) print ("client.search() ValueError for JSON object:", error) |
Conclusion
It’s clear that using the Python JSON library with Elasticsearch can make your development tasks easier and more efficient. Now that we’ve finished creating our script, all we need to do is run it. You can run the Python script using the python3 command followed by the file name in a terminal or command prompt window. Be sure to specify the path or navigate to the location of the Python script when you execute the script.
At the end of your terminal output, you should see something like the following:
1 2 3 4 | ... all_docs: {'size': 9999, 'query': {'match_all': {}}} all_docs TYPE: <class 'dict'> all_docs query response: {'took': 3, 'timed_out': False, '_shards': {'total': 1, 'successful': 1, 'skipped': 0, 'failed': 0}, 'hits': {'total': {'value': 1, 'relation': 'eq'}, 'max_score': 1.0, 'hits': [{'_index': 'some_index', '_type': '_doc', '_id': '12345', '_score': 1.0, '_source': {'string field': 'Object Rocket articles', 'integer field': 42, 'boolean field': False, 'timestamp': '2019-08-09 21:08:41.075662'}}]}} |



Pilot the ObjectRocket Platform Free!
Try Fully-Managed CockroachDB, Elasticsearch, MongoDB, PostgreSQL (Beta) or Redis.
Get Started