How to use Python to Make Scroll Queries to Get All Documents in an Elasticsearch Index
Introduction
This tutorial will explain how to use the Search and Scroll API feature for Python to scroll queries for all documents in an Elasticsearch index using the Python low-level client library. The Scroll API feature is a useful function for making document requests in smaller batches, such as in the case of indices with large documents or indices with high volumes of documents. Elasticsearch currently has a maximum limit of 10,000 documents that can be returned with a single request.
Prerequisites for Executing the Search and Scroll API feature for Python to scroll queries for all documents in an Elasticsearch index using the Python low-level client library
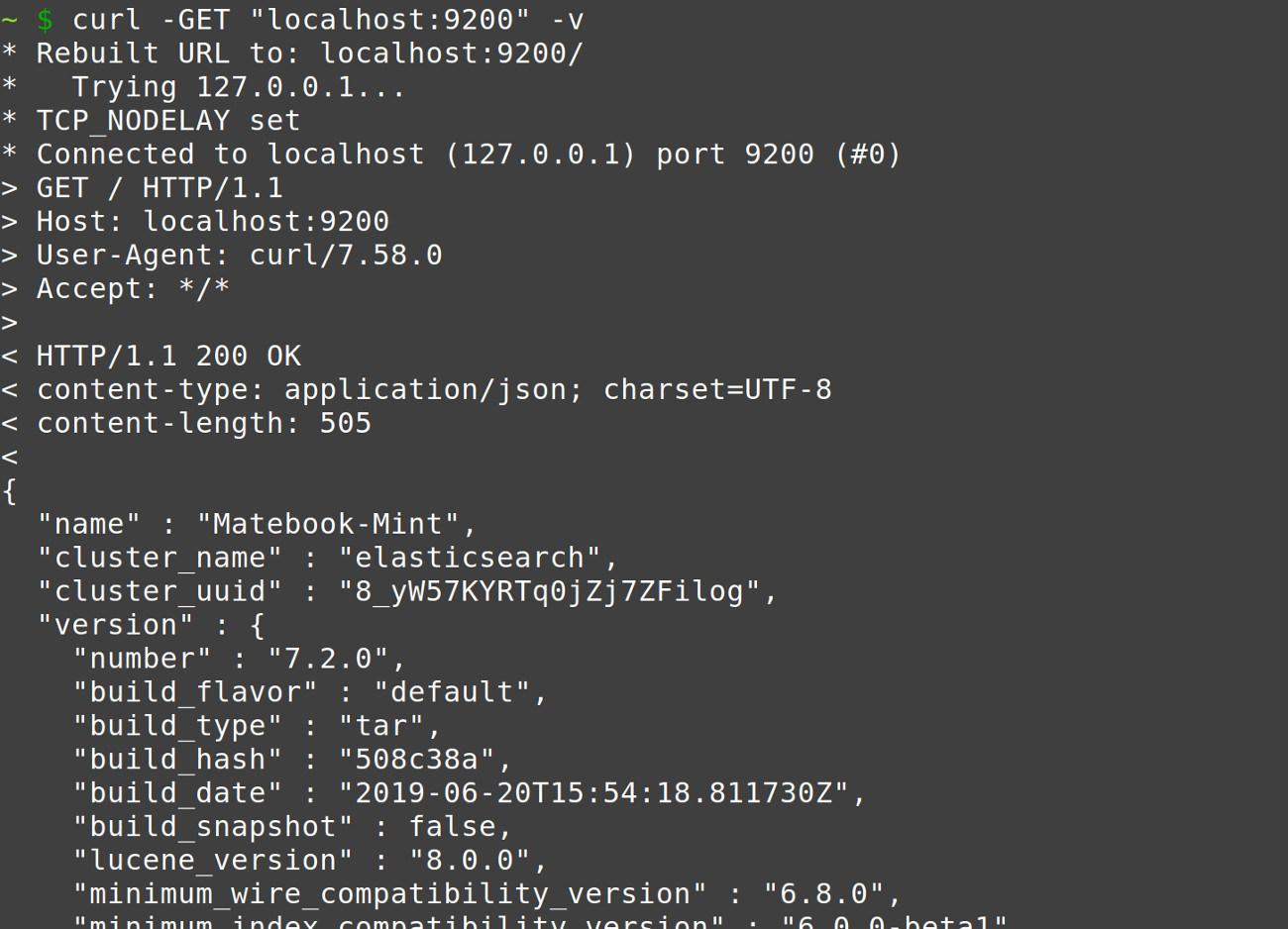
- An Elasticsearch cluster must be installed and running. Execute the following a cURL request to the domain and port of the Elasticsearch cluster to verify it is running:
1 | curl -GET "localhost:9200" -v |
The results should resemble the following:
Documents in at least one index to test the API queries covered in this tutorial.
It is recommended that Python 3 be used, instead of Python 2.7, as Python 2 is now deprecated with its End of Life (EOL) date scheduled for January 2020.
- If the
Elasticsearchclient library for Python 3 is not installed, the PIP3 package manager for Python 3 must be properly installed and working. Typepip3 listto get a list of all currently-installed packages. Install the low-level client Elasticsearch distribution for Python 3 with PIP3:
1 | pip3 install elasticsearch |
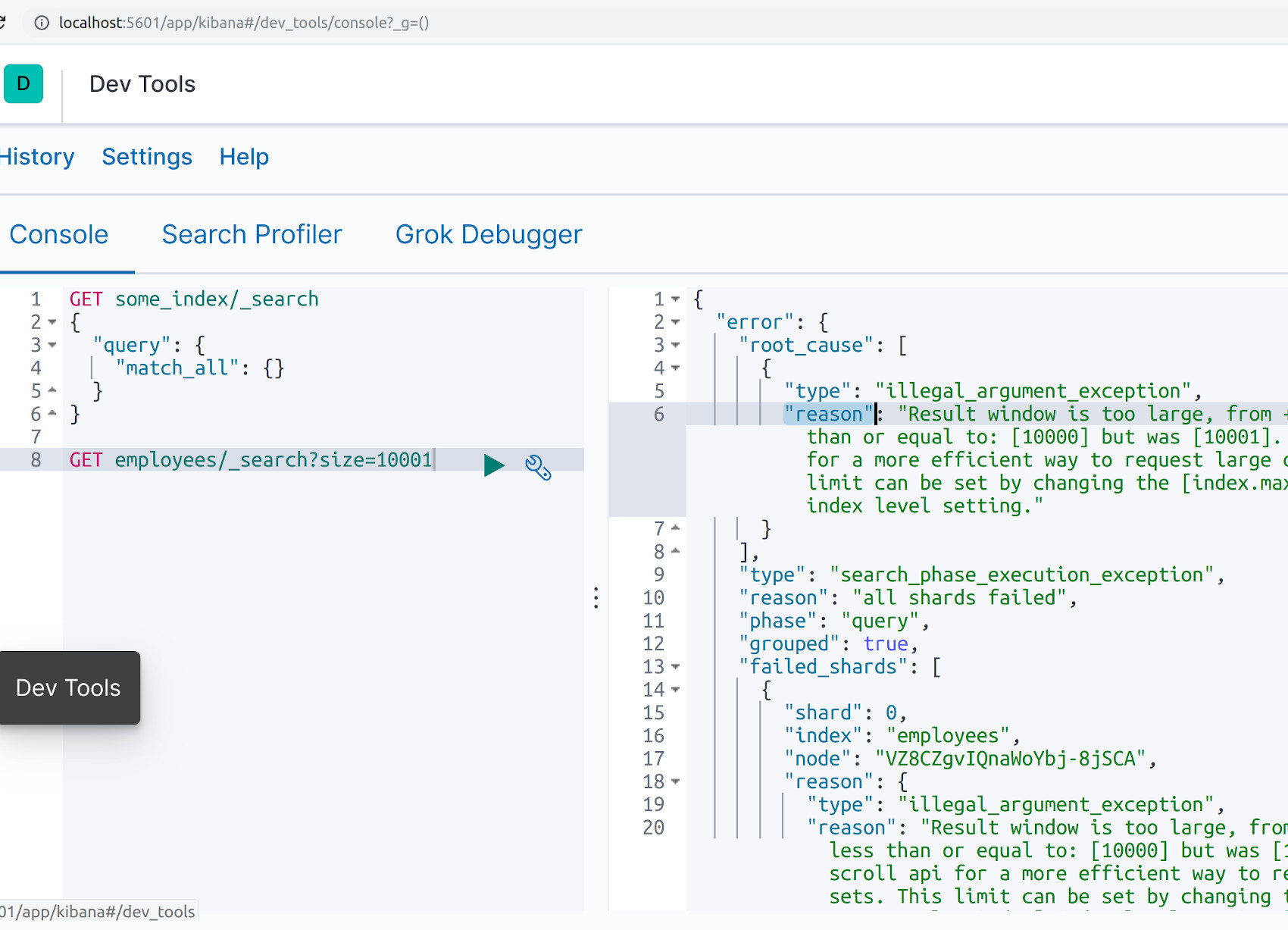
Executing a Scroll API request in Kibana
This tutorial will explain how to execute multiple API requests to retrieve Elasticsearch documents in batches. The following is an equivalent HTTP request in Kibana:
1 2 3 4 5 6 7 | GET some_index/_search?scroll=1s { "size": 100, "query": { "match_all" : {} } } |
The above example request is designed to search for documents, for up to one second per “batch”, that match the query . More time must be allocated for each request as the complexity of the query increases.
How to Import Libraries to Perform Query Requests to Elasticsearch
Import the Elasticsearch client library from the Elasticsearch Python distribution with the following command:
1 2 3 4 5 | # import the Elasticsearch client library from elasticsearch import Elasticsearch, exceptions # import JSON and time import json, time |
__NOTE:__ It is not absolutely necessary to import the json and time libraries. However, both these libraries will be used in this tutorial for formatting the JSON responses returned by Elasticsearch and for keeping track of the elapsed time for the API calls, respectively.
Connecting to Elasticsearch and Creating a Python Client Instance
Create a client instance of the low-level Python client library for Elasticsearch before making any Search or Scroll API requests.
Creating a timestamp for the script’s starting time and create variables for the Elasticsearch host
The following code will create a timestamp of when the script starts and will declare the domain and port variables for the Elasticsearch() method libraries host parameter:
1 2 3 4 5 6 | # create a timestamp using the time() method start_time = time.time() # declare globals for the Elasticsearch client host DOMAIN = "localhost" PORT = 9200 |
How to concatenate a host string and pass it to the Elasticsearch( ) client method
The following code shows how to concatenate the host variables into a domain string for the target Elasticsearch cluster and then declare a client instance of the Elasticsearch library:
1 2 3 4 5 | # concatenate a string for the client's host paramater host = str(DOMAIN) + ":" + str(PORT) # declare an instance of the Elasticsearch library client = Elasticsearch(host) |
Confirming there is a valid connection to Elasticsearch
Verify the connection to Elasticsearch is valid by calling the client’s info() method inside a try-except indentation block, as shown below. If there is no valid connection, the client instance will be given a value of None.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | try: # use the JSON library's dump() method for indentation info = json.dumps(client.info(), indent=4) # pass client object to info() method print ("Elasticsearch client info():", info) except exceptions.ConnectionError as err: # print ConnectionError for Elasticsearch print ("\nElasticsearch info() ERROR:", err) print ("\nThe client host:", host, "is invalid or cluster is not running") # change the client's value to 'None' if ConnectionError client = None |
__NOTE:__ The above code will raise a ConnectionError exception and print the following response if either the host string is incorrect or the cluster isn’t running:
1 2 3 4 | Elasticsearch info() ERROR: ConnectionError(('Connection aborted.', BadStatusLine('This is not an HTTP port'))) caused by: ProtocolError(('Connection aborted.', BadStatusLine('This is not an HTTP port'))) The client host: localhost:9300 is invalid or cluster is not running TOTAL TIME: 0.0056993961334228516 seconds. |
How to Get All of the Cluster’s Indices and Iterate Over the Elasticsearch Index
Provided the client is valid, all of the cluster’s indices can be obtained using the following API request:
1 2 3 4 5 6 7 8 9 10 11 | # valid client instance for Elasticsearch if client != None: # get all of the indices on the Elasticsearch cluster all_indices = client.indices.get_alias("*") # keep track of the number of the documents returned doc_count = 0 # iterate over the list of Elasticsearch indices for num, index in enumerate(all_indices): |
Using the above example, the indices names will be returned as a list object of index string names. Use Python’s enumerate() function to iterate over each index to get their respective documents.
Getting a Search( ) Response from the Elasticsearch Client Instance
Passing a "match_all" filter query to the client’s search() method will return all of that index iterations documents.
How to construct a filter query that will get all of the documents in an Elasticsearch index
The "size" parameter for the filter will depend on the size of the documents, how many documents there are and how many documents are requested returned with each scroll iteration. However, this will not affect the number of documents that are returned. Here is an example:
1 2 3 4 5 6 7 | # declare a filter query dict object match_all = { "size": 100, "query": { "match_all": {} } } |
How to pass a time string to the Search API’s ‘scroll’ parameter to return a scroll ‘_id’
A time string must be passed to the search() method’s scroll parameter to specify the length of time the search context is valid. This typically depends on the server’s CPU speed, its available memory, the size of the documents, etc.
As shown below, have the Search API return a response that will include a Scroll ID:
1 2 3 4 5 6 7 8 9 | # make a search() request to get all docs in the index resp = client.search( index = index, body = match_all, scroll = '2s' # length of time to keep search context ) # keep track of pass scroll _id old_scroll_id = resp['_scroll_id'] |
How to Iterate Over All of the Elasticsearch Documents using the Scroll API’s ID
The following code will iterate over all of the Elasticsearch documents using the Scroll API function:
1 2 | # use a 'while' iterator to loop over document 'hits' while len(resp['hits']['hits']): |
How to have Elasticsearch return a response using the Scroll API doc_count
Another response can be obtained by passing the _scroll_id string to the client’s scroll() method to return all of the documents during each while loop iteration:
1 2 3 4 5 | # make a request using the Scroll API resp = client.scroll( scroll_id = old_scroll_id, scroll = '2s' # length of time to keep search context ) |
Checking for a new _scroll_id returned by Elasticsearch
Unless the requests take an exceptionally long time, or iterates through a large number of documents per scroll, the request shouldn’t generate a new _scroll_id. However, the code to check each new scroll iteration is as follows:
1 2 3 4 5 6 | # check if there's a new scroll ID if old_scroll_id != resp['_scroll_id']: print ("NEW SCROLL ID:", resp['_scroll_id']) # keep track of pass scroll _id old_scroll_id = resp['_scroll_id'] |
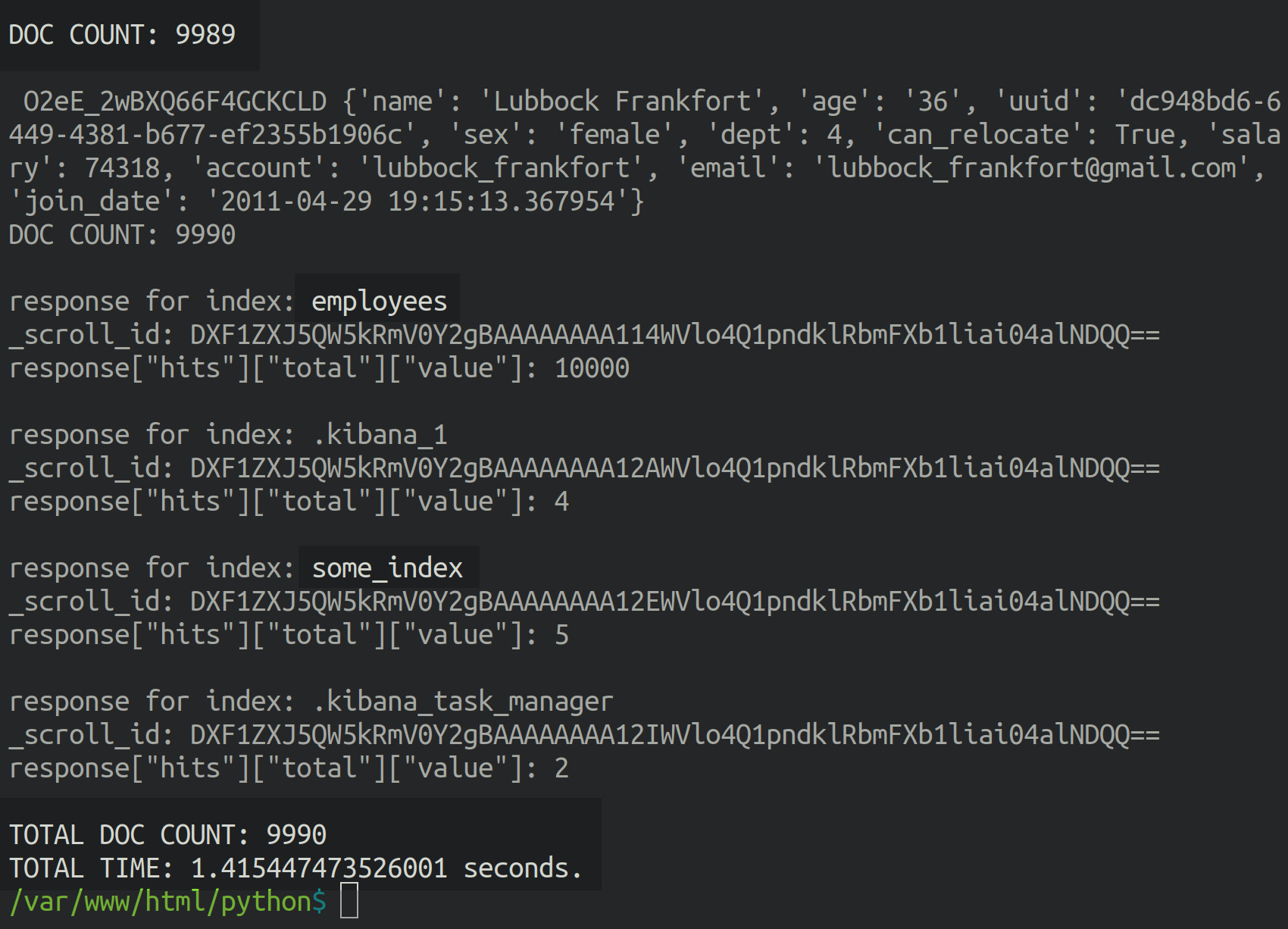
How to Print the JSON Response Returned by the Elasticsearch Scroll API
Print the IDs and "hits" returned by the scroll response by executing the following code:
1 2 3 4 5 6 7 8 9 10 11 12 13 | # print the response results print ("\nresponse for index:", index) print ("_scroll_id:", resp['_scroll_id']) print ('response["hits"]["total"]["value"]:', resp["hits"]["total"]["value"]) # iterate over the document hits for each 'scroll' for doc in resp['hits']['hits']: print ("\n", doc['_id'], doc['_source']) doc_count += 1 print ("DOC COUNT:", doc_count) # print the total time and document count at the end print ("\nTOTAL DOC COUNT:", doc_count) |
__NOTE:__ Be certain to incrementally increase the doc_count counter to check how many documents were returned.
How to print the total elapsed time at the end of the script
The following line of code will print the elapsed time by subtracting the start_time variable’s float value from the current time:
1 2 | # print the elapsed time print ("TOTAL TIME:", time.time() - start_time, "seconds.") |
Run the Python script in a terminal window using the python3 command followed by the name of the Python script, as shown in the following example:
1 | python3 get_all_docs.py |
Conclusion
This tutorial covered how to use the Search and Scroll API feature for Python to scroll queries for all documents in an Elasticsearch index using the Python low-level client library and how to use the Scroll API function to get all of an index’s documents in multiple batches. The tutorial also covered how to
create a timestamp for the script’s starting time and create variables for the Elasticsearch host, how to concatenate a host string and pass it to the Elasticsearch( ) client method and how to create a timestamp and print the total elapsed time at the end of the script. Remember to incrementally increase the doc_count counter to check how many documents were returned when printing the JSON response returned by the Elasticsearch Scroll API.
Just the Code
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 | #!/usr/bin/env python3 #-*- coding: utf-8 -*- # import the Elasticsearch client library from elasticsearch import Elasticsearch, exceptions # import JSON and time import json, time # create a timestamp using the time() method start_time = time.time() # declare globals for the Elasticsearch client host DOMAIN = "localhost" PORT = 9200 # concatenate a string for the client's host paramater host = str(DOMAIN) + ":" + str(PORT) # declare an instance of the Elasticsearch library client = Elasticsearch(host) try: # use the JSON library's dump() method for indentation info = json.dumps(client.info(), indent=4) # pass client object to info() method print ("Elasticsearch client info():", info) except exceptions.ConnectionError as err: # print ConnectionError for Elasticsearch print ("\nElasticsearch info() ERROR:", err) print ("\nThe client host:", host, "is invalid or cluster is not running") # change the client's value to 'None' if ConnectionError client = None # valid client instance for Elasticsearch if client != None: # get all of the indices on the Elasticsearch cluster all_indices = client.indices.get_alias("*") # keep track of the number of the documents returned doc_count = 0 # iterate over the list of Elasticsearch indices for num, index in enumerate(all_indices): # declare a filter query dict object match_all = { "size": 100, "query": { "match_all": {} } } # make a search() request to get all docs in the index resp = client.search( index = index, body = match_all, scroll = '2s' # length of time to keep search context ) # keep track of pass scroll _id old_scroll_id = resp['_scroll_id'] # use a 'while' iterator to loop over document 'hits' while len(resp['hits']['hits']): # make a request using the Scroll API resp = client.scroll( scroll_id = old_scroll_id, scroll = '2s' # length of time to keep search context ) # check if there's a new scroll ID if old_scroll_id != resp['_scroll_id']: print ("NEW SCROLL ID:", resp['_scroll_id']) # keep track of pass scroll _id old_scroll_id = resp['_scroll_id'] # print the response results print ("\nresponse for index:", index) print ("_scroll_id:", resp['_scroll_id']) print ('response["hits"]["total"]["value"]:', resp["hits"]["total"]["value"]) # iterate over the document hits for each 'scroll' for doc in resp['hits']['hits']: print ("\n", doc['_id'], doc['_source']) doc_count += 1 print ("DOC COUNT:", doc_count) # print the total time and document count at the end print ("\nTOTAL DOC COUNT:", doc_count) # print the elapsed time print ("TOTAL TIME:", time.time() - start_time, "seconds.") |


Pilot the ObjectRocket Platform Free!
Try Fully-Managed CockroachDB, Elasticsearch, MongoDB, PostgreSQL (Beta) or Redis.
Get Started