How to Use Elasticsearch Data Using Pandas in Python

Introduction to using Pandas and NumPy with Elasticsearch documents
If you’re a Python developer working with Elasticsearch, you may find yourself needing to parse and analyze the data that’s returned from search queries. Pandas is the natural choice for these tasks– it’s a library built on some of Python’s NumPy modules, and it can help to organize, iterate, and analyze Elasticsearch documents that have been returned from a search query. Pandas and NumPy can be used for creating multi-dimensional arrays and lists, and parsing through these structures quickly.
In this article, we’ll show you how to analyze Elasticsearch data with Pandas and Numpy. We’ll provide examples that use Pandas to parse, explore, and analyze data returned by an API call to the Elasticsearch Python client, and we’ll also show you how to install the necessary modules you’ll need to perform these tasks.
Prerequisites
Before we jump ahead to the Python code, let’s take a moment to review the system requirements for this task. There are a few important prerequisites to keep in mind:
Some knowledge of Python and its syntax is recommended.
The Python 3 interpreter needs to be installed and working properly. Both Pandas and NumPy work with Python 2; however, Python 2 is being deprecated and is not recommended for this reason.
The Elasticsearch service needs to be running. You can use the
lsof -n -i4TCP:9200command in a terminal to see if a process is running on Elasticsearch’s default port of9200. You can also make a cURL request to the server usingGETeither in Kibana or a terminal window to the domain running the Elasticsearch cluster:
1 | curl -XGET "http://localhost:9200" |
- You’ll need to have some data in an Elasticsearch index that you can use to make API
GETrequests to. Be sure your index has a strict_mappingschema, or at least ensure that all of the documents in the index have matching fields in their"_source"data. This will prevent Pandas from raisingValueErrorexceptions.
Install Pandas, NumPy, and the Python low-level client for Elasticsearch
Once you’ve confirmed all the system requirements, you can start installing some of the packages you’ll need for this task. To accomplish this, the PIP3 package manager for Python 3 needs to be installed on the machine or server running the Elasticsearch cluster. Use the pip3 -V command to determine which version of PIP 3 is installed; you can also use pip3 freeze to see a list of all of the installed PIP3 packages.
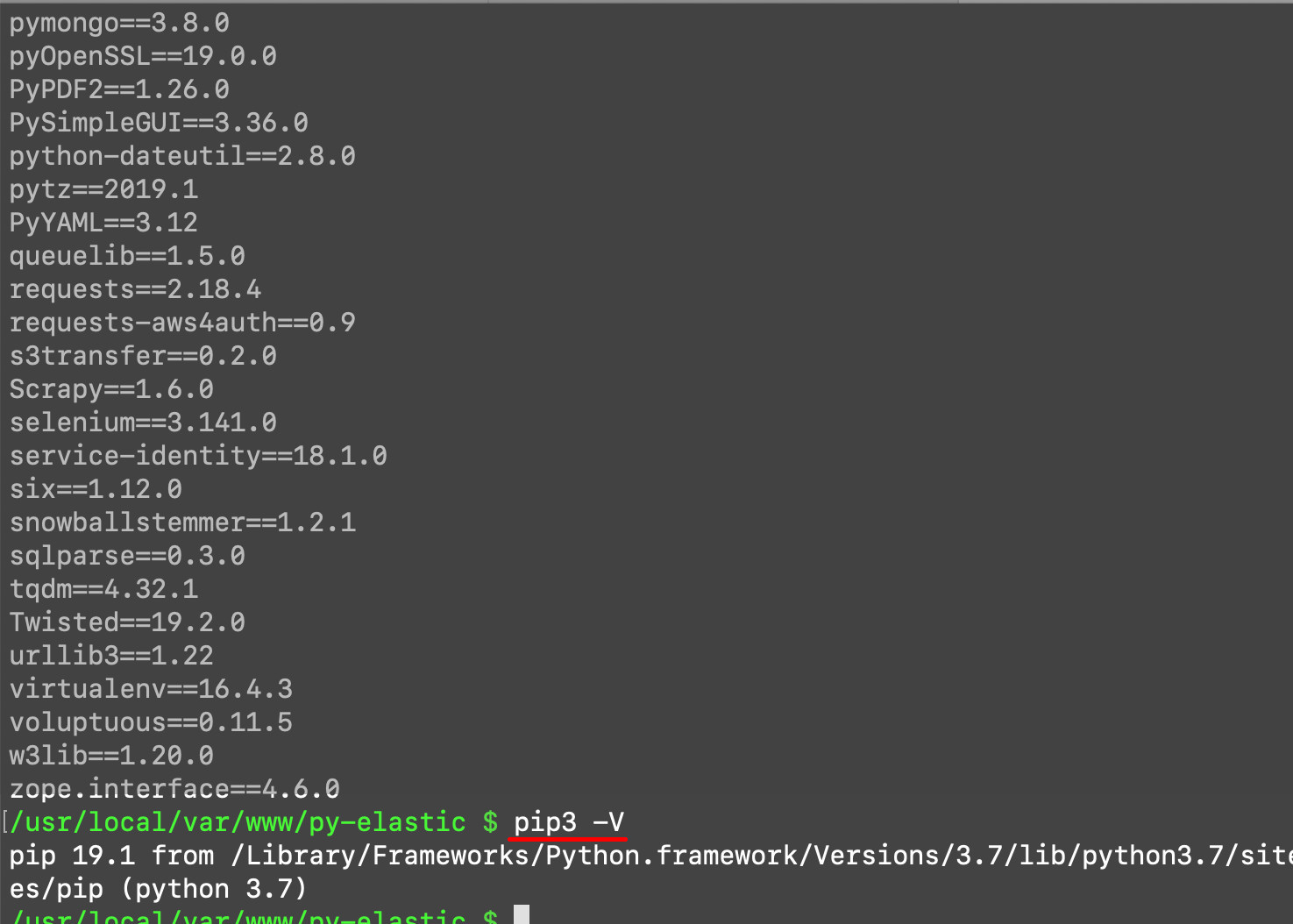
Install the elasticsearch low-level client library using pip3
Make sure to install the Python low-level client library for Elasticsearch, since this is what will be used to make API requests in the Python script.
1 | pip3 install elasticsearch |
Install the Pandas library for Python 3
Next, we’ll install Pandas:
1 | pip3 install pandas |
Install NumPy for Python 3 using pip3
You don’t necessarily need to install NumPy for these examples, since Pandas comes with the necessary NumPy dependencies; however, the stand-alone modules and functions can be useful:
1 | pip3 install numpy |
Use pip3 instead of pip to install modules and packages for Python 3.x
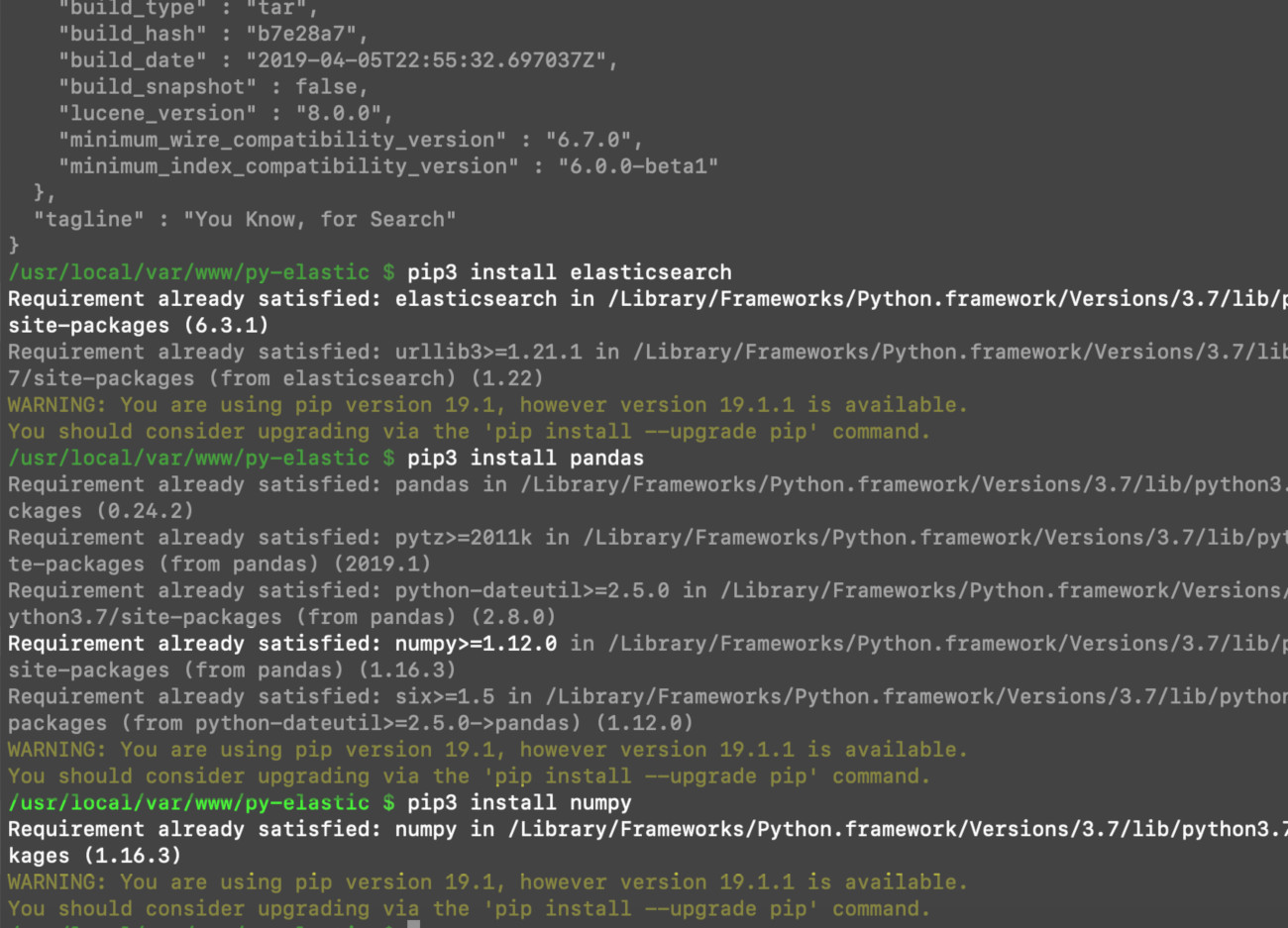
Import Elasticsearch, Pandas, and NumPy into a Python script
Now that we’ve installed everything we need, it’s time to turn our attention to the code. At the top of the Python script you’ll be using to make Elasticsearch API requests and perform Pandas operations, you’ll need to import all of the libraries and packages that you just installed.
Import NumPy and Pandas in the Python script
We’ll be using a few different libraries to parse Elasticsearch documents in Python. We’ll show you how to parse Elasticsearch documents with Pandas, and we’ll also parse Elasticsearch documents with NumPy, so we’ll need to import those libraries. To keep the code simple, we’ll import the entire numpy library under the alias np:
1 | import numpy as np |
You can import pandas with an alias as well, but the code examples you’ll see in this article use the actual library name:
1 | import pandas |
Import the Python low-level client library for Elasticsearch
You’ll also need to import the Elasticsearch class from the elasticsearch library. This class will be used to create a client instance for the API requests made to the Elasticsearch cluster:
1 | from elasticsearch import Elasticsearch |
If you’re planning to convert JSON strings into Python dictionaries using the json.loads() method, then you’ll also need to import the built-in JSON library for Python as well:
1 | import json |
Create an instance of the Elasticsearch low-level client and use it to get some documents
In the following code snippet, we’ll declare a client instance of the Elasticsearch library. Throughout this tutorial, we’ll use the variable name elastic_client for the client instance:
1 2 | # create a client instance of the library elastic_client = Elasticsearch() |
Make an API GET request to the Elasticsearch cluster to get documents and their _source data
Next, we’ll use our client instance to make a search request to an index. If you’re following along with these code examples using your own Elasticsearch data, make sure the documents in your index have several fields in their _source data. The examples in this article parse through the Elasticsearch "fields" of the documents’ source data.
Using the low-level client’s search() method to get documents from an Elasticsearch index
In the code shown below, we pass an empty dictionary object ({}) to the body parameter of the Search API method call. This will return all of the documents in a particular index:
1 | response = elastic_client.search( index='some_index', body={} ) |
Use the optional 'size' parameter in an Elasticsearch Search query to return more than 10 document records in the results
An Elasticsearch query, by default, will only return a maximum of 10 documents per API request. If you’d like to return more than 10, you can pass an integer to the optional "size" parameter in the search() method:
1 2 3 4 5 6 7 | # total num of Elasticsearch documents to get with API call total_docs = 10 response = elastic_client.search( index='some_index', body={}, size=total_docs ) |
You can also return more results by using the Scroll API or by passing an integer as the value of the "results" option, which is part of the query body object.
If you’re just testing out and debugging your Pandas and NumPy code, it’s best to stick to queries for fewer than 100 documents; otherwise, you may find yourself waiting a bit while Python iterates through massive data sets.
Put the API result’s [“hits”] data into a Python list
After you execute your query, Elasticsearch will return a response object, which is a JSON document in the form of a nested Python dictionary. The object will contain the following keys: 'timed_out', '_shards', and 'hits'. For now, we’re going to focus on the "hits" key, which allows access to the documents returned by the query.
Nested inside "hits" are three more keys: total, which represents the total number of documents returned, a max_score of the query results, and another "hits" dictionary that contains the actual list of returned Elasticsearch documents and their associated "_source" data.
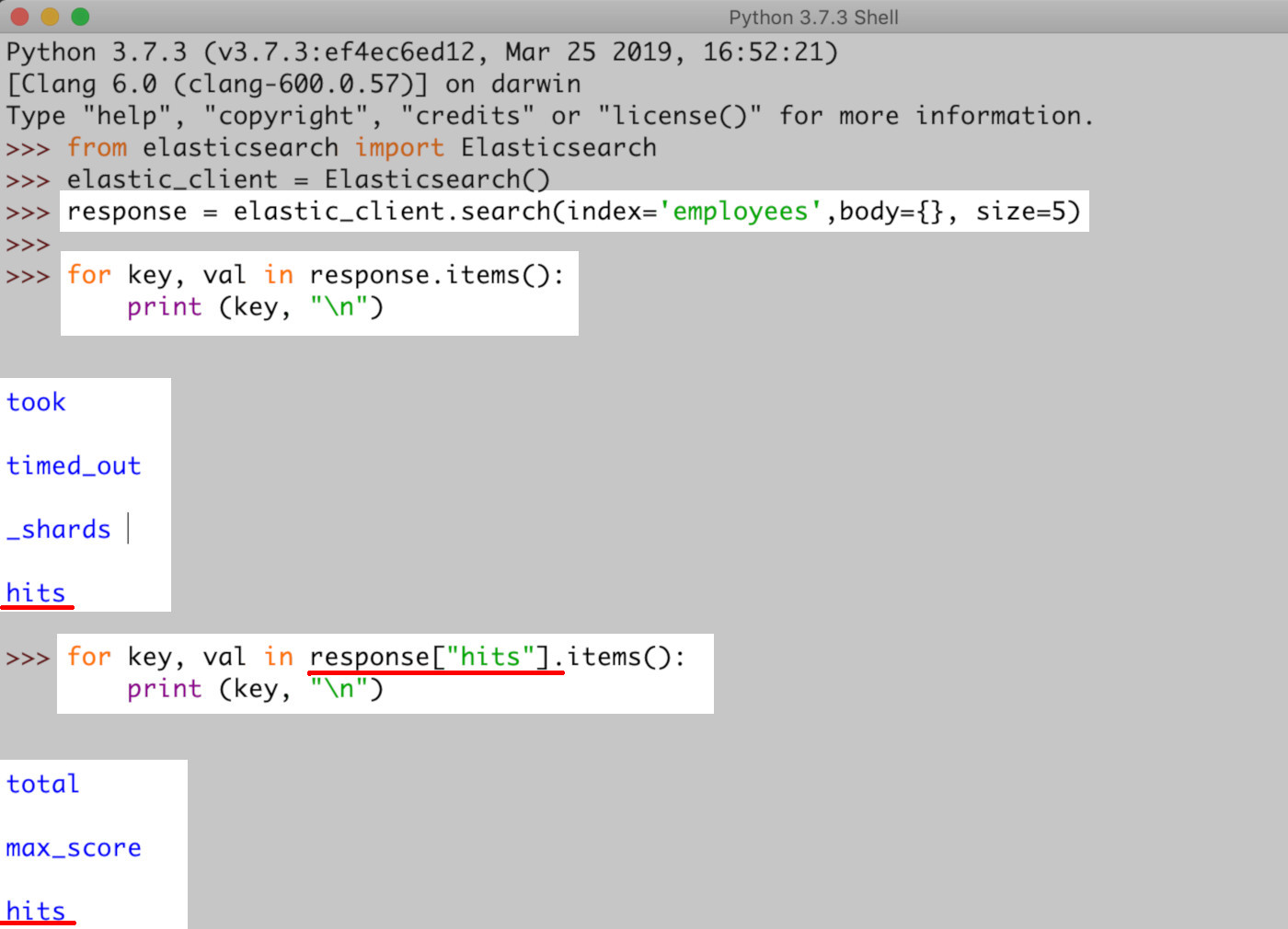
Another way to describe the nested dictionary structure of the returned results: The list containing the document "_source" data can be found nested inside ["hits"]["hits"] in the API response object returned by search():
1 2 3 4 5 6 | # declare a new list for the Elasticsearch documents # nested inside the API response object elastic_docs = response["hits"]["hits"] # print number of documents print ("documents returned:", len(response["hits"]["hits"])) |
Iterate and parse the list of Elasticsearch documents
Now that you’re able to access the list of Elasticsearch documents in the results, you can iterate over the list to get the data needed for Pandas and NumPy.
Use Python’s enumerate() function to iterate over the list of Elasticsearch documents
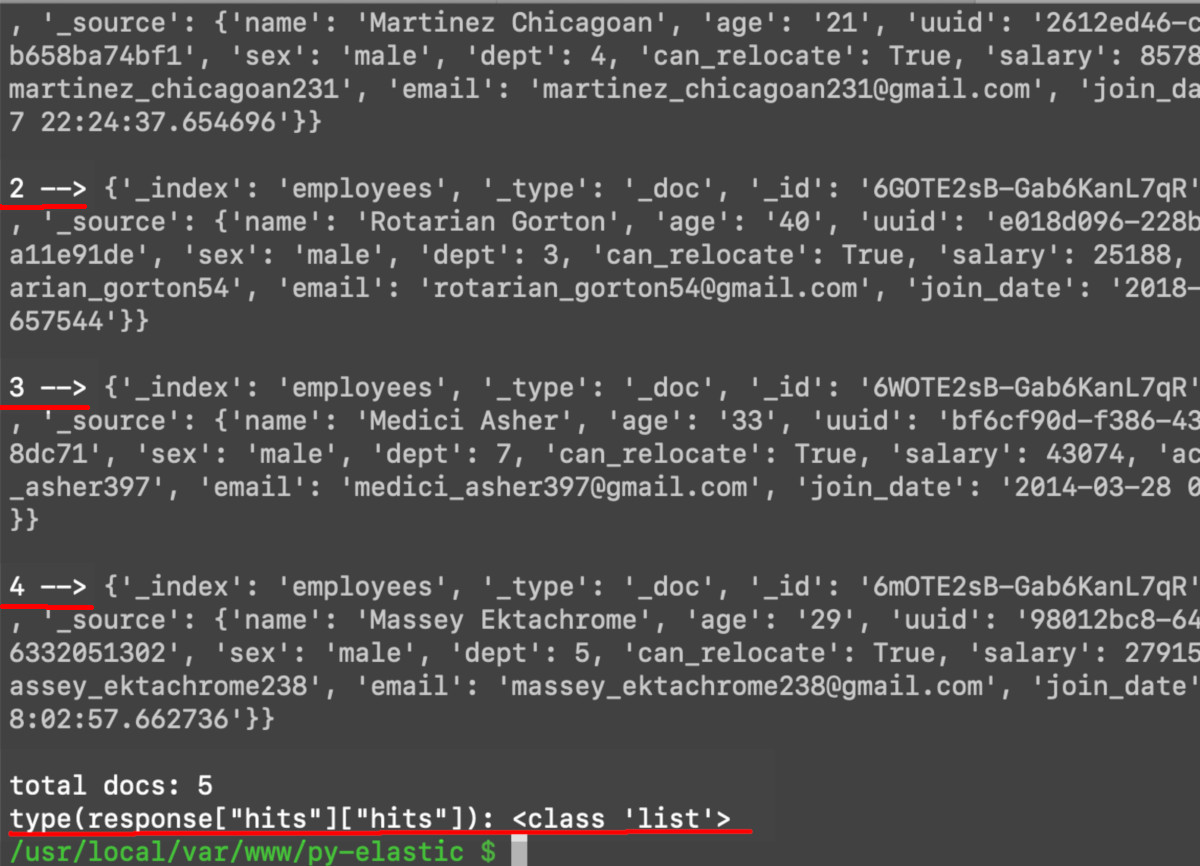
Although you can simply use a for loop to iterate over the list of documents, Python’s built-in enumerate() function is a more efficient method:
1 2 3 4 5 | # iterate over all of the docs (use iteritems() in Python 2) for key, val in response["hits"].items(): if key == "hits": for num, doc in enumerate(val): print (num, '-->', doc, "\n") |
This code will print out all of the documents from the search query, assigning a number to each document starting with zero:
Get all of the fields from the Elasticsearch documents
Before we iterate through the documents, we need to create an empty dictionary object that will be used to store the Elasticsearch "_source" data’s field types.
Declare an empty dictionary for the Elasticsearch document fields
A key will be created for all of the document’s fields with every iteration through the list.:
1 2 3 4 | fields = {} for num, doc in enumerate(elastic_docs): pass # do stuff here! |
Create aggregations of the Elasticsearch document "_source" data using NumPy arrays
Next, we’ll create a variable that we’ll use to store all of the key-value pairs inside the doc["_source"] dictionary object. Be sure to indent this code because it is running inside enumerate():
1 2 | # get source data from document source_data = doc["_source"] |
In the next code snippet, we’ll be putting Elasticsearch documents into NumPy arrays.
Remember that doc["_source"] is a dictionary, so you’ll need to iterate over it using the item() method (for Python 2.x, use iteritems() instead). Be sure to use a try-except block when you attempt to append the data to a numpy.ndarray object. In the case of a KeyError, you can have the code create a new object with the values instead of appending to an existing object:
1 2 3 4 5 6 | # iterate source data (use iteritems() for Python 2) for key, val in source_data.items(): try: fields[key] = np.append(fields[key], val) except KeyError: fields[key] = np.array([val]) |
If you ran the script at this point, each of the fields would have their own NumPy ndarray object arrays, with each one containing all of the documents’ respective data.
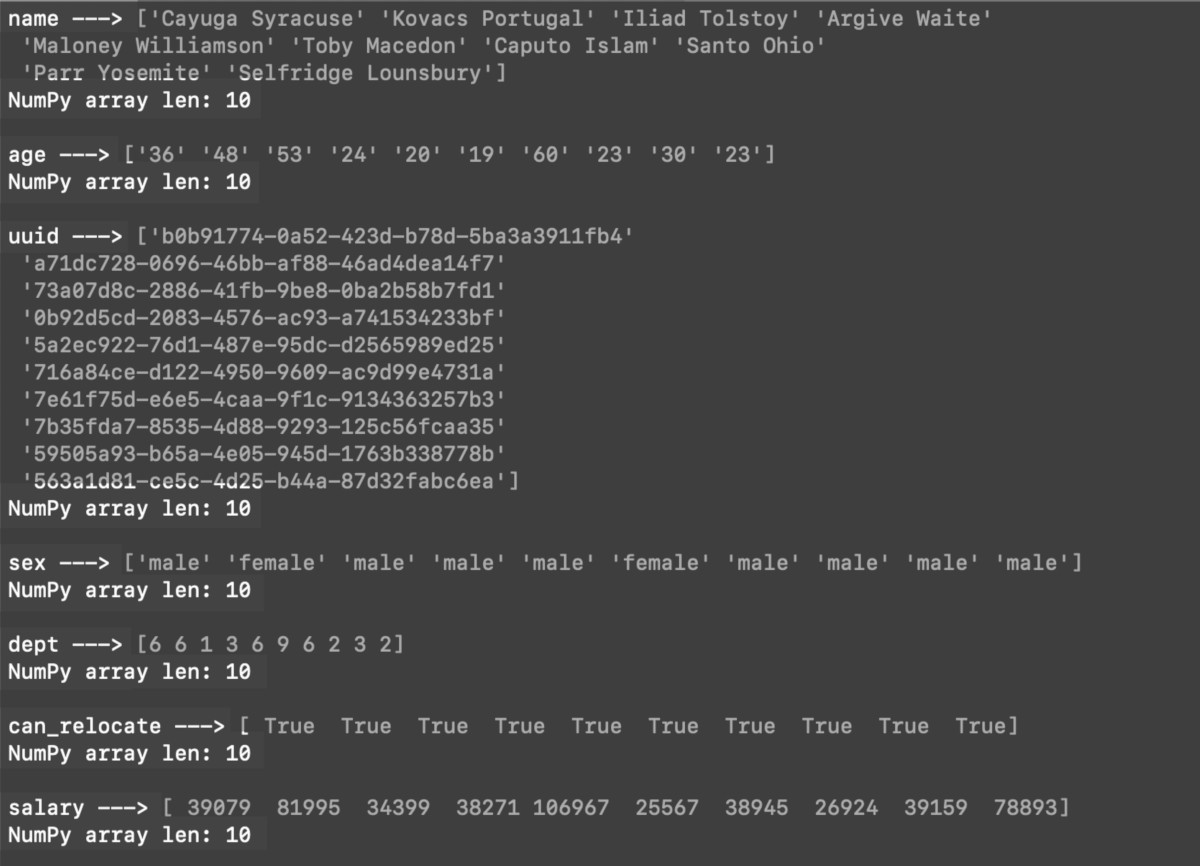
Iterating over these NumPy arrays is simple. The following code iterates over the aggregated Elasticsearch _source data and displays each value in the form of a list:
1 2 3 | for key, val in fields.items(): print (key, "--->", val) print ("NumPy array len:", len(val), "\n") |
This example is iterating over 10 documents returned from an Elasticsearch index search() query
Create a Pandas DataFrame object from the NumPy object arrays
The Pandas library includes a structure called a DataFrame. This structure is a multidimensional object array that can be made up of Python dictionaries, Pandas Series objects, or even NumPy ndarray objects.
Create a Pandas DataFrame array from the Elasticsearch fields dictionary
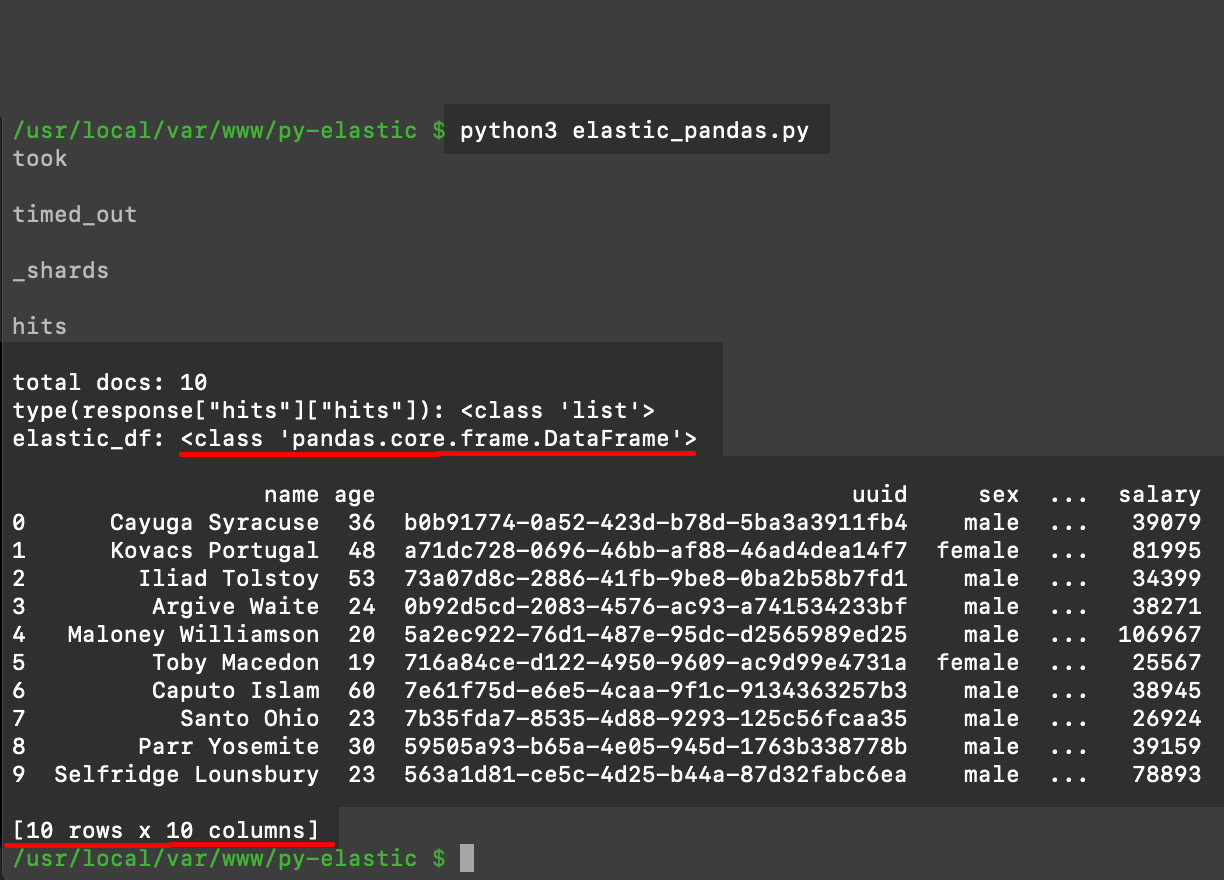
Since all of the data has already been placed into different NumPy ndarray objects, which reside inside a dictionary, we can easily create a DataFrame object from that data. All we have to do is pass the dictionary into the DataFrame method and have it return the DataFrame object. You can see how this works in the example below:
1 2 3 4 5 | # create a Pandas DataFrame array from the fields dict elastic_df = pandas.DataFrame(fields) print ('elastic_df:', type(elastic_df), "\n") print (elastic_df) # print out the DF object's contents |
WARNING: If the documents in your Elasticsearch index don’t have the same fields (i.e.: if the index’s "_mapping" is not strict), or the same number of fields, then you’ll probably encounter a ValueError('arrays must all be same length') exception. This occurs because Pandas requires all the array objects to be the same length when they’re being used to create a DataFrame object.
Pandas neatly prints out all of the rows and columns of Elasticsearch data stored in the DataFrame array object
Convert the aggregated Elasticsearch data into a JSON string with the to_json() method in Pandas
One useful method, included in both the DataFrame and Series object in Pandas, is the to_json() method. This method will return the data stored in the Pandas objects as a JSON string:
1 2 3 | # create a JSON string from the Pandas object json_data = elastic_df.to_json() print ("\nto_json() method:", json_data) |
Verify that Pandas’ to_json() method creates a legitimate JSON string
You can use the json.loads() method inside a try-catch block to confirm that to_json actually created a JSON string:
1 2 3 4 5 6 7 | # verify that the to_json() method made a JSON string try: json.loads(json_data) print ("\njson_data is a valid JSON string") except json.decoder.JSONDecodeError as err: print ("\njson.decoder.JSONDecodeError:", err) print ("json_data is NOT a valid JSON string") |
Create Pandas Series object arrays out of Elasticsearch documents
Another way to import Elasticsearch data into Pandas is by creating a Pandas series object array out of an Elasticsearch document. To do this, simply iterate through the elastic_docs list again after creating another empty dictionary:
1 2 | # create an empty dict for series arrays elastic_series = {} |
While iterating through the list, take each document’s _id and add a Pandas series object to the dictionary using the _id as the key:
1 2 3 4 5 6 7 8 9 10 11 | # iterate the docs returned by API call for num, doc in enumerate(elastic_docs): # get the _id for the doc _id = doc["_id"] # get source data from document source_data = doc["_source"] # make a Pandas Series object for the doc using _id as key elastic_series[_id] = pandas.Series() |
Next, we iterate through the document dictionary object and put the values into our newly created Series object, which has the unique Elasticsearch "_id" as its key:
1 2 3 4 5 6 7 8 | # make a Pandas Series object for the doc using _id as key elastic_series[_id] = pandas.Series() # iterate source data (use iteritems() for Python 2) for field, value in source_data.items(): # set the field type as Series index and value as Series val elastic_series[_id].at[field] = value |
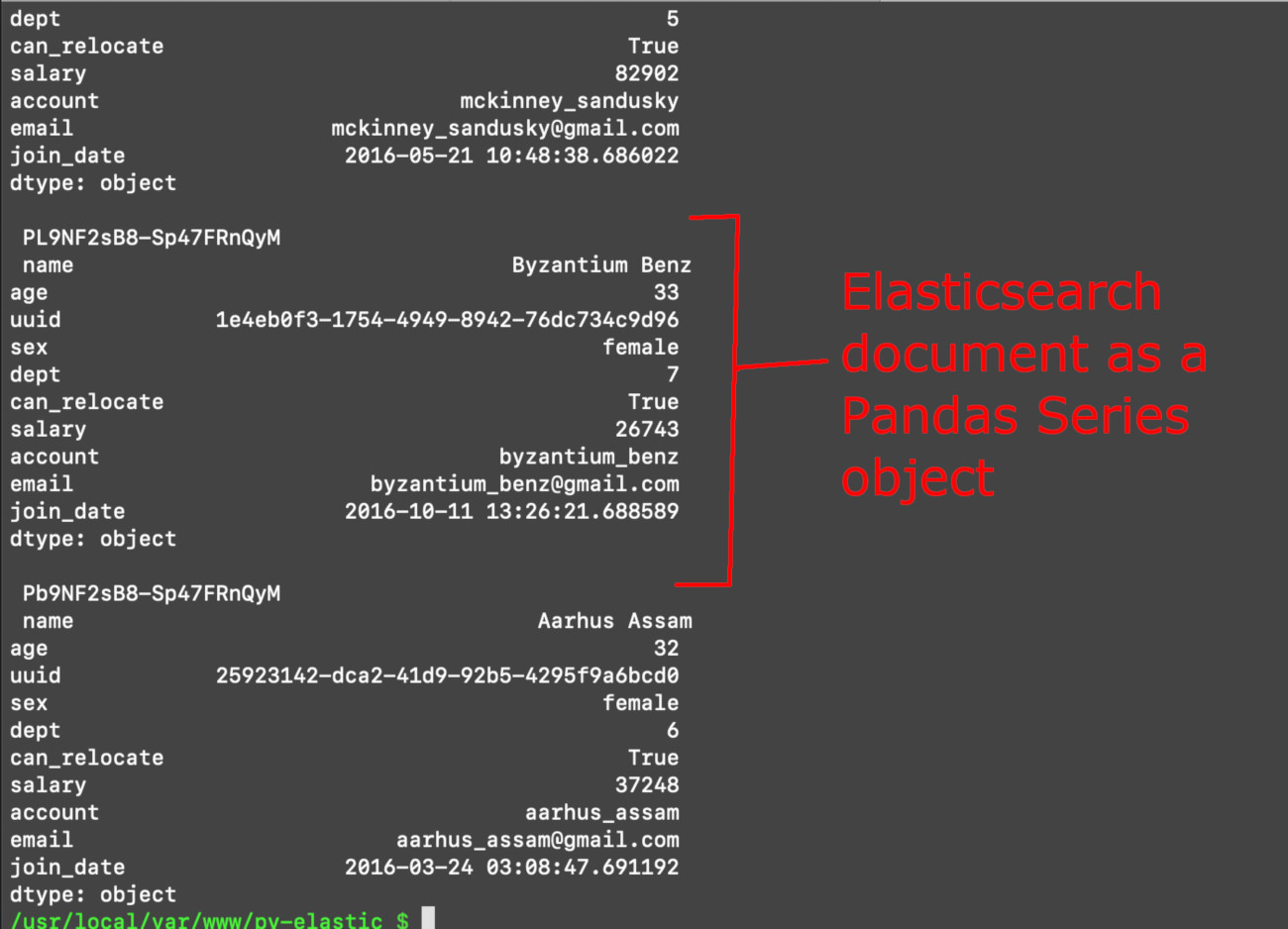
In the code shown below, we iterate over the elastic_series dictionary and print out the Series arrays stored in it:
1 2 | for key, doc in elastic_series.items(): print ("\nID:", key, "\n", doc) |
Print out the Elasticsearch data of each Series object array
Conclusion
When you’re working with Elasticsearch data in Python, the Pandas and NumPy libraries can be useful tools to help you parse and analyze your query results. In this tutorial, we showed you how to analyze Elasticsearch data with NumPy object arrays and Pandas series objects. With the instructions and examples provided in this article, you’ll be ready to get started with these helpful libraries in your own code.
Throughout this tutorial, we looked at the code one section at a time. Here’s the complete Python script which is comprised of all the examples in this article:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 | #!/usr/bin/env python3 #-*- coding: utf-8 -*- # create a client instance of the library elastic_client = Elasticsearch() # total num of Elasticsearch documents to get with API call total_docs = 10 response = elastic_client.search( index='some_index', body={}, size=total_docs ) # create a new list for the Elasticsearch documents # nested inside the API response object elastic_docs = response["hits"]["hits"] # print number of documents returned print ("documents returned:", len(response["hits"]["hits"])) """ STORE THE ELASTICSEARCH INDEX'S FIELDS IN A DICT """ # create an empty dictionary for Elasticsearch fields fields = {} # iterate over the document list returned by API call for num, doc in enumerate(elastic_docs): # iterate source data (use iteritems() for Python 2) for key, val in source_data.items(): try: fields[key] = np.append(fields[key], val) except KeyError: fields[key] = np.array([val]) # iterate key-value pairs of the fields dict for key, val in fields.items(): print (key, "--->", val) print ("NumPy array len:", len(val), "\n") """ CREATE A DATAFRAME OBJECT FROM ELASTICSEARCH FIELDS DATA """ # create a Pandas DataFrame array from the fields dict elastic_df = pandas.DataFrame(fields) print ('elastic_df:', type(elastic_df), "\n") print (elastic_df) # print out the DF object's contents # create a JSON string from the Pandas object json_data = elastic_df.to_json() print ("\nto_json() method:", json_data) # verify that the to_json() method made a JSON string try: json.loads(json_data) print ("\njson_data is a valid JSON string") except json.decoder.JSONDecodeError as err: print ("\njson.decoder.JSONDecodeError:", err) print ("json_data is NOT a valid JSON string") """ CREATE SERIES OBJECTS FROM ELASTICSEARCH DOCUMENTS """ # create an empty dict for series arrays elastic_series = {} # iterate the docs returned by API call for num, doc in enumerate(elastic_docs): # get the _id for the doc _id = doc["_id"] # get source data from document source_data = doc["_source"] # make a Pandas Series object for the doc using _id as key elastic_series[_id] = pandas.Series() # iterate source data (use iteritems() for Python 2) for field, value in source_data.items(): # set the field type as Series index and value as Series val elastic_series[_id].at[field] = value for key, doc in elastic_series.items(): print ("\nID:", key, "\n", doc) |


Pilot the ObjectRocket Platform Free!
Try Fully-Managed CockroachDB, Elasticsearch, MongoDB, PostgreSQL (Beta) or Redis.
Get Started