How to Perform a Full Cluster Restart for Elasticsearch Upgrade
Introduction
Initiating a full cluster restart for Elasticsearch requires you to shut all down nodes in the cluster, upgrade the nodes and the restart the cluster. For this tutorial, you will need to confirm your are running Elastic Stack version 6.x or greater on your server before you can perform a full cluster restart for Elasticsearch. You will have to delete or re-index any indexes on your current cluster from Elasticsearch version 2.0 or earlier. You will then need to disable shard allocation for the indexes, stop any indexing of documents and machine-learning jobs and shutdown all nodes in the cluster. After restart, you will be able to re-enable the shard allocation after the nodes have fully recovered their primary shards and joined the cluster:
Prerequisites
- Check to confirm your server is running Elastic Stack version 6.x or greater and then execute a cURL request to get the program running on your server:
1 2 3 | curl -XGET localhost:9200 # or.. curl -XGET {YOUR_DOMAIN}:9200 |
Then execute an HTTP request to retrieve information about the Elasticsearch cluster
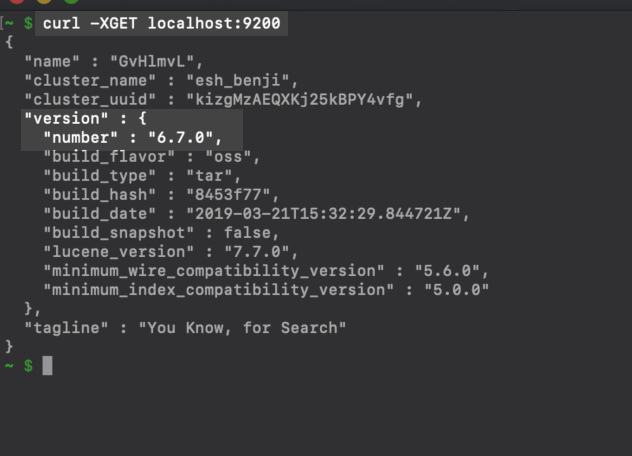 Check to confirm the Kibana service is running properly, if you intend to make these requests in the Kibana Console UI. Typically, the Kibana service runs on port
Check to confirm the Kibana service is running properly, if you intend to make these requests in the Kibana Console UI. Typically, the Kibana service runs on port 5601 of your server.
Now navigate to http://localhost:5601/app/kibana#/dev_tools/console in your browser to access the console UI. Alternatively, you can click on the Dev Tools tab on the left-hand side of the Kibana console.
- The
"number"index of the returned JSON object’s"version"field should display a value of"6.x.x".
Elasticsearch Indexes Older Than Version 2.0
- You must delete or re-index any indexes on your cluster from Elasticsearch 2.0 or earlier versions.
Upgrading to Elasticsearch 7.x
- IMPORTANT: If you are using a version of Elasticsearch older than 6.0, you will first need to upgrade to Elasticsearch 6.7 and then re-indexed any indexes that were created on version of Elasticsearch prior to 6.0.
Upgrading to Elasticsearch 6.x
- These instructions are not necessary if you are currently running Elasticsearch version 5.6 or newer.
In this case, rolling cluster upgrades are supported.
- If you are currently running a version of Elasticsearch older than 5.6, and you want to upgrade to Elasticsearch version 6.x, you must perform a full cluster restart.
WARNING: You are well advised to completely back up all of the indices on the server’s Elasticsearch cluster along with all of their documents and any other relevant data shared by the file system before preceding with a major version upgrade.
Full Cluster Restart Upgrade Preparation
To ensure a successful upgrade, it is vital you take the following steps to prevent possible system errors prior to initiating a full-cluster restart upgrade:
Disable shard allocation for the indexes.
Cease indexing of documents.
All indexes should undergo a synced flush to aid with shard recovery.
You must stop any running machine-learning (_ml) jobs.
* You must shutdown all nodes in the cluster.
The complete details on how to perform the full cluster restart upgrade can be found in the official documentation for Elasticsearch.
Performing the Full Cluster Restart Upgrade
Disable Shard Allocation
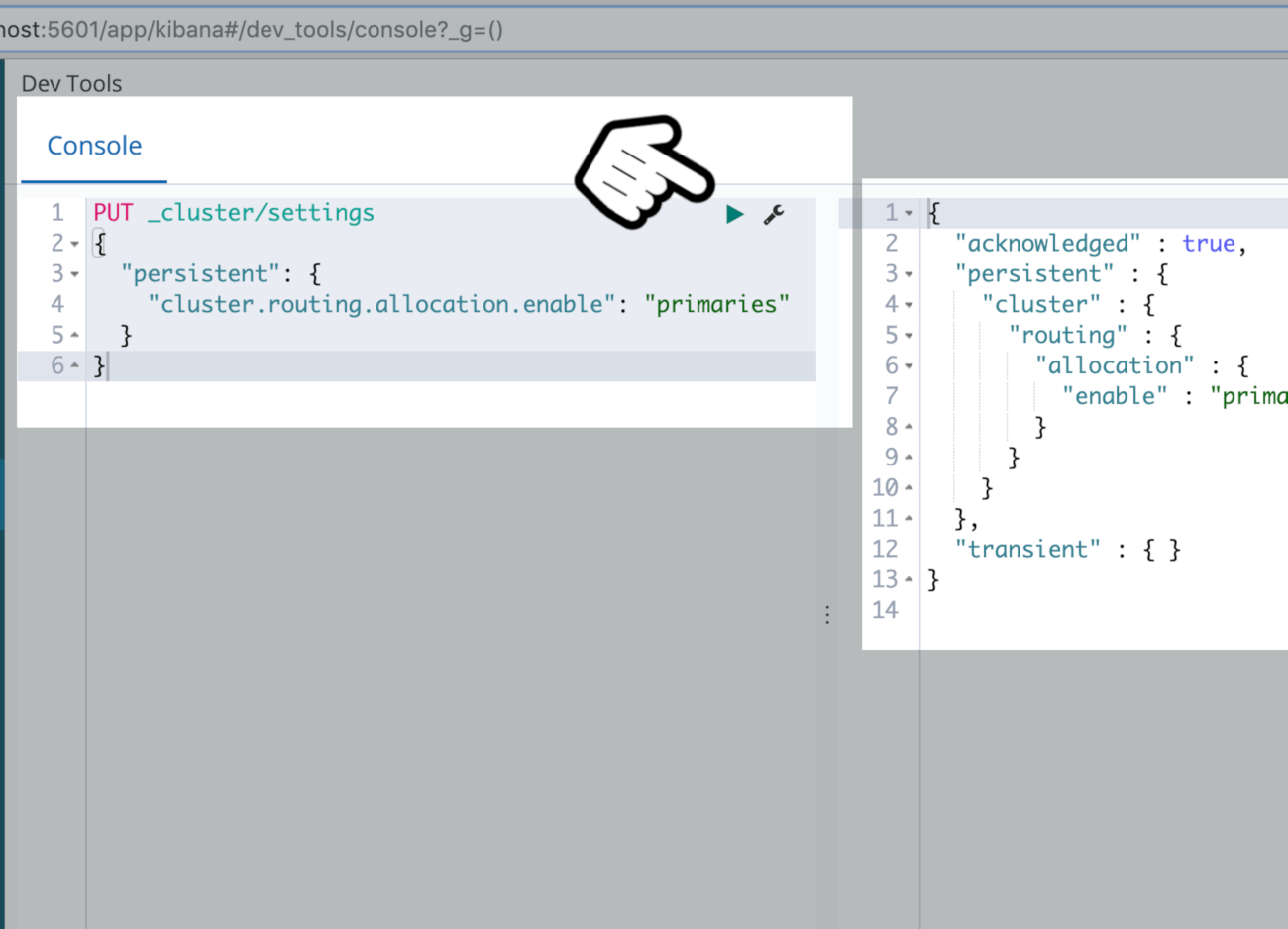
- The first step is to disable the allocation of replica shards by setting the
"cluster.routing.allocation.enable"option to"primaries"using Kibana or an HTTP cURL request in command prompt or terminal:
1 2 3 4 5 6 | PUT _cluster/settings { "persistent": { "cluster.routing.allocation.enable": "primaries" } } |
*Alternatively, you can also use a cURL HTTP PUT request to disable allocation of the replica shards, provided you have remote SSH access to your server:
1 2 3 4 5 6 7 | curl -X PUT "localhost:9200/_cluster/settings" -H 'Content-Type: application/json' -d' { "persistent": { "cluster.routing.allocation.enable": "primaries" } } ' |
NOTE: Make certain you re-enable the shard-routing allocation by setting its value back to null, without quotes, after the upgrade has been completed.
Modifying Cluster Routing Allocation in the Kibana Console
Preventing Unnecessary Indexing of Elasticsearch Documents
- Stop all non-essential indexing in your Elasticsearch cluster to prevent it from potentially slowing down the upgrade process.
Disable the machine learning (_ml) endpoint:
- Set the “upgrade mode” boolean setting for the machine learning endpoint to
true:
1 | POST _ml/set_upgrade_mode?enabled=true {} |
Make certain you return the setting to false after the upgrade has completed.
You will achieve much faster shard recovery by preventing any non-necessary indexing.
Make a Synced Flush request
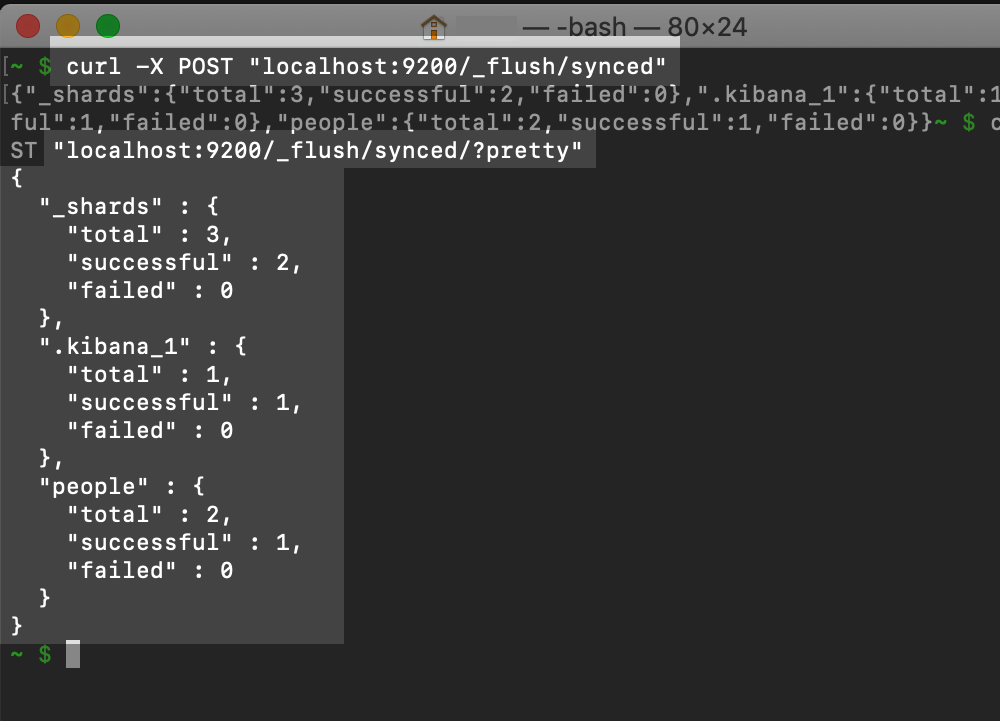
In order to assist and speed up shard recovery, you should preform a sync-flush before executing the cluster restart:
POST _flush/syncedHere’s the cURL version for the same command:
`bash curl -X POST “localhost:9200/_flush/synced”`
You should monitor for errors and other issues while performing the flush. Simply repeat the flush if you detect any problems. Use the ?pretty option to have the request return the JSON response object in a more easily readable format.
Elasticsearch Sync Flush in terminal using a cURL request
Throttle Back the Allocation of the Elasticsearch Nodes
- An alternative way of making the process more efficient is to throttle the allocation of nodes while updating the Elasticsearch clusters:
1 2 3 4 5 | curl -XPUT localhost:9200/_cluster/settings -d '{ "persistent" : { "cluster.routing.allocation.node_concurrent_recoveries" : "1" } }' |
The default for this setting is "2".
Shut Down All Nodes
The
_shutdownAPI has been depreciated since Elasticsearch version 1.6. This means the easiest way to shut the nodes down is to use the CTRL+C keys if the service is running as a foreground service in the terminal console, or to stop the service using a command if it’s running as a background service.If the Elasticsearch service is running as part of a
systemdservice (use theps -p 1command in a Linux terminal to check) you can use thestopcommand to shut down the service:
1 2 3 | sudo systemctl stop elasticsearch.service # ..or sudo -i service elasticsearch stop |
Another option to stop Elasticsearch is to use the
servicecommand, using the-ioption.If neither of these methods work, or you are in any way unsure as to how or where the service is running, you can use the following command to try to “grep” the service’s PID:
1 2 3 4 5 | sudo service --status-all | grep 'elastic' ## ..or return cat info on the PID: cat /tmp/elasticsearch-pid && echo ## ..or grep the JVM Process Status for the Elastic PID jps | grep Elasticsearch |
Once you have found the PID of the Elasticsearch service, you can use the process ID to stop the service with the following kill command:
1 | kill -SIGTERM 12345 # replace these numbers with PID |
NOTE: You may need run these terminal commands with sudo privileges.
Upgrade the Elasticsearch Package:
Use the apt-get package manager to update Elasticsearch if you’re running the Elastic Stack on a Debian-based distro of Linux, like Ubuntu or Debian.
If the Linux distro is an RPM-based distro, or “Red Hat” Linux such as Fedora or CentOS, use the RPM repository to upgrade.
You can use the rpm or dpkg commands to install the downloaded package. This will allow you to unzip the archives and install the files in their respective locations, without overwriting any of the Elasticsearch configuration files.
Upgrade the Elasticsearch Plugins
You will likely experience issues if the plugins for Elasticsearch are not upgraded to match the correct version of the node the program is running on. If in doubt, use the elasticsearch-plugin script to determine if the versions of the installed plugins are compatible with the upgraded nodes.
You can run the script with Python (version 3). Check out Elastic’s official Git repo for the elasticsearch-plugin script for more information.
Start Each Upgraded Node
- If there are nodes with a dedicated “master” role, meaning nodes that have the
node.masterboolean setting attrueand thenode.dataoption set tofalse, you should start these nodes first: - You should begin the process by getting the health and status of the nodes:
1 2 | GET _cat/health GET _cat/nodes |
You can also use cURL if you prefer, ideally using the ?pretty option for ease of readability:
1 2 | curl -XGET 'localhost:9200/_cat/health?pretty' curl -XGET 'localhost:9200/_cat/nodes?pretty' |
NOTE: By default, all nodes have all the various roles set to true. However, there must always be at least one node that is eligible for the “master” role, and ideally more than one node.
Re-enable Shard Allocation
- You will be able to re-enable the shard allocation after the nodes have fully recovered their primary shards and joined to the cluster:
1 2 3 4 5 6 | PUT _cluster/settings { "transient": { "cluster.routing.allocation.enable": "all" } } |
- cURL version
1 2 3 4 5 6 7 | curl -X PUT "localhost:9200/_cluster/settings" -H 'Content-Type: application/json' -d' { "transient": { "cluster.routing.allocation.enable": "all" } } ' |
You should continue to execute regular _cat/health and _cat/recovery API requests to the cluster to stay current on the health and progress of the shards and nodes:
GET _cat/health
GET _cat/recovery
- cURL version
1 2 | curl -X GET "localhost:9200/_cat/health" curl -X GET "localhost:9200/_cat/recovery" |
Conclusion
In this tutorial you learned how to prepare and execute a full cluster restart for Elasticsearch. Remember, you must be running Elastic Stack version 6.x or greater and delete or re-index any indexes on your cluster from Elasticsearch 2.0 or earlier versions for the restart process to be successful. Additionally, if you are currently running a version of Elasticsearch older than 5.6, and you want to upgrade to Elasticsearch version 6.x, you must perform a full cluster restart.
Remember, before running a full cluster restart for Elasticsearch you must stop all non-essential indexing to prevent it from potentially slowing down the upgrade process. Likewise, don’t forget to monitor for errors while performing a flush. Be sure to re-enable the shard-routing allocation after the upgrade has been completed. You may experience issues if the Elasticsearch plugins are not properly matched to the node the program is running on. Do not forget, there must always be at least one node eligible for the master role. Finally, back up all indices on the server’s Elasticsearch cluster, as well as any other relevant data, before executing a major version upgrade.

Pilot the ObjectRocket Platform Free!
Try Fully-Managed CockroachDB, Elasticsearch, MongoDB, PostgreSQL (Beta) or Redis.
Get Started