How to Parse Lines in a Text File and Index as Elasticsearch Documents using Python
Introduction
This tutorial will explain how to parse lines in a text file and index them as Elasticsearch Documents using the Python programming language. To legally parse a line-by-line text file index for Elasticsearch documents with Python bulk, the user must have the rights to use to the content being inserting into a MongoDB collection. Alternatively, an opensource/public domain text document should be used. To demonstrate how open, iterate and parse the data in a text file, this tutorial will use the opensource eBook titled “Webster’s Unabridged Dictionary by Various.” This text can be found on the Gutenberg website.
Prerequisites to parse a line-by-line text file index for Elasticsearch documents with Python bulk
- The text file with the data being indexed into Elasticsearch should be stored on the same machine or server running the Elasticsearch cluster. Use the following cURL request to verify that Elasticsearch is running:
1 | curl -XGET "localhost:9200" |
NOTE: Make sure to replace the "localhost" domain and its port with the settings that match the Elasticsearch cluster.
Have enough free space on the machine or server to download a copy of Webster’s Dictionary.
Installation of Python 3 and the Elasticsearch client for Python 3 to make the API calls to Elasticsearch. Note that Python 2 is now deprecated. Execute the following command to install the low-level client using the PIP3 package manager:
1 | pip3 install elasticsearch |
How to Import the Necessary Python and Elasticsearch Libraries
Execute the below script to import the built-in pickle, time and json Python libraries, shown at the start of the script. Then import the Elasticsearch and helpers libraries from the Python low-level client for Elasticsearch shown at the end of the following script:
1 2 3 4 5 6 7 8 | # import Python's pickle library to serialize the dictionary import pickle # import Python's time and JSON library import time, json # use the elasticsearch client's helpers class for _bulk API from elasticsearch import Elasticsearch, helpers |
How to use the Python’s time library to store the epoch time of when the script starts
The API call to Elasticsearch may take some time to execute, depending on the size of the text file and the number of documents being parsed. Use the time.time() method call to return a float number representing the epoch time and store it in order to check it at the end of the operation to see how many seconds have passed since the start of the script. Execute the following code:
1 2 | # keep track of how many seconds it takes start_time = time.time() |
How to Define a Python Function that will Load, Iterate and Parse Data from a Text File
The following script show how to use Python’s def keyword to define a function that will open the text file and parse its data, line-by-line, or to order parsing out dictionary entries:
1 2 | # define a function that will parse the text file def get_webster_entries(filename): |
How to open the text file and read its contents
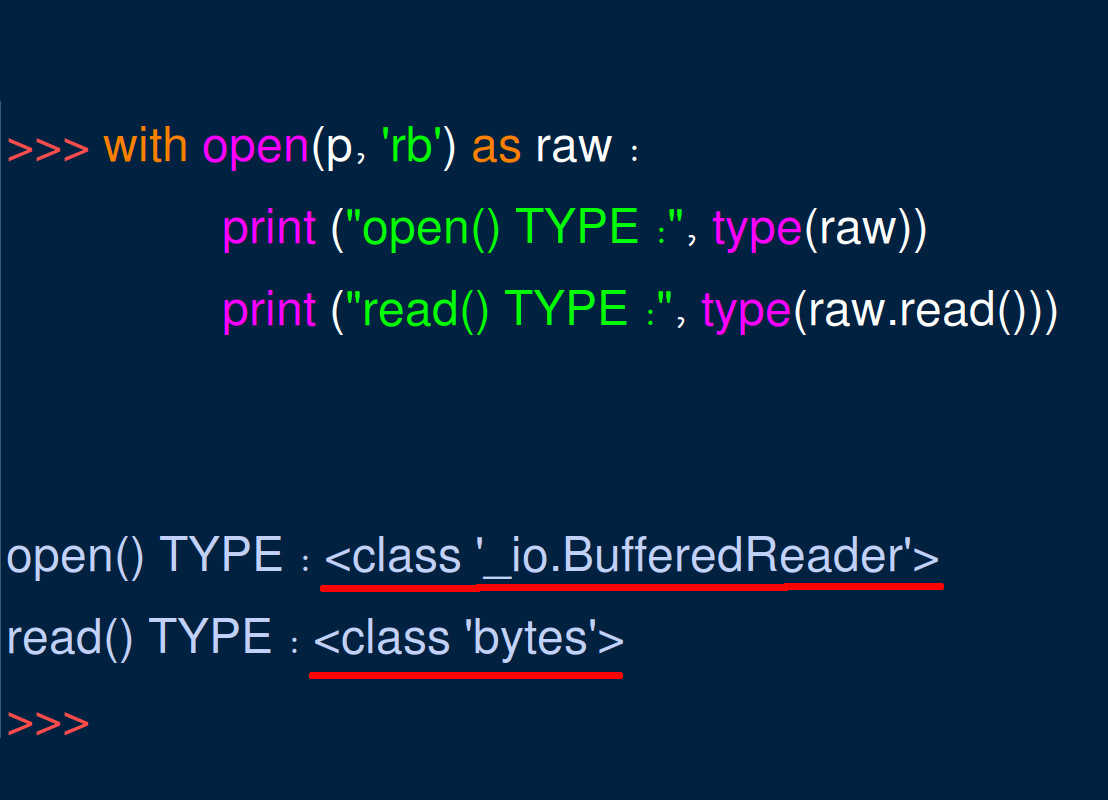
The following script shows how to use Python’s with keyword command to open the text file and have it return an _io.BufferedReader object that can be decoded as a bytes object:
1 2 3 4 | # use the open() function to open the text file with open(filename, 'rb') as raw: # read() method will return a bytes string data = raw.read() |
The following screenshot shows how opening the text file in an indention using with allows Python’s garbage collector to free up the system resources after the BufferedReader object is read.
How to decode the bytes string of the text file using the UTF-8 encoding
Execute the following script to call the bytes object’s decode() method as a UTF-8 encoded string and ignore any encoding errors:
1 2 3 4 5 | # decode the file as UTF-8 and ignore errors data = data.decode("utf-8", errors='ignore') # split the dictionary file into list by: "rn" data = data.split("rn") |
The above script shows how to have the string object’s split() method return its data inside list object ([]) that uses the return key and newline characters ("rn") as its delimiter.
How to make an empty dict for the Webster’s Dictionary entries and definitions
Execute the following script to declare an empty dict object ({}) that will have the dictionary entries added to it and then iterate over the list of string lines from the text file using the enumerate() function:
1 2 3 4 5 | # create an empty Python dict for the entries dict_data = {} # iterate over the list of dictionary terms for num, line in enumerate(data): |
How to parse the line’s string to look for a new dictionary entry
The copy of Webster’s Dictionary used in this tutorial uses an uppercase string to signal a new dictionary entry. Evaluate the string to look for any lines that are completely uppercase so that Python knows to add a new dictionary entry, as shown here:
1 2 3 4 5 6 7 8 9 | try: # entry titles in Webster's dict are uppercase if len(line) < 40 and line.isupper() == True: # reset the definition count def_count = 1 # new entry for the dictionary current = line.title() dict_data[current] = {} |
How to parse the line’s string and evaluate it for dictionary definitions
As shown below, be sure to increment the def_count integer object each time a new definition for the entry is found:
1 2 3 4 5 6 7 8 9 10 11 12 | # add a new definition by looking for "Defn" if "Defn:" in line: # concatenate strings for the definitions def_title = "Defn " + str(def_count) def_content = line.replace("Defn: ", "") # add the definition to the defn title key dict_data[current][def_title] = def_content # add to the definition count def_count += 1 |
Two ways of looking for definitions in the copy of Webster’s Dictionary used in this tutorial
This public domain version of Webster’s Dictionary has two ways it delimits new definitions for a term. The first is it will have "Defn:" at the beginning of the line; the second is it will have a number and a period, e.g. "4.", in the string. Here are some examples:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | # add definition by number and period elif "." in line[:2] and line[0].isdigit(): # concatenate strings for the definitions def_title = "Defn " + str(def_count) def_content = line = line[line.find(".")+2:] # make sure content for definition has some length if len(def_content) >= 10: # add the definition to the defn title key dict_data[current][def_title] = def_content # add to the definition count def_count += 1 |
How to catch errors, set the definition count for each entry and return the dict object
As shown in the following examples, the definition for each count’s value must be updated for each entry after the try-catch indentation end:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | except Exception as error: # errors while iterating with enumerate() print ("nenumerate() text file ERROR:", error) print ("line number:", num) try: # update the number of definitions dict_data[current]["definitions"] = def_count-1 except UnboundLocalError: # ignore errors saying the dict entry hasn't been declared yet pass return dict_data |
NOTE: Make sure to return the complete dict object, containing all of the dictionary entries and definitions, at the end of the function.
How to Call the get_webster_entries() Function to Get all of the Dictionary Entries
Executing the following script will call the function outside of the function indentation:
1 2 | # call the function and return Webster's dict as a Python dict dictionary = get_webster_entries("websters_dictionary.txt") |
NOTE: Make sure to pass a string of the text file’s name and directory path, if it’s not in the same directory as the Python script, to its function call.
How to Create Elasticsearch Document Python Objects for the Dictionary Entries
The function in the above section should have returned a dict object containing all of the text files parsed string data. The next step is to create a Python dict object for each dictionary entry in order to make JSON document objects for the Elasticsearch Bulk API index call.
Execute the following command to set the _id counter and instantiate an empty Python list for the Elasticsearch documents:
1 2 3 4 5 | # variable for the Elasticsearch document _id id_num = 0 # empty list for the Elasticsearch documents doc_list = [] |
How to use the dict object’s items( ) method to iterate over its key-value pairs
Each entry’s list of definitions is nested inside the key for the entry’s title. Execute the following script to begin another items() iteration for the nested key-value pairs that contain the entry’s definitions:
1 2 3 4 5 6 7 8 | # iterate over the dictionary entries using items() for entry, values in dictionary.items(): # dict object for the document's _source data doc_source = {"entry": str(entry)} # iterate over the dictionary values and put them into _source dict for key, item in values.items(): |
The new dict object (doc_source) created inside of the outer key-value iterator is for the Elasticsearch document’s _source data. Be sure to create a new field key, for each definition, in the doc_source object inside the iterator for those definitions.
How to typecast each field’s value so Elasticsearch won’t return any ‘_mapping’ errors
It’s not necessary, nor recommended, to create a _mapping schema for the index beforehand. This is because it would require creating enough definition “fields” for all of the entries. However, the data type must be uniform for each field, in every document. The best way to accomplish this in Python is to explicitly typecast the key’s values, using the str() and int() functions respectively, with the following script:
1 2 3 4 5 6 7 | # make sure to typecast data as string if key != "definitions": doc_source[str(key)] = str(item) # typecast the "definitions" value as an integer else: doc_source["definitions"] = int(item) |
NOTE: Do not create a JSON dictionary object for entries without definitions:
1 2 | # do NOT index the Elasticsearch doc if it has no content if doc_source["definitions"] != 0: |
Make sure to increment the id_num integer counter for the document’s _id, but only if it’s an entry that has some content, as shown here:
1 2 | # incremete the doc _id integer value id_num += 1 |
How to nest the document’s _source data inside of another Python dict
As shown below, the final dict object for the Elasticsearch document will have its _source data nested inside of it with an _id key so Elasticsearch will know what document ID to assign:
1 2 3 4 5 6 7 8 | # Elasticsearch document structure as a Python dict doc = { # pass the integer value for _id to outer dict "_id": id_num, # nest the _source data inside the outer dict object "_source": doc_source, } |
NOTE: The Python dictionary object’s _id key can be omitted and Elasticsearch will dynamically generate an alpha-numeric _id for each document.
How to append the nested Python dict Elasticsearch document to the list
Execute the following code to append the nested dict object, representing an Elasticsearch document, to the list object instantiated earlier:
1 2 | # append the nested doc dict values to list doc_list += [ doc_source ] |
This list object will be passed to the Elasticsearch library’s bulk() method after the iteration is complete so it can index all of the documents.
How to Index the Webster’s Dictionary Entries as Elasticsearch Documents using the Python Client
Execute the following script to declare a new client instance of the low-level Elasticsearch library, taking care to pass the correct values to its string parameter for the cluster:
1 2 | # declare a client instance of the Python Elasticsearch client library client = Elasticsearch("http://localhost:9200") |
How to call the Elasticsearch “helpers” library’s bulk( ) method to index the list of Python documents
Execute the following script to pass the client instance, and the Python list of Elasticsearch documents, to the helpers.bulk() method call and have it return a response:
1 2 3 4 5 6 | # attempt to index the dictionary entries using the helpers.bulk() method try: print ("nAttempting to index the dictionary entries using helpers.bulk()") # use the helpers library's Bulk API to index list of Elasticsearch docs response = helpers.bulk(client, doc_list, index='websters_dict', doc_type='_doc') |
NOTE: The Elasticsearch document type has been deprecated since version 6.0 of Elasticsearch. Just pass the string "_doc" to the doc_type parameter to get around this issue. Also, be sure to pass a string value to the index parameter so that Elasticsearch knows the index name these documents will be added to.
How to use Python’s JSON Library to Print the API Response Returned to Elasticsearch
Execute the following script to use the dumps() method call in Python’s built-in json library. This will print the JSON response, returned by the API call to the Elasticsearch cluster, with some indentation to make it more readable:
1 2 3 4 5 6 7 | # print the response returned by Elasticsearch print ("helpers.bulk() RESPONSE:", json.dumps(response, indent=4)) Except `Exception` as err: # print any errors returned by the Elasticsearch cluster print("helpers.bulk() ERROR:", err) |
Make certain to get the time difference between the end and the start of the script, to see how many seconds have elapsed, by adding the following code to the end of the script:
1 2 | # print the time that has elapsed since the start of the script print ("time elapsed:", time.time()-start_time) |
How to Run the Python Script and Wait for a Response to the Bulk API to Elasticsearch
Make sure to save any changes in an IDE or text editor and then run the Python script in a terminal or command prompt window, from the script’s directory, by executing the following command:
1 | python3 bulk_index_text.py |
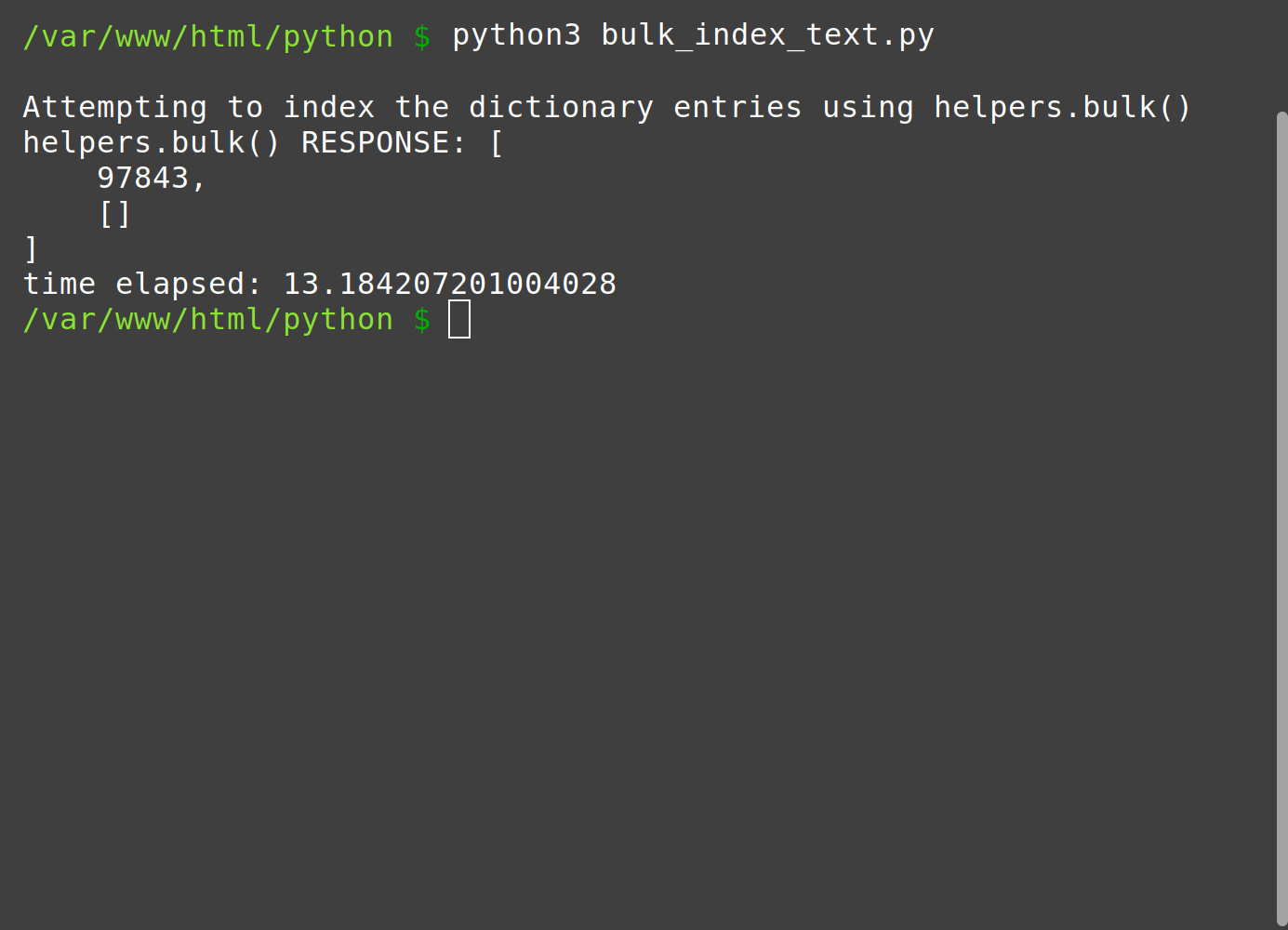
The entire execution run-time for the Python script, including the API response from the Elasticsearch, may take around 30 seconds. However, it may take longer depending on how large the text file is and how many documents are being indexed with the bulk() method call. An example with the run time is as follows:
1 2 3 4 5 6 | Attempting to index the dictionary entries using helpers.bulk() helpers.bulk() RESPONSE: [ 97843, [] ] time elapsed: 26.252054929733276 |
As shown in the above example, the script ran for over 26 seconds as it attempted to upload and index almost 100k documents to an Elasticsearch index. Following is a screenshot:
How to use Kibana to verify that the Webster Dictionary documents successfully indexed
If the Kibana service is installed and running on the Elasticsearch cluster, it can make an HTTP request that can query different entries in the dictionary index.
The following is a GET request that looks for all of the Webster Dictionary’s entries that have three definitions:
1 2 3 4 5 6 7 8 | GET websters_dict/_search?size=50 { "query": { "match" : { "definitions": 3 } } } |
Following is a screenshot:
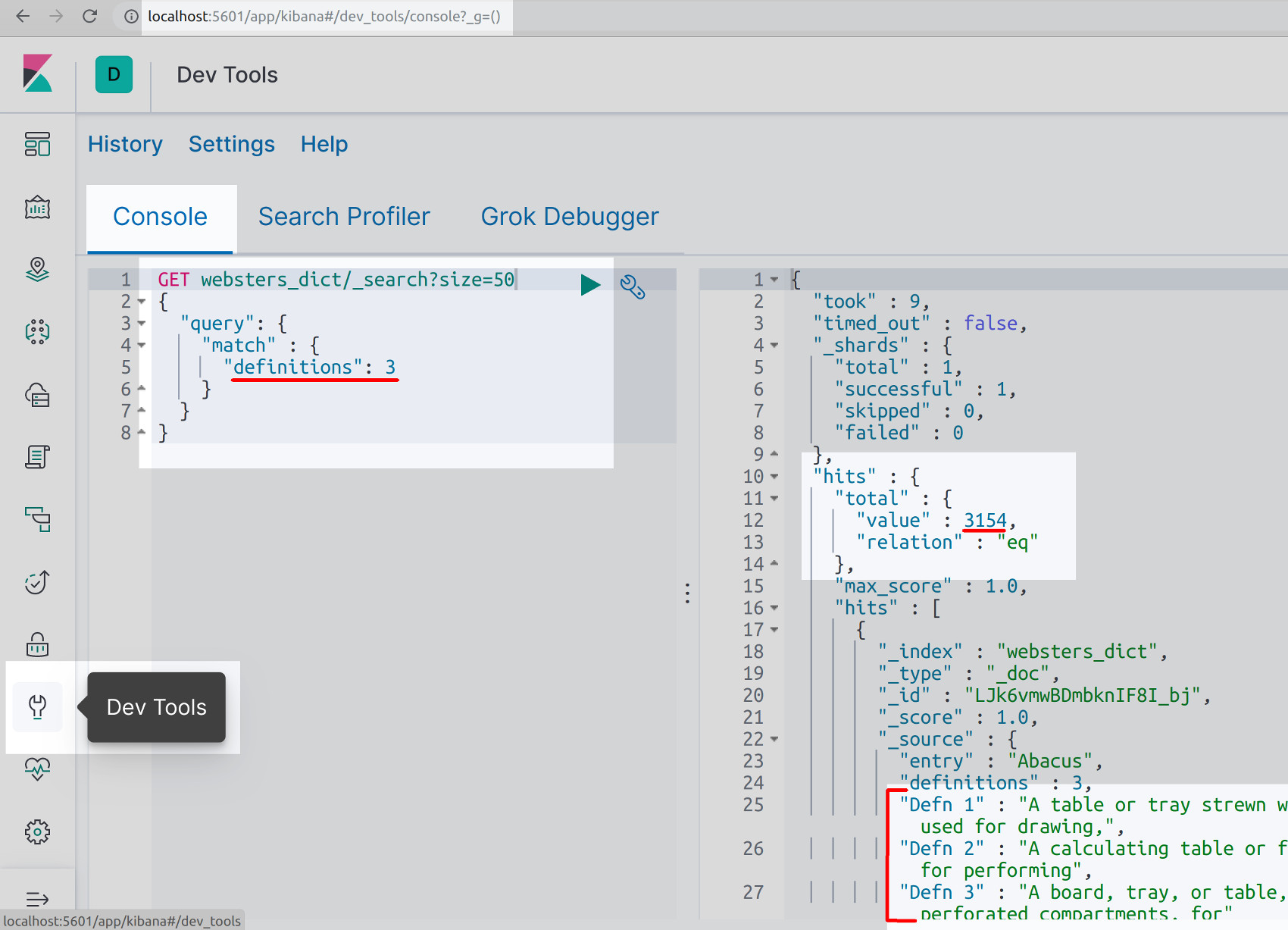
NOTE: By default, Kibana and Elasticsearch will only return up to 10 document "hits" in its JSON response to _search queries. When necessary, use the ?size= parameter in the REST header to instruct Elasticsearch to return more than 10 documents.
Indexing dictionary entries to an Elasticsearch index, using queries to look up definitions for terms, is a great way to build a database for a dictionary web, mobile or desktop GUI application.
Conclusion
This tutorial demonstrated how to open a text file in Python and iterate the data to parse and create Elasticsearch documents. The article specifically explained how to import the necessary Python and Elasticsearch libraries, use Python’s time library and define a Python Function to load, iterate and parse data. The tutorial also explained how to decode the bytes string of the text file, how to make an empty dict for the Webster’s Dictionary entries and definitions, how to catch errors and set the definition count for each entry and return the dict object. Finally, the tutorial covered how to index the Webster’s Dictionary entries as Elasticsearch documents using the Python client, print the API response returned to Elasticsearch and use Kibana to verify the Webster Dictionary documents were successfully indexed. Remember that to legally parse line-by-line in a text file index for Elasticsearch documents with Python bulk, the rights to the content being inserting into a MongoDB collection must be owned by the user or inserted with permission from the owner.
Just the Code
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 | #!/usr/bin/env python3 #-*- coding: utf-8 -*- # import Python's pickle library to serialize the dictionary import pickle # import Python's time and JSON library import time, json # use the elasticsearch client's helpers class for _bulk API from elasticsearch import Elasticsearch, helpers # keep track of how many seconds it takes start_time = time.time() # define a function that will parse the text file def get_webster_entries(filename): # use the open() function to open the text file with open(filename, 'rb') as raw: # read() method will return a bytes string data = raw.read() # decode the file as UTF-8 and ignore errors data = data.decode("utf-8", errors='ignore') # split the dictionary file into list by: "rn" data = data.split("rn") # create an empty Python dict for the entries dict_data = {} # iterate over the list of dictionary terms for num, line in enumerate(data): try: # entry titles in Webster's dict are uppercase if len(line) < 40 and line.isupper() == True: # reset the definition count def_count = 1 # new entry for the dictionary current = line.title() dict_data[current] = {} # add a new definition by looking for "Defn" if "Defn:" in line: # concatenate strings for the definitions def_title = "Defn " + str(def_count) def_content = line.replace("Defn: ", "") # add the definition to the defn title key dict_data[current][def_title] = def_content # add to the definition count def_count += 1 # add definition by number and period elif "." in line[:2] and line[0].isdigit(): # concatenate strings for the definitions def_title = "Defn " + str(def_count) def_content = line = line[line.find(".")+2:] # make sure content for definition has some length if len(def_content) >= 10: # add the definition to the defn title key dict_data[current][def_title] = def_content # add to the definition count def_count += 1 except Exception as error: # errors while iterating with enumerate() print ("nenumerate() text file ERROR:", error) print ("line number:", num) try: # update the number of definitions dict_data[current]["definitions"] = def_count-1 except UnboundLocalError: # ignore errors saying the dict entry hasn't been declared yet pass return dict_data # call the function and return Webster's dict as a Python dict dictionary = get_webster_entries("websters_dictionary.txt") # variable for the Elasticsearch document _id id_num = 0 # empty list for the Elasticsearch documents doc_list = [] # iterate over the dictionary entries using items() for entry, values in dictionary.items(): # dict object for the document's _source data doc_source = {"entry": str(entry)} # iterate over the dictionary values and put them into _source dict for key, item in values.items(): # make sure to typecast data as string if key != "definitions": doc_source[str(key)] = str(item) # typecast the "definitions" value as an integer else: doc_source["definitions"] = int(item) # do NOT index the Elasticsearch doc if it has no content if doc_source["definitions"] != 0: # incremete the doc _id integer value id_num += 1 # Elasticsearch document structure as a Python dict doc = { # pass the integer value for _id to outer dict "_id": id_num, # nest the _source data inside the outer dict object "_source": doc_source, } # append the nested doc dict values to list doc_list += [ doc_source ] # declare a client instance of the Python Elasticsearch client library client = Elasticsearch("http://localhost:9200") # attempt to index the dictionary entries using the helpers.bulk() method try: print ("nAttempting to index the dictionary entries using helpers.bulk()") # use the helpers library's Bulk API to index list of Elasticsearch docs response = helpers.bulk(client, doc_list, index='websters_dict', doc_type='_doc') # print the response returned by Elasticsearch print ("helpers.bulk() RESPONSE:", json.dumps(response, indent=4)) except Exception as err: # print any errors returned by the Elasticsearch cluster print("helpers.bulk() ERROR:", err) # print the time that has elapsed since the start of the script print ("time elapsed:", time.time()-start_time) |



Pilot the ObjectRocket Platform Free!
Try Fully-Managed CockroachDB, Elasticsearch, MongoDB, PostgreSQL (Beta) or Redis.
Get Started