How To Iterate The Results Of An Elasticsearch Search Query Using Python
Introduction
If you’re planning to use Python to communicate with Elasticsearch, you’ll find that it’s easy to create a search query and get your results returned. However, it’s important to remember that you’ll have to loop through your set of results in order to access each individual document and its fields. Fortunately, accomplishing that task is quite simple as well with the help of Python’s built-in iterators and generators. In this step-by-step tutorial, we’ll explain how to iterate the results of an Elasticsearch search query using Python.
Prerequisites
Before we dive into some Python code, it’s important to make sure certain prerequisites are in place. For this task, there are a few key system requirements:
First, you need to make sure your Elasticsearch cluster is running. To confirm this, you can execute
curl -XGET localhost:9200in a terminal or command prompt window. You’ll also need to have at least a few documents stored in an index that you can use to make query requests on.Python and the low-level Python client for Elasticsearch both need to be installed. It’s recommended that you use Python 3, because Python 2 is scheduled for deprecation. You can install the
elasticsearchlibrary for Python using PIP:
1 | pip3 install elasticsearch |
- Next, you’ll need to install Python’s Requests library, if you haven’t done so already:
1 | pip3 install requests |
- Finally, it’s helpful to have a reasonable understanding of Python syntax, including the use of Python iterators.
Connect to an Elasticsearch cluster in Python
Once you’ve confirmed that all the system requirements are in place, you’re ready to dig into some Python code. To get started, edit a Python script on the server that’s running your Elasticsearch cluster. Python scripts always have the .py file extension regardless of the version of Python you’re running.
Import all of the Python modules needed to make Elasticsearch requests
Be sure to import the appropriate modules or libraries at the beginning of your script, as shown below:
1 2 3 4 5 | #!/usr/bin/env python3 #-*- coding: utf-8 -*- from elasticsearch import Elasticsearch import requests |
At this point, it’s a good idea to save and run your script to check for any ImportError that Python might raise. If you see one, it’s probably because the Requests library or the Elasticsearch client wasn’t installed properly.
Create a new client instance of the Elasticsearch library
If everything imported correctly in your script, you can now instantiate a Python object of the Elasticsearch client library. We’ll be using the client’s .search() method to make requests to an Elasticsearch index:
1 | elastic_client = Elasticsearch() |
You may also optionally pass the domain for the Elasticsearch server into the hosts parameter:
1 | elastic_client = Elasticsearch(hosts=["SOME_DOMAIN"]) |
Make a Python query to an index on the Elasticsearch cluster
We can make an Elasticsearch Search API request by calling the elastic_client.search() method. It’s a good idea to create a new Python dictionary with the query parameters for the search request beforehand, as shown in the example below:
1 2 3 4 5 6 7 8 | # this will search for car documents with a 'make' of 'Honda': search_dict = { 'query': { 'match': { 'make': 'Honda' } } } |
Next, all you have to do is pass that entire dictionary as a parameter when calling the method:
1 2 3 4 | response = elastic_client.search(index="cars", body=search_dict) # print the request's response to terminal print (response) |
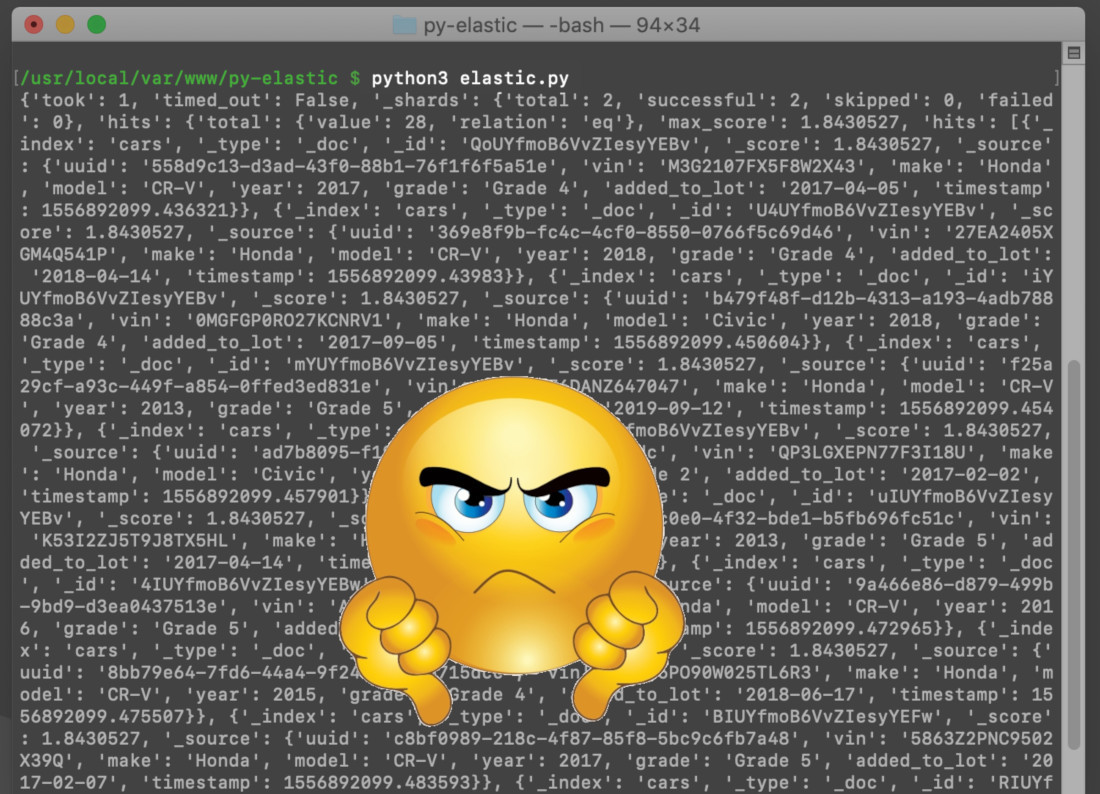
If you run the script at this point, you’ll see that it just returns a huge block of text, depending how many "hits" the search query returned. The next step in our process will involve iterating through this block of results so we can make some sense of them.
Elasticsearch returns an incomprehensible block of text as a response to a search query made in Python:
Use Python’s Type() function on the Elasticsearch response
Before we can parse through and iterate this block of data, we first need to know what type of data it is, so we can use the appropriate methods.
Exactly what kind of data does the Python client return?
Python has a built-in function called type() that returns a <class 'type'="'type'"> of the Python data it’s evaluating.
You can use this function on any Python object or variable, including Elasticsearch data returned by a request, to determine what kind of data it is. Append the following code to the end of your script to see what Elasticsearch returns:
1 2 | print ("response object's data type:", type(response)) # should return: "<class 'dict'="'dict'">" |
When you make a request to Elasticsearch using the Python client, it returns a nested Python dictionary. Requests made to Elasticsearch will return a dictionary with a key of 'hits'.
Inside of that dictionary should be another "hit" dictionary that contains a Python ‘list’ containing even more dictionaries, each one representing an Elasticsearch document:
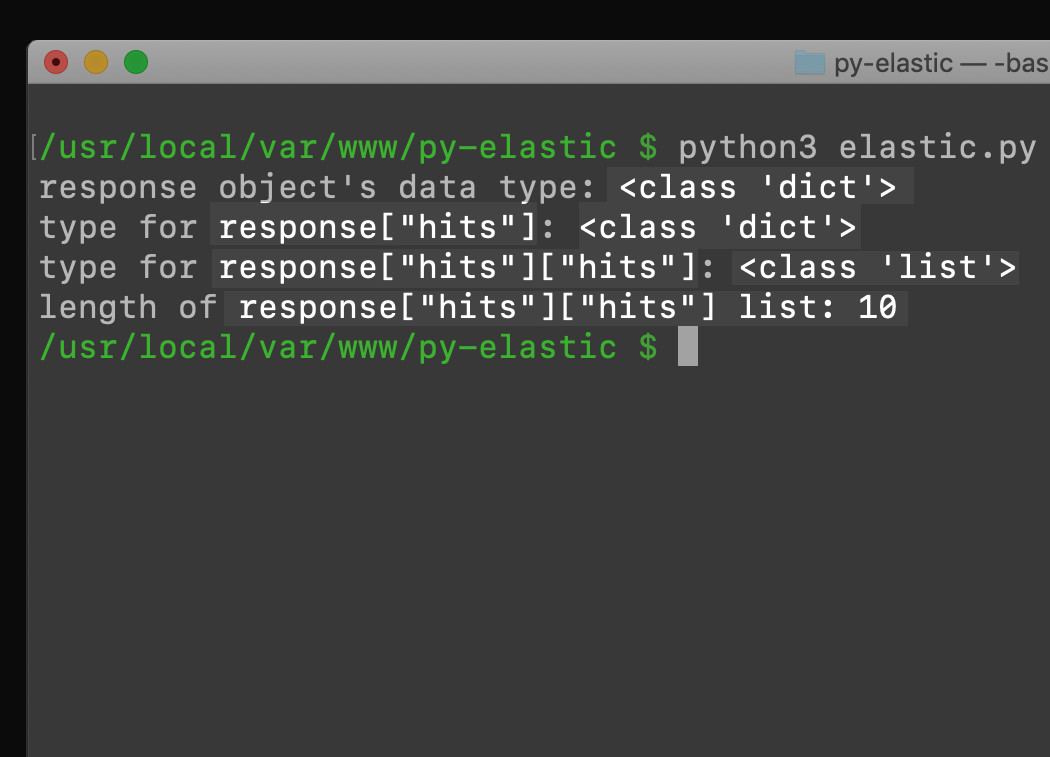
1 2 3 4 5 6 7 8 9 10 11 12 | print ("response object's data type:", type(response)) print ('type for response["hits"]:', type(response['hits'])) print ('type for response["hits"]["hits"]:', type(response["hits"]["hits"])) print ('length of response["hits"]["hits"] list:', len(response["hits"]["hits"])) ''' RETURNS: response object's data type: <class 'dict'="'dict'"> type for response["hits"]: <class 'dict'="'dict'"> type for response["hits"]["hits"]: <class 'list'="'list'"> length of response["hits"]["hits"] list: 10 ''' |
Print the data type() of an Elasticsearch query response in Python:
Iterate the 'hits' list returned by Elasticsearch using Python’s Enumerate() method
Now it’s time to iterate our 'hits' list using Python’s enumerate() method. Return to the script again and store the 'hits' Python list in a variable:
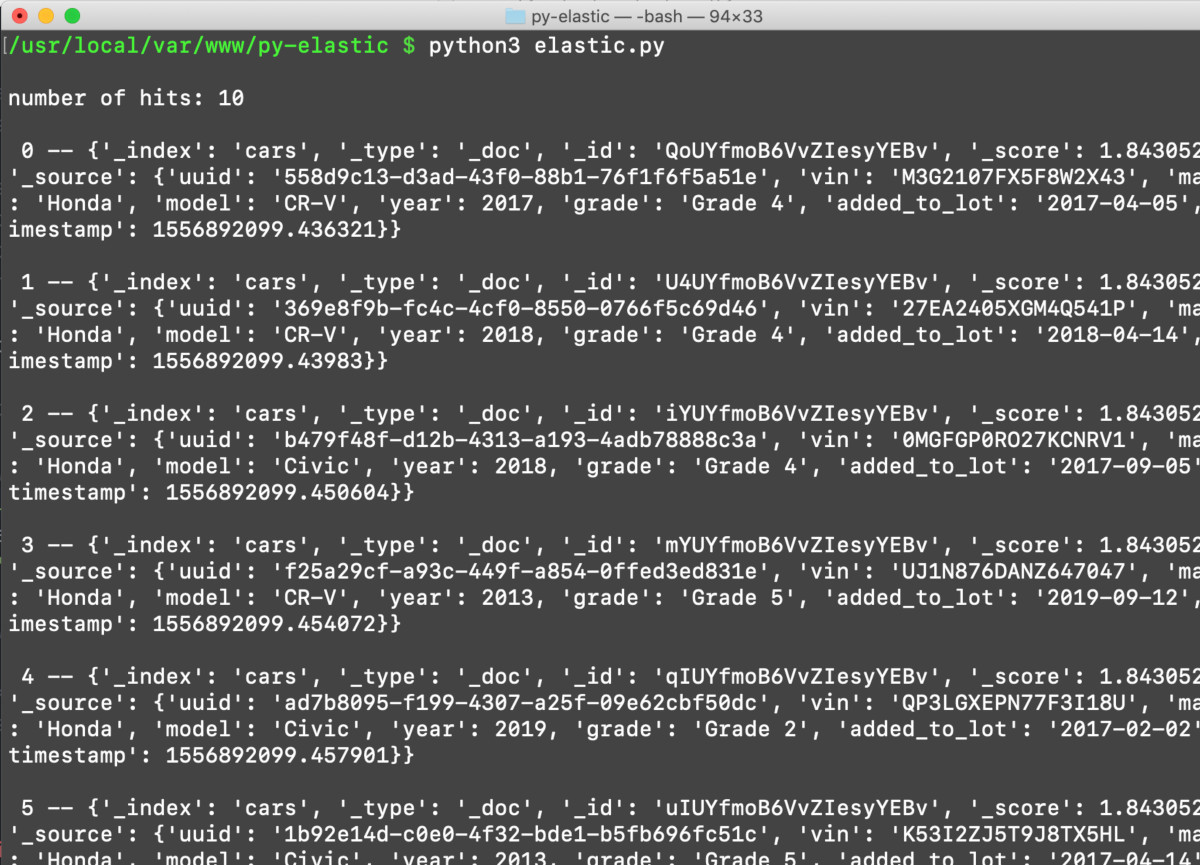
1 2 3 4 5 6 7 8 9 10 | ''' Store the list inside the returned nested dictionary in another variable ''' response_hits = response['hits']['hits'] print ('\nnumber of hits:', len(response_hits)) # use enumerate() to iterate list of documents: for num, doc in enumerate(response_hits): print ('\n', num, '--', doc) |
Use Python’s enumerate() method to iterate the list that Elasticsearch returned:
Access an Elasticsearch document’s field
You can access a document’s fields by accessing the dictionary’s keys, as seen in the example below:
1 2 3 4 5 6 7 8 9 10 11 12 13 | # use enumerate() to iterate a list of documents: for num, doc in enumerate(response_hits): print ('\num:', num, '-->', doc) # get the document ID doc_id = doc['_id'] print ('_id:', doc_id) # get the document's '_source' print ('_source:', doc['_source']) # get the car's VIN number print ('VIN:', doc['_source']['vin']) |
Conclusion
When you use Python to query Elasticsearch, the returned results will take the form of a Python nested dictionary made up of Elasticsearch documents. It’s important to know how to loop through these results; in this case, using the enumerate() method is the fastest and easiest way to accomplish this task. Armed with the instructions in this article, you’ll have no problem iterating the results of an Elasticsearch search query using Python.
In this article, we looked at the example code one section at a time. Here’s the complete code for iterating the results of an Elasticsearch query:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 | #!/usr/bin/env python3 #-*- coding: utf-8 -*- # import the modules from elasticsearch import Elasticsearch import requests # instantiate a client instance of Elasticsearch elastic_client = Elasticsearch() # this will search for car documents with a 'make' of 'Honda': search_dict = { 'query': { 'match': { 'make': 'Honda' } } } response = elastic_client.search(index="cars", body=search_param) ''' Store the list inside the returned nested dictionary in another variable ''' response_hits = response['hits']['hits'] print ('\n', number of hits:', len(response_hits)) # use enumerate() to iterate list of documents: for num, doc in enumerate(response_hits): print ('\n', num:', num) # get the document ID doc_id = doc['_id'] print ('_id:', doc_id) # get the document's '_source' print ('_source:', doc['_source']) # get the car's VIN number print ('VIN:', doc['_source']['vin']) |

Pilot the ObjectRocket Platform Free!
Try Fully-Managed CockroachDB, Elasticsearch, MongoDB, PostgreSQL (Beta) or Redis.
Get Started