How to Index Elasticsearch Documents Using the Python Client Library
Introduction
This article will provide an overview on how to index Elasticsearch documents using python. It will also provide examples on how to create a nested JSON document and use Kibana to verify the document when indexing Elasticsearch documents using python.
NOTE: To prevent namespace conflicts with the built-in Python keywords, the Elasticsearch client make use of from_ instead of from, and doc_type instead of type for parameters when creating API calls.
Refer to the official API documentation for additional information.
Prerequisites
- Python and its low-level Python client library must be installed on your machine.
- Python 3 is recommended, as Python 2 is depreciating by 2020. As the illustrations in this tutorial use Python 3, there may be compatibility issues if trying to run the given code with Python 2.
- Ensure that Elasticsearch is running correctly. In cURL you can check this by performing a
GETrequest:
1 2 | curl -XGET http://localhost:9200/ # you may need to modify your IP address and port. |
Alternatively, you can use Python’s request library to confirm the server is running Elasticsearch:
1 2 3 | import requests; res = requests.get('http://localhost:9200'); print(res.content) |
- There should already be an Elasticsearch index created that you should be able to index documents into. The following cURL request can be used to obtain a full list of the indexes:
1 | curl -XGET localhost:9200/_cat/indices?v |
- If you want to set up a custom UUID for the document’s
id, like the example in this tutorial, you will need to import the Pythonuuidmodule. The head of the script should resemble this:
1 2 3 4 5 | #!/usr/bin/env python3 #-*- coding: utf-8 -*- from Elasticsearch import Elasticsearch import uuid |
Creating a nested JSON document
Elasticsearch uses JSON objects for both passing data and in making its API responses. Therefore, it is a good idea to familiarize yourself with the way the Elasticsearch indexes and documents are arranged.
Below is the standard layout of an Elasticsearch document. It is basically a nested JSON object with metadata regarding the index containing the document’s data in the
"doc"field (or “key” as they’re called in a Python dictionary):
1 2 3 4 5 6 7 8 9 10 11 | { "_index" : "employees", "_id" : "12345", "doc_type" : "person", "doc": { "name" : "George Peterson", "sex": "male", "age": "34", "years": "10" } } |
However, when indexing an Elasticsearch document using a Python dictionary, you don’t need all of the “meta” data for the index contained in the JSON document itself. This is because that information gets passed as parameters when the client’s
indexmethod is invoked.Here is what that same JSON document should look like when it is represented as a Python dictionary object (before it gets passed to the
indexmethod) callednew_employee:
1 2 3 4 5 6 | new_employee = { "name": "George Peterson", "sex": "male", "age": "34", # use "" if this is meant to be a text _type "years": "10" # use "" if this is meant to be a text _type } |
The Index Method’s API Call
Passing the optional id parameter
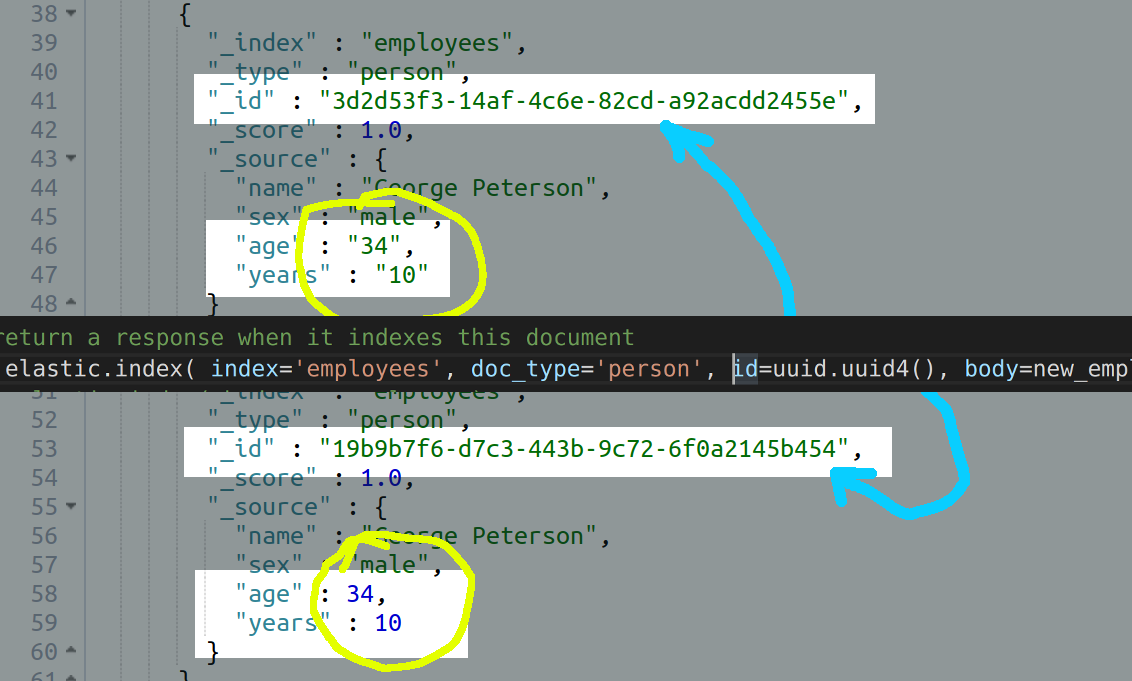
- Here is an example of an
indexAPI call, returning a response that passes the dictionary object for the document’s body and a randomly-generated UUID as the Elasticsearch document’s"_id":
1 2 3 4 5 6 7 | # have ES return a response when it indexes this document response = elastic.index( index = 'employees', doc_type = 'person', id = uuid.uuid4(), body = new_employee ) |
- Here is the same document body with the
"age"and"years"fields passed as integer-data types, instead of"text” (formerly"string") data types:
1 2 3 4 5 6 | new_employee = { "name": "George Peterson", "sex": "male", "age": 34, # this is now an integer data type "years": 10 # this is now an integer data type } |
NOTE: If a document’s data field is mapped as an “integer” it should not be enclosed in quotation marks ("), as in the "age" and "years" fields in this example. Note that if the field’s value is placed inside quotation marks then Elasticsearch will index that field’s datum as if it were a "text" data type:
Use Kibana to verify the document
- Open up the Kibana Console UI in your browser (typically located at
https://{YOUR_DOMAIN}:5601/app/kibana#/dev_tools/consoleor http://localhost:5601/app/kibana#/dev_tools/console
If the service isn’t running, type sudo service kibana start into your Linux terminal.
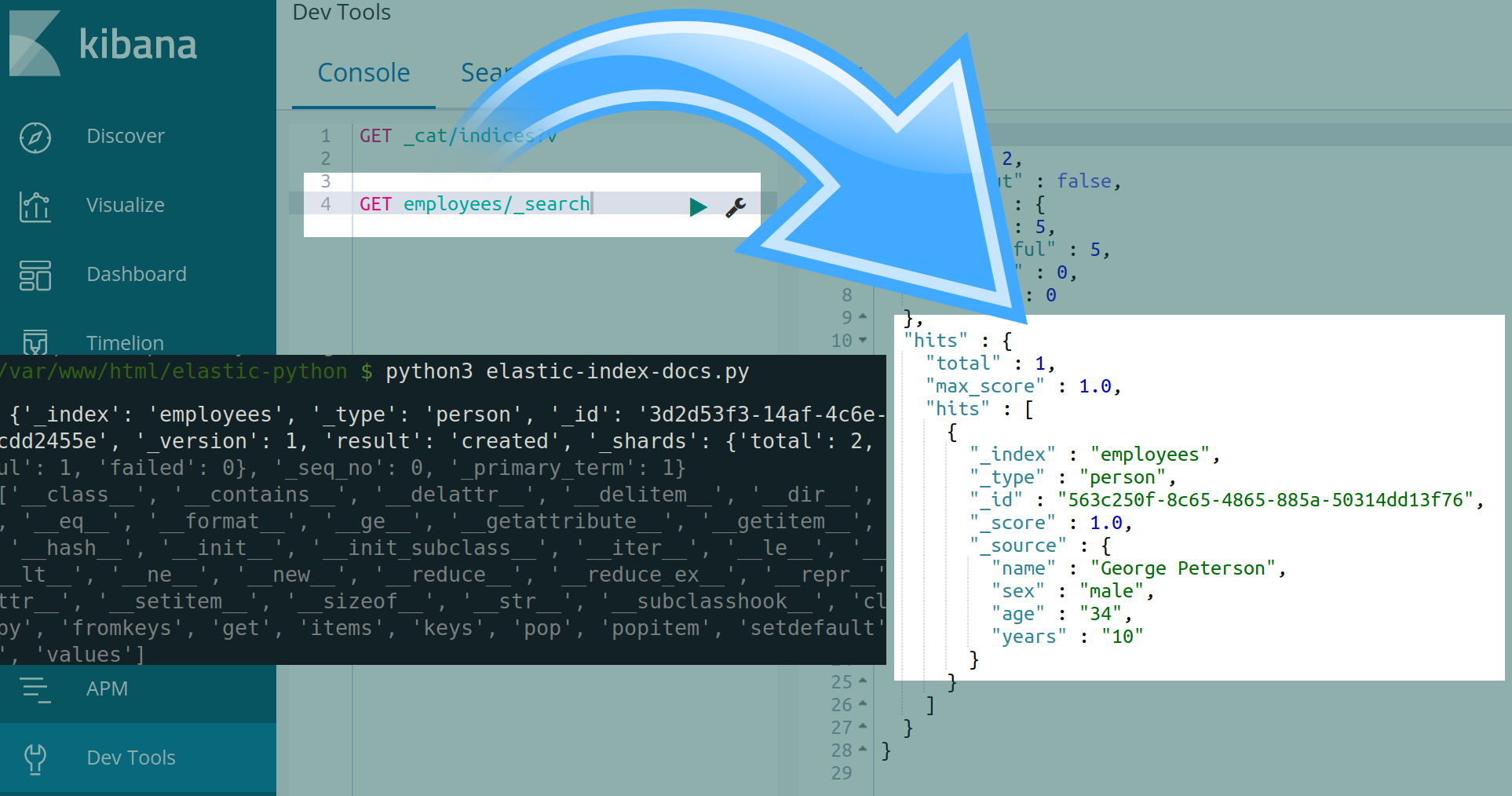
- Use this
GETrequest to view the index’s documents:
1 | GET employees/_search |
Dynamically created Elasticsearch document “_id”
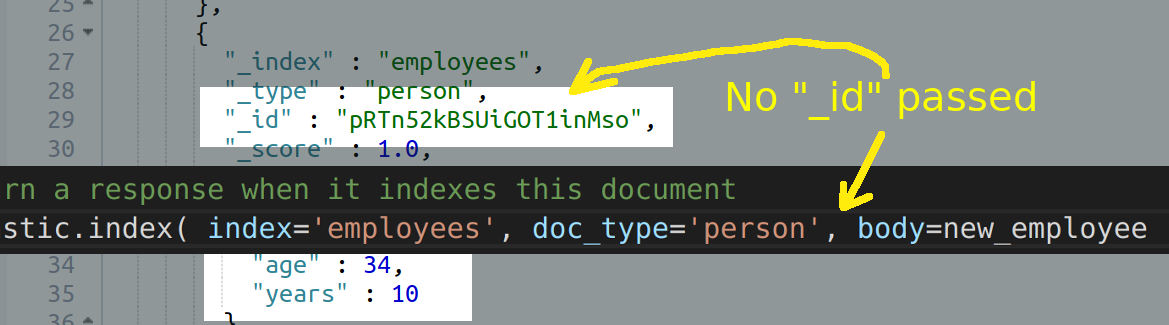
In the prior example, the Python code uses the integrated
uuidlibrary to create a unique UUID for the document’s"_id".It is important to note that if the API call doesn’t explicitly pass an
idfor the newly-created document the Elasticsearch cluster will dynamically create an alpha-numeric ID for it.
Indexing without passing an “_id” parameter
1 | response = elastic.index(index='employees', doc_type='person', body=new_employee) |
Print the index response
It is good to get into the habit of getting a verified the response returned when making these kinds of API calls.
Unlike other languages, like PHP, Python allows you to print out to console any object in Python without explicitly serializing it first:
1 2 | print ("\n", response) print (dir(response)) |
The dir function will print out all of the methods and attributes of any object in Python.
Here is what the response object ought to return if the document indexing was successful:
1 | {'_index': 'employees', '_type': 'person', '_id': 'pRTn52kBSUiGOT1inMso', '_version': 1, 'result': 'created', '_shards': {'total': 2, 'successful': 1, 'failed': 0}, '_seq_no': 1, '_primary_term': 1} |
Conclusion
- One major advantage of the approach outlined in this tutorial to index Elasticsearch documents using python is that the same technique can be used to scale the data sets up or down. Bear in mind, every time you employ the
indexmethod, even if the data has not changes since the last time the document was indexed, the program will create a new document with an identical document structure and body as the previous version. As a result, it is important to remember that this has the potential to create an unlimited number of duplicate documents in the index.

Pilot the ObjectRocket Platform Free!
Try Fully-Managed CockroachDB, Elasticsearch, MongoDB, PostgreSQL (Beta) or Redis.
Get Started