How to Fetch Data from the Internet and Index it into Elasticsearch Documents using Python
Introduction
Elasticsearch can be used to search and link to external web sources, such as Wikipedia, and index the data as Elasticsearch documents. This tutorial will demonstrate how to use Python’s built-in urllib3 package library for Python 3 to get data from the internet to index Elasticsearch documents to fetch Wikipedia titles and URLs and how to index that data as Elasticsearch documents.
Prerequisites for using Python’s Built-in urllib3 Package Library for Python 3 to get Data from the Internet to Index Elasticsearch Documents using Python
- While the
urllib3library comes included with Python 3, the Elasticsearch low-level client does not. The PIP3 package manager can be used to install the client for Python with the following command:
1 | pip3 install elasticsearch |
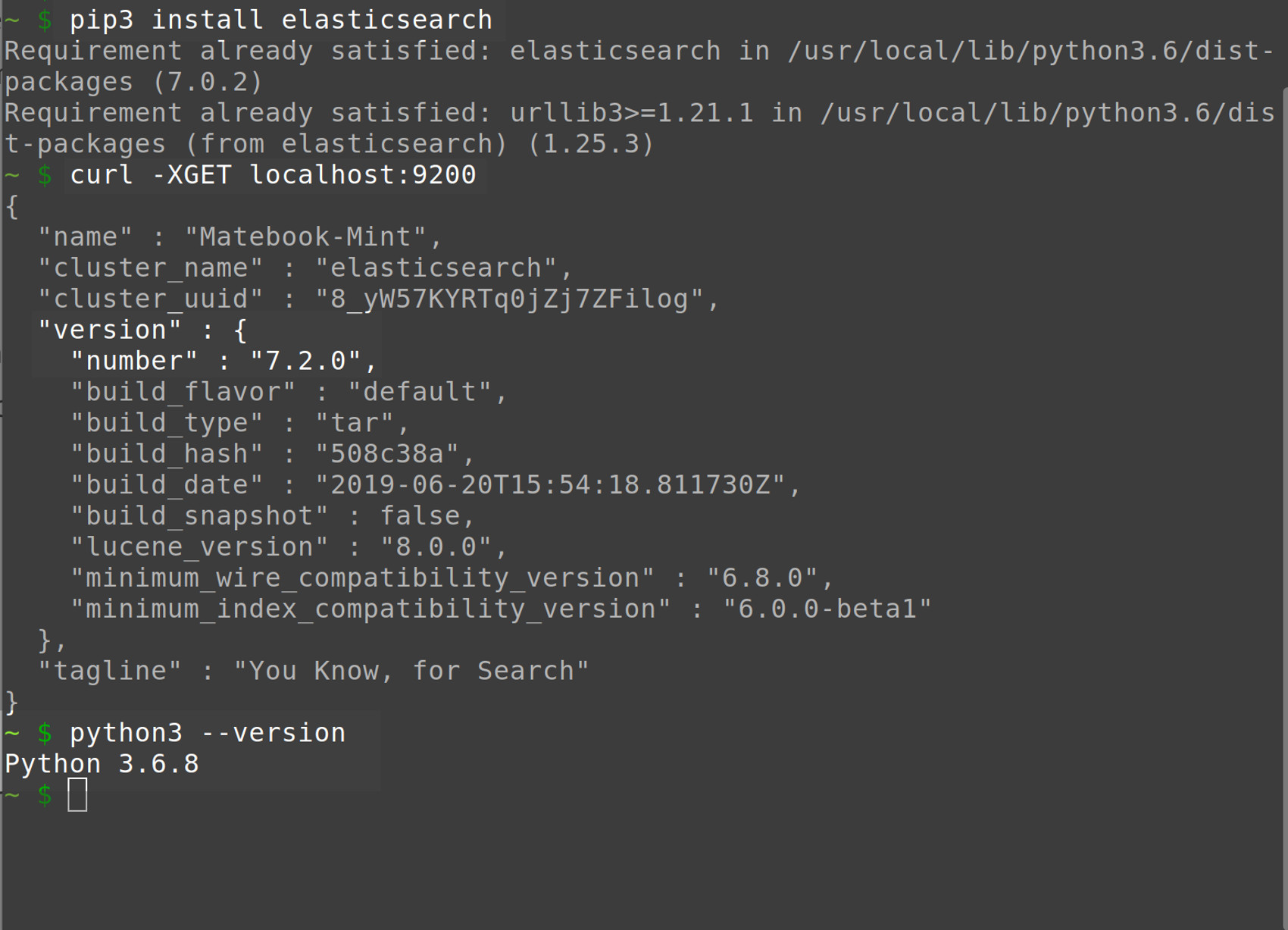
- The Elasticsearch cluster must be running. Execute the following cURL request to verify the cluster is running and to obtain its version number:
1 | curl -XGET localhost:9200 |
The result should resemble the following:
How to Import the Urllib3 and Elasticsearch Packages
Make sure to import the Elasticsearch and Urllib3 package library’s at the beginning of the Python script:
1 2 3 4 5 | # import the urllib package for Python 3 import urllib3 # import the Elasticsearch low-level client library from elasticsearch import Elasticsearch |
How to instantiate a client instance of the Python low-level Elasticsearch library
Instantiate a client instance with the following code, and make sure to pass the correct hosts string, that match your Elasticsearch cluster, to the method call:
1 2 | # domain name, or server's IP address, goes in the 'hosts' list client = Elasticsearch(hosts=["localhost:9200"]) |
How to Define a Python Function to Fetch HTML Data using urllib3
Declare a function that will fetch HTML data and return it as a decoded UTF-8 string using the urllib3 library :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | # declare a function that will return a webpage's HTML as a string def fetch_data(url): # catch any errors and print/return them try: # get the HTTP urllib3.connectionpool.HTTPSConnectionPool object http_pool = urllib3.connection_from_url(url) # returns a urllib3.response.HTTPResponse object resp = http_pool.urlopen('GET', url) # decode the HTML data using UTF-8 decoded = resp.data.decode('utf-8') except Exception as err: print ("fetch_data() ERROR", err) decoded = "fetch_data() ERROR" + str(err) # return the urllib response or any errors return decoded |
How to Parse and Slice the HTML String Data Returned by urllib3
The below code will define a function in the Python script that will splice the HTML string using certain “markers.” This is accomplished by iterating over a list of HTML lines, creating sub-strings in the process, and by removing the HTML tags in order to parse-out the article title and URL string data.
Declare another function that will parse and slice the HTML string data:
1 2 3 4 | # iterate, slice, and parse HTML string data def parse_html(data, marker, start, end): # iterate the list of HTML data for line in data: |
How to verify that the HTML marker is in the line iteration
Verify that the target marker sub-string in in the line and then look for the start and endpoints for the data that needs to get parsed out of it:
1 2 3 4 5 6 | # make sure the HTML string contains marker if marker in line: line = line[line.find(marker):] # check if the start and end data is in line if (start in line) and (end in line): |
How to use Python’s find( ) function to get the start and end location of the target string slice
Use the following code to get a target slice from the data line using Python’s built-in find() function and then return the string slice:
1 2 3 4 5 6 7 8 9 | # find where the target data starts and ends s = line.find(start) + len(start) e = line.find(end) # return the sliced string return line[s : e] # return empty string by default return "" |
NOTE: The function will return an empty string if the target string slice cannot be found in the web page.
How to Declare a URL String for Wikipedia Articles and Fetch the Data
Execute the following code to create a variable for the Wikipedia URL string outside of the declared functions and pass it to the fetch_data() function declared earlier:
1 2 3 4 5 | # declare a URL string for the urllib to parse url = "https://en.wikipedia.org/wiki/Wikipedia:Vital_articles/Level/1" # pass the URL string to the fetch_data() function source = fetch_data(url) |
How to use Python’s split( ) function to return the HTML data as a list
Use the following code to break up the entire HTML from the web page using split() delimiting each line of string in the list by its newline character (\n):
1 2 3 4 5 | # use Python's split() method to put lines of HTML into a list [] source = source.split("\n") # "\n" == linebreak # print the number of HTML lines returned by urllib print ("Lines to iterate:", len(source)) |
The parse_html() function declared above requires that a Python list object ([]) be passed to it. Here use the string’s split() method to return a list of all the lines of HTML in the web page.
How to Call the parse_html( ) Function and get the Macro Topic for the Wikipedia Articles
This section will cover how to get the main topic that all of the Wikipedia articles belong to by passing a list of the HTML data from the Wikipedia article page to the parse_html() function.
How to view the web page’s source data
Right-click anywhere on the Wikipedia website’s Level 1 vital articles page shown in the following screenshot:
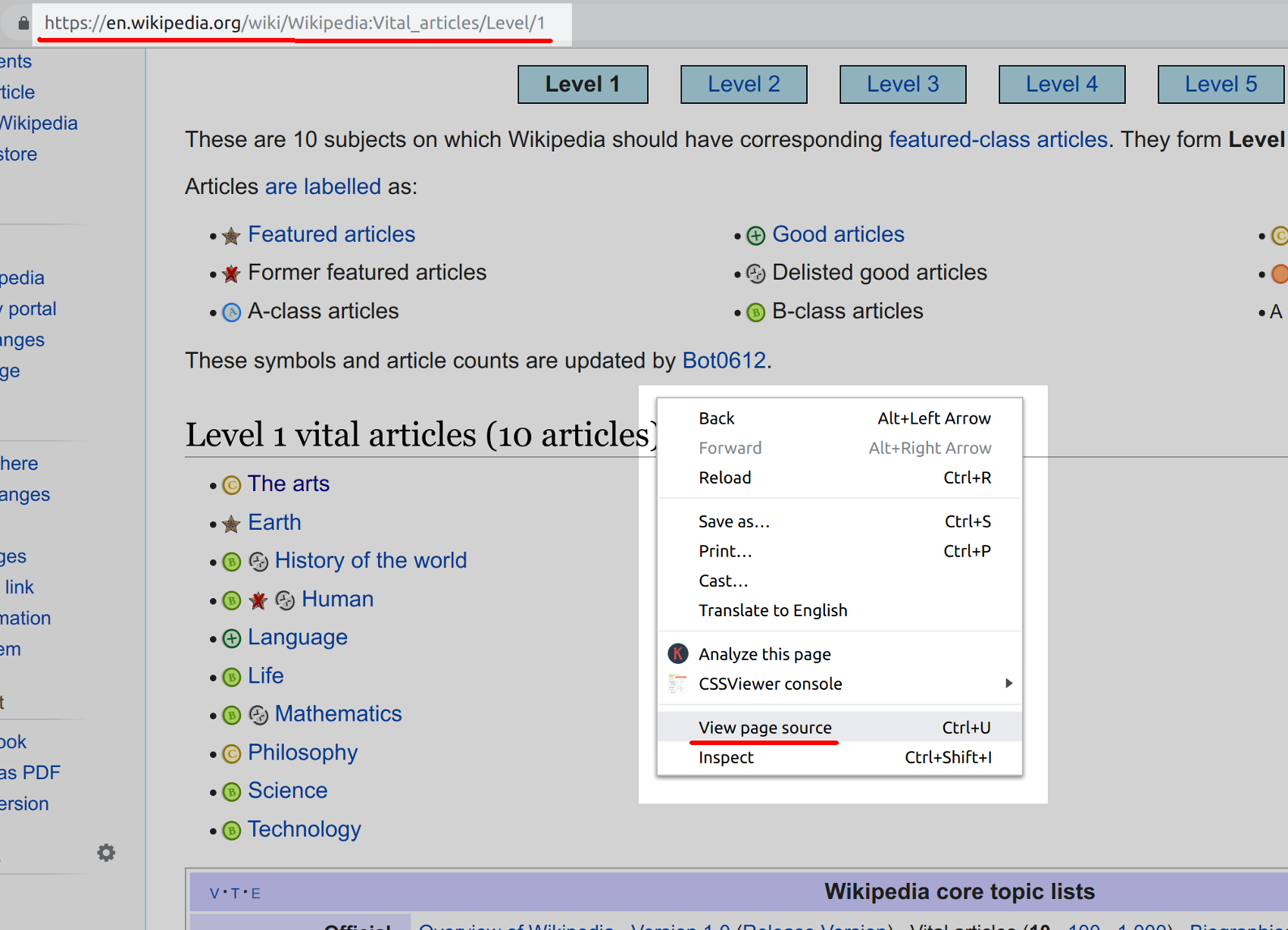
This will bring up the “view page source” option for the HTML, as shown above underlined in red. Click on that option.
The following is a screenshot of where the Wikipedia article titles begin in the HTML page source
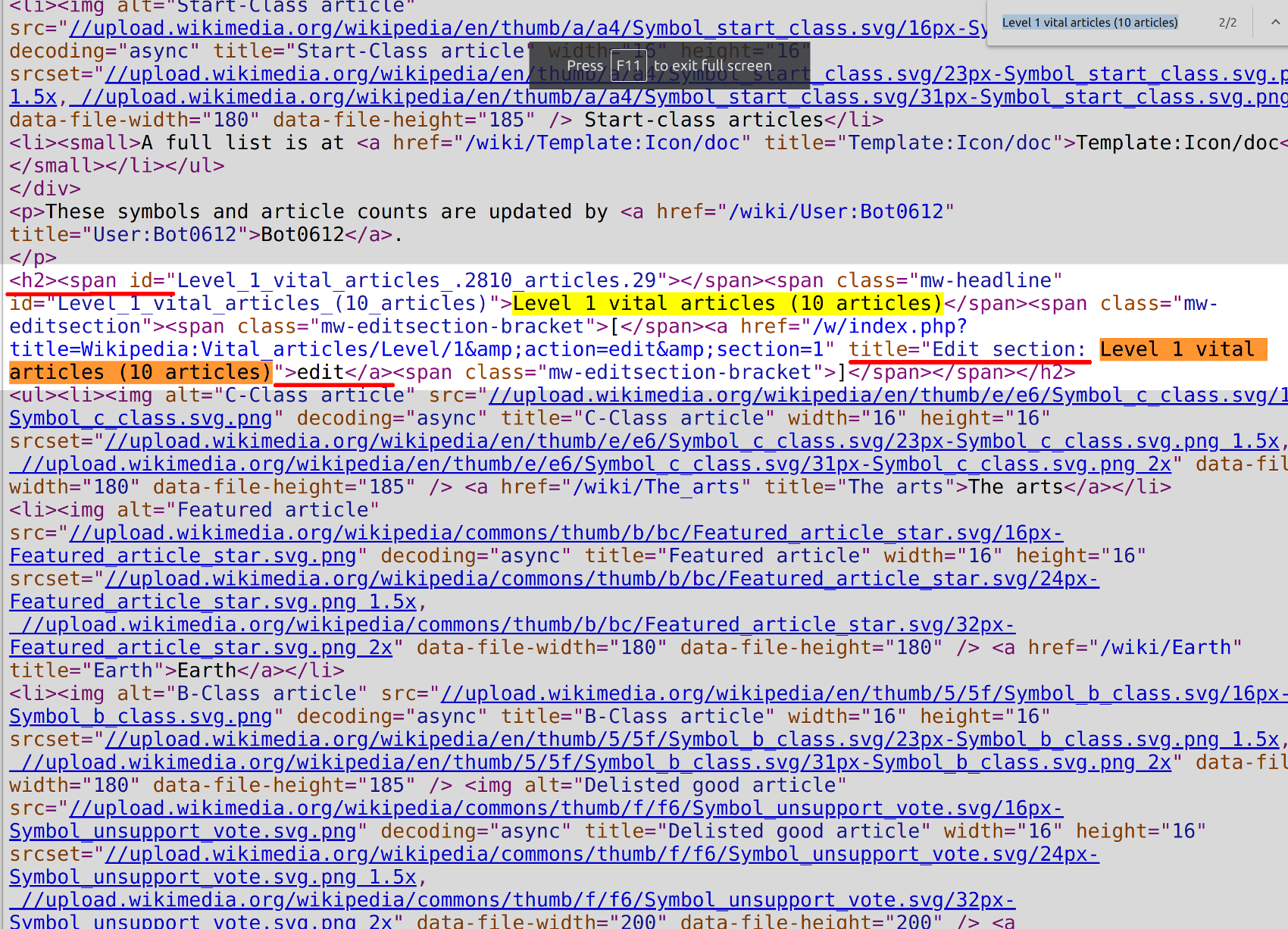
The macro topic for the Wikipedia articles starts at “<h2><span id="Level_1“, so pass this string to the parse_html() function’s marker parameter.
Pass the markers for the HTML to the parse_html() method
The actual topic name starts at “title="Edit section:” and ends at “">edit</a>“:
1 2 3 4 5 6 7 | # topic of articles topic = parse_html( data = source, marker = '<h2><span id="Level_1', start = 'title="Edit section: ', end = '">edit</a>' ) |
In case the function couldn’t find the title, here’s some code that will find an alternative in the URL string:
1 2 3 4 5 6 7 8 9 | # make sure topic/index name has length if len(topic) < 1: # get index name from URL if needed topic = url[url.find("Wikipedia:")+10:] topic = topic[:topic.find("/")] # make lowercase and replace spaces with underscores (_) topic = topic.lower(); topic = topic.replace(" ", "_") |
Fix the title to conform to Elasticsearch index naming conventions
Elasticsearch has certain requirements for its index naming convention. Remove any special characters from the Wikipedia title and make sure the length of the index name will be fewer than 255 characters:
1 2 3 4 5 6 7 8 9 | # remove all special characters topic = ''.join(char for char in topic if char.isalnum() or char == "_") # Elasticsearch index names must be fewer than 255 char if len(topic) > 255: topic = topic[:255] # print the topic/Elasticsearch index name print ("Topic:", topic) |
Iterate over the list of source data to create Python dict objects
Parse and create Python dict objects from the HTML string data returned by the urllib3 Python library and then index the parsed data as Elasticsearch documents.
Execute the following code to declare an empty Python list for the Elasticsearch documents and iterate the HTML source data:
1 2 3 4 5 | # declare an empty list for the article links articles = [] # iterate the list of HTML lines of data for line in source: |
Check if the string of HTML contains the Wikipedia article title and link
1 2 | # make sure that the HTML line contains correct data if 'title="' in line and '<a href="/wiki/' in line: |
Pass the line of HTML to the parse_html() function
Pass the line string as a list object to the data parameter of the parse_html() function call in every iteration in order to get all of the Wikipedia article names and links:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | # title for the article title = parse_html( data = [line], marker = 'title="', start = '">', end = '</a></li>' ) # link for the article link = parse_html( data = [line], marker = '/> <a href="', start = '<a href="', end = '" title="' ) |
If the function found the data it needed, then have it append the data to the articles list as a Python dictionary object:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | # make sure the link and title have length if len(title) >= 3 and len(link) > 3: # ignore links like "Featured Articles" if 'Wikipedia:' not in link: articles += [ { "title" : title, "url" : link } ] # print the articles dict object print ("Articles:", articles, "\n") |
Create Elasticsearch documents from the Python dictionary objects
Iterate over the article list and index the Python dict objects as Elasticsearch documents:
1 2 | # iterate the list of articles with items() for id, article in enumerate(articles): |
Grab the title and URL attributes of the Python dict object
1 2 3 4 | # parse the key-value pairs for the article article_title = article["title"] article_url = "https://en.wikipedia.org/" + str(article["url"]) id_num = id + 1 |
Create a Python dict object for the Elasticsearch document being indexed
Put the title and URL string values into a new dict object that will be used for the Elasticsearch document body:
1 2 3 4 5 | # create a document body for the new Elasticsearch document doc_body = { "title": article_title, "url": article_url } |
Call the index() method to index the Wikipedia data as Elasticsearch documents
Pass the new dict object with the Wikipedia data to the client object instance’s index() method by passing it to the body parameter:
1 2 3 4 5 6 7 8 9 10 11 12 13 | # use a try-catch block for any Elasticsearch index() exceptions try: # call the Elasticsearch client's index() method response = client.index( index = topic, doc_type = '_doc', id = id_num, body = doc_body, request_timeout = 5 ) # print the API response returned by the Elasticsearch client print ("response:", response) |
Print the Elasticsearch API response object returned by the cluster
1 2 3 4 5 6 7 8 | # evaluate the response dict object to check that the API was successful if response["_shards"]["successful"] == 1: print ("INDEX CALL WAS A SUCCESS:", response["_shards"]["successful"]) else: print ("INDEX CALL FAILED") except Exception as err: print ("Elasticsearch index() ERROR:", err) |
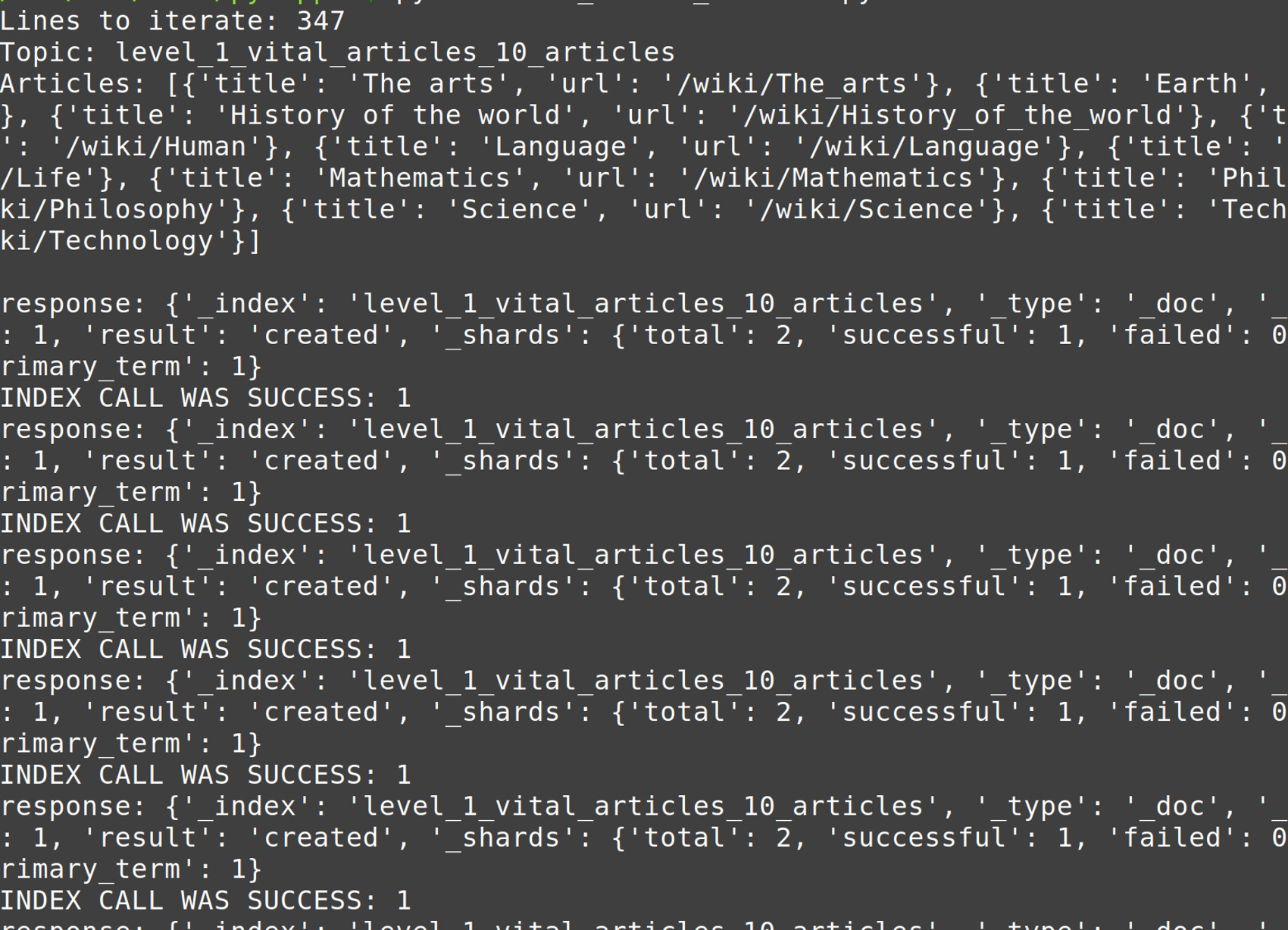
Run the Python script to index the Elasticsearch documents
When you run the Python script the Urllib library will make an HTTP request to the Wikipedia server to get the HTML data, and then it will create an index (if needed) and then it will index the Wikipedia data as new Elasticsearch documents:
1 | python3 index_wikipedia.py |
![Screenshot of Python printing Ur
Check if the string of HTML contains the Wikipedia article title and link
1 2 | # make sure that the HTML line contains correct data if 'title="' in line and '<a href="/wiki/' in line: |
Pass the line of HTML to the parse_html() function
Pass the line string as a list object to the data parameter of the parse_html() function call in every iteration in order to get all of the Wikipedia article names and links:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | # title for the article title = parse_html( data = [line], marker = 'title="', start = '">', end = '</a></li>' ) # link for the article link = parse_html( data = [line], marker = '/> <a href="', start = '<a href="', end = '" title="' ) |
If the function found the data it needed, then have it append the data to the articles list as a Python dictionary object:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | # make sure the link and title have length if len(title) >= 3 and len(link) > 3: # ignore links like "Featured Articles" if 'Wikipedia:' not in link: articles += [ { "title" : title, "url" : link } ] # print the articles dict object print ("Articles:", articles, "\n") |
Create Elasticsearch documents from the Python dictionary objects
Iterate over the article list and index the Python dict objects as Elasticsearch documents:
1 2 | # iterate the list of articles with items() for id, article in enumerate(articles): |
Grab the title and URL attributes of the Python dict object
Declare a new object for the article’s title and then concatenate a string for the article’s URL:
1 2 3 4 | # parse the key-value pairs for the article article_title = article["title"] article_url = "https://en.wikipedia.org/" + str(article["url"]) id_num = id + 1 |
Create a Python dict object for the Elasticsearch document being indexed
Put the title and URL string values into a new dict object that will be used for the Elasticsearch document body:
1 2 3 4 5 | # create a document body for the new Elasticsearch document doc_body = { "title": article_title, "url": article_url } |
Call the index() method to index the Wikipedia data as Elasticsearch documents
Pass the new dict object with the Wikipedia data to the client object instance’s index() method by passing it to the body parameter:
1 2 3 4 5 6 7 8 9 10 11 12 13 | # use a try-catch block for any Elasticsearch index() exceptions try: # call the Elasticsearch client's index() method response = client.index( index = topic, doc_type = '_doc', id = id_num, body = doc_body, request_timeout = 5 ) # print the API response returned by the Elasticsearch client print ("response:", response) |
Conclusion
This tutorial explained how use Python’s built-in urllib3 package library for Python 3 to get data from the internet to index Elasticsearch documents to fetch Wikipedia titles and URLs and how to index that data as Elasticsearch documents. The tutorial specifically covered how to define a Python function to fetch HTML data and parse and slice the HTML string data, declare a URL string for Wikipedia articles, check if the string of HTML contains the Wikipedia article title and link and how to index the Elasticsearch documents.
NOTE: Care must be exercised when using Python’s urllib3 library to get HTML data from a web page. Contents may be copyrighted and many sites will block an IP address for abusing the power of the Python package library. The Wikipedia HTML links fetched in this tutorial are not copyrighted material, however, the content in Wikipedia articles used in this article do have some copyright restrictions.
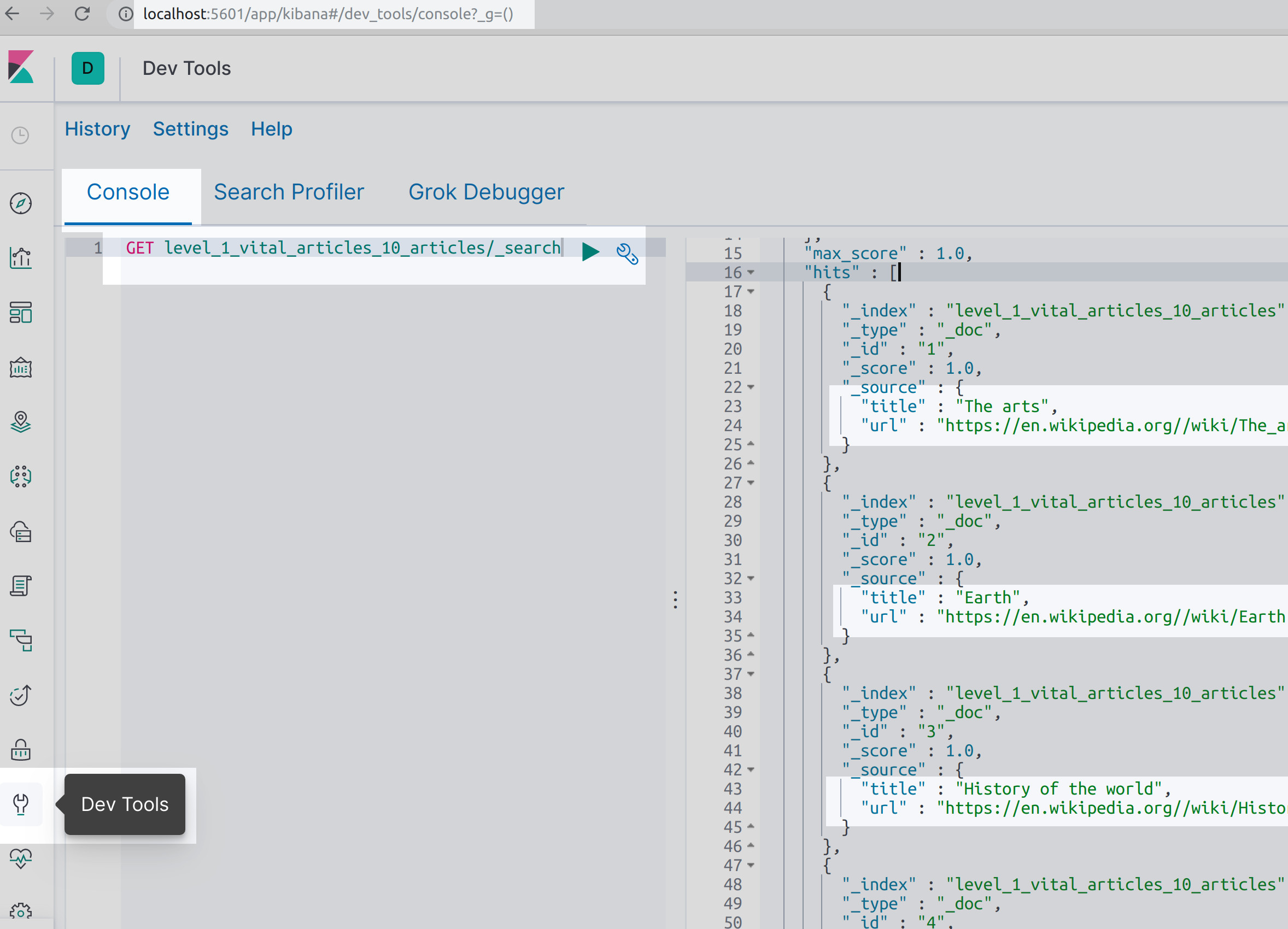
Here’s how to make a GET HTTP request to the Elasticsearch cluster to verify that the data was indexed successfully:
1 | GET level_1_vital_articles_10_articles/_search |
Use the Search API in Kibana to have it return all of the Wikipedia data as Elasticsearch documents
Just the Code
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 | #!/usr/bin/env python3 #-*- coding: utf-8 -*- # import the urllib package for Python 3 import urllib3 # import the Elasticsearch low-level client library from elasticsearch import Elasticsearch # domain name, or server's IP address, goes in the 'hosts' list client = Elasticsearch(hosts=["localhost:9200"]) # declare a function that will return a webpage's HTML as a string def fetch_data(url): # catch any errors and print/return them try: # get the HTTP urllib3.connectionpool.HTTPSConnectionPool object http_pool = urllib3.connection_from_url(url) # returns a urllib3.response.HTTPResponse object resp = http_pool.urlopen('GET', url) # decode the HTML data using UTF-8 decoded = resp.data.decode('utf-8') except Exception as err: print ("fetch_data() ERROR", err) decoded = "fetch_data() ERROR" + str(err) # return the urllib response or any errors return decoded # iterate, slice, and parse HTML string data def parse_html(data, marker, start, end): # iterate the list of HTML data for line in data: # make sure the HTML string contains marker if marker in line: line = line[line.find(marker):] # check if the start and end data is in line if (start in line) and (end in line): # find where the target data starts and ends s = line.find(start) + len(start) e = line.find(end) # return the sliced string return line[s : e] # return empty string by default return "" # declare a URL string for the urllib to parse url = "https://en.wikipedia.org/wiki/Wikipedia:Vital_articles/Level/1" # pass the URL string to the fetch_data() function source = fetch_data(url) # use Python's split() method to put lines of HTML into a list [] source = source.split("\n") # "\n" == linebreak # print the number of HTML lines returned by urllib print ("Lines to iterate:", len(source)) # topic of articles topic = parse_html( data = source, marker = '<h2><span id="Level_1', start = 'title="Edit section: ', end = '">edit</a>' ) # make sure topic/index name has length if len(topic) < 1: # get index name from URL if needed topic = url[url.find("Wikipedia:")+10:] topic = topic[:topic.find("/")] # make lowercase and replace spaces with underscores (_) topic = topic.lower(); topic = topic.replace(" ", "_") # remove all special characters topic = ''.join(char for char in topic if char.isalnum() or char == "_") # Elasticsearch index names must be fewer than 255 char if len(topic) > 255: topic = topic[:255] # print the topic/Elasticsearch index name print ("Topic:", topic) # declare an empty list for the article links articles = [] # iterate the list of HTML lines of data for line in source: # make sure that the HTML line contains correct data if 'title="' in line and '<a href="/wiki/' in line: # title for the article title = parse_html( data = [line], marker = 'title="', start = '">', end = '</a></li>' ) # link for the article link = parse_html( data = [line], marker = '/> <a href="', start = '<a href="', end = '" title="' ) # make sure the link and title have length if len(title) >= 3 and len(link) > 3: # ignore links like "Featured Articles" if 'Wikipedia:' not in link: articles += [ { "title" : title, "url" : link } ] # print the articles dict object print ("Articles:", articles, "\n") # iterate the list of articles with items() for id, article in enumerate(articles): # parse the key-value pairs for the article article_title = article["title"] article_url = "https://en.wikipedia.org/" + str(article["url"]) id_num = id + 1 # create a document body for the new Elasticsearch document doc_body = { "title": article_title, "url": article_url } # use a try-catch block for any Elasticsearch index() exceptions try: # call the Elasticsearch client's index() method response = client.index( index = topic, doc_type = '_doc', id = id_num, body = doc_body, request_timeout = 5 ) # print the API response returned by the Elasticsearch client print ("response:", response) # evaluate the response dict object to check that the API was successful if response["_shards"]["successful"] == 1: print ("INDEX CALL WAS A SUCCESS:", response["_shards"]["successful"]) else: print ("INDEX CALL FAILED") except Exception as err: print ("Elasticsearch index() ERROR:", err) |

Pilot the ObjectRocket Platform Free!
Try Fully-Managed CockroachDB, Elasticsearch, MongoDB, PostgreSQL (Beta) or Redis.
Get Started