How to connect the Python client to Elasticsearch
Introduction
In this tutorial you will learn a more convenient and natural way to write and organize queries when connecting the Python client to Elasticsearch. The Python client keeps to the Elasticsearch JSON DSL, reflecting its structure and terminology while revealing the entire range of the DSL from Python. This is done by either directly implementing defined classes or with queryset-like expressions.
The client also makes an optional persistence layer available when working with documents as Python objects in an ORM-like manner. This allows for retrieving and saving documents, defining mappings and wrapping the document data in user-defined classes. Elasticsearch is developed in Java on top of Lucene, however, the required format for querying the server and configuring the index is JSON.
Elastic has published an official git repository for the low-level Python client.
The client class for the library will adhere to the following structure:
1 2 3 4 5 | class elasticsearch.Elasticsearch( hosts=None, transport_class=class'elasticsearch.transport.transport'="'elasticsearch.transport.Transport'">, **kwargs ) |
Passing a
hostargument is discretionary, and in most instances it should not be necessary.The official documentation for the Elasticsearch Transport class.
Prerequisites
Both Python and the client library for Elasticsearch must be installed on your machine or server for the program to work.
It is highly recommended that you use Python 3, as Python 2 is deprecated and losing support by 2020.
This tutorial will employ Python 3, so verify your Python version with this command:
1 | python3 --version |
Create a simple client command.
- Once you have imported the library and its
Elasticsearchclass you will be able to instantiate the class:
1 2 | from elasticsearch import Elasticsearch elastic = Elasticsearch() |
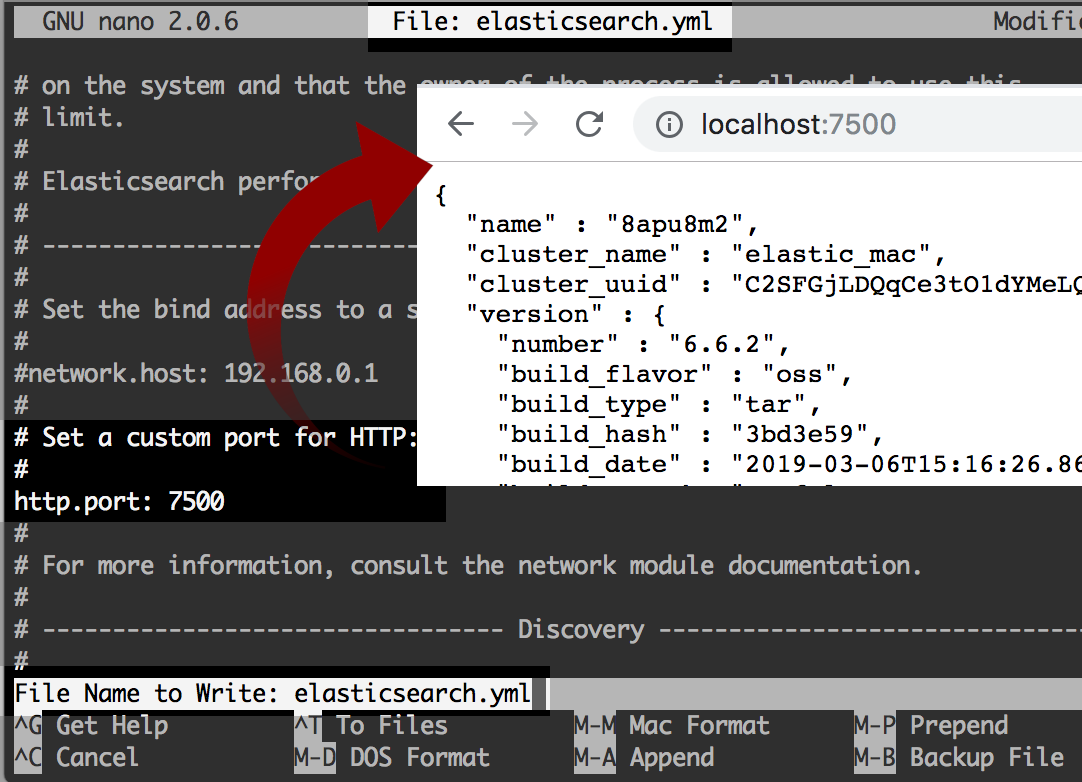
- Assuming you have Elasticsearch properly running on port
7500:
Sniffing to check the cluster and its nodes
- “Sniffing” is when the client tests the cluster state and searches for nodes to put into a list. Sniffing is disabled by default, but is often useful when you are having cluster or connection issues.
1 2 3 4 5 6 | elastic = Elasticsearch( ["{YOUR_DOMAIN}:7500", "localhost:9200"], sniff_on_start=True, sniff_on_connection_fail=True, sniffer_timeout=60 ) |
This will result in a
TransportErrorif the host is incorrect or is unable to make a connection for some reason.You will be able to catch this error in a
TryandExceptblock and set it to make a default connection in the event of a connection issue:
1 2 3 4 5 6 7 8 9 10 11 12 | try: # custom host with sniffing enabled elastic = Elasticsearch( ["{YOUR_DOMAIN}:7500"], sniff_on_start=True, sniff_on_connection_fail=True, sniffer_timeout=60 ) except Exception as error: print ("Elasticsearch Client Error:", error) # make a default connection if error elastic = Elasticsearch() |
Creating a custom client
- Instead of sniffing, you can simply pass the host’s parameters as a Python dictionary. However, be certain you pass the host’s port as a Python integer (
int), and not as a string:
1 2 3 4 | elastic = Elasticsearch([ {'host': 'localhost'}, {'host': '{SOME_OTHER_DOMAIN}', 'port': 7500, 'url_prefix': 'en', 'use_ssl': True}, ]) |
SSL client authentication
1 2 3 4 5 6 7 8 9 | elastic = Elasticsearch( ['localhost:7500', 'other_host:9200'], # enable SSL use_ssl=True, # verify SSL certificates to authenticare verify_certs=True, # path to the certificates ca_certs='/path/to/CA_certs' ) |
Conclusion
This tutorial has discussed ways of integrating Elasticsearch into the Python application. It is important to keep in mind that the Python and the client library for Elasticsearch must both be installed and working properly on your machine for the program to work. You can use the “Sniffing” function to test the cluster states and searche for nodes. However, remember that sniffing is disabled by default. Python 3 should be used for best results, as support for Python 2 will likely be depreciated in the near future.
- The final code should read something like this:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 | #!/usr/bin/env python3 #-*- coding: utf-8 -*- # import the Elastic client library from elasticsearch import Elasticsearch # create a new client instance of client class from elasticsearch import Elasticsearch elastic = Elasticsearch("localhost") # ..or the server's domain name #elastic = Elasticsearch("{YOUR_DOMAIN}") # simple instance creation of the Elasticsearch client #elastic = Elasticsearch() # you can specify to sniff on startup to chinspeckt the cluster and load #elastic = Elasticsearch(["localhost:7500", "{SOME_DOMAIN_URL}:9200"], sniff_on_start=True) ''' try makingto make a custom connection that will sniffs out node and cluster issues ''' try: # custom host with sniffing turned on elastic = Elasticsearch( ["{YOUR_DOMAIN}:7500"], sniff_on_start=True, sniff_on_connection_fail=True, sniffer_timeout=60 ) except Exception as error: print ("Elasticsearch Client Error:", error) # make asimple default connection if error elastic = Elasticsearch()` # print client object instance to console terminal print ("\nELASTICSEARCH INSTANCE:", elastic) print ("CLIENT ATTRIBUTES:", dir(elastic)) |
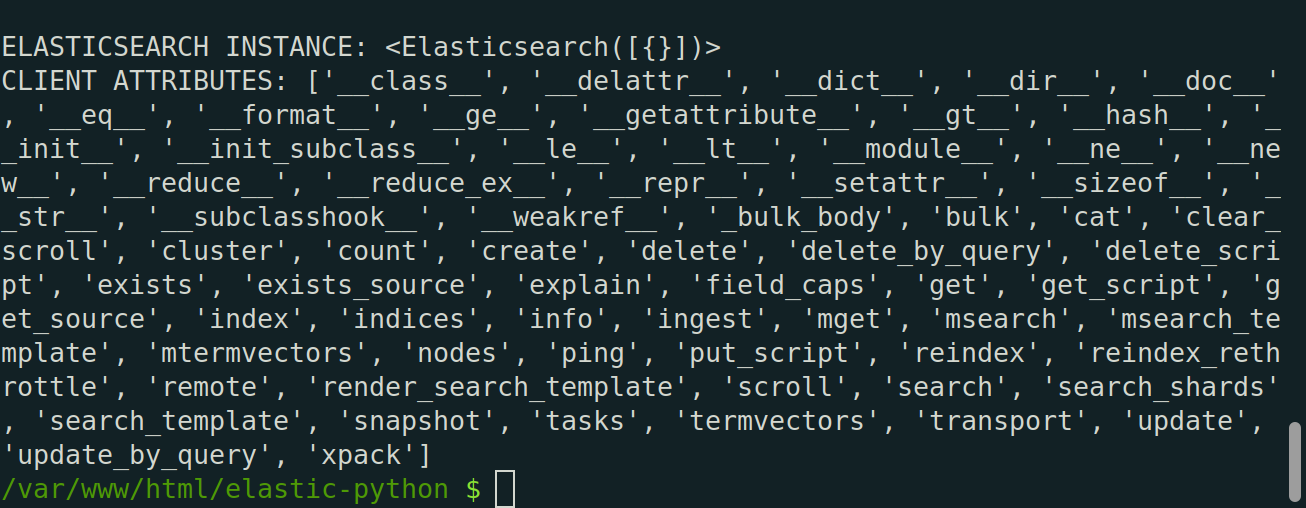
Client printed out to console
1 2 | ELASTICSEARCH INSTANCE: <Elasticsearch([{}])> CLIENT ATTRIBUTES: ['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', '_bulk_body', 'bulk', 'cat', 'clear_scroll', 'cluster', 'count', 'create', 'delete', 'delete_by_query', 'delete_script', 'exists', 'exists_source', 'explain', 'field_caps', 'get', 'get_script', 'get_source', 'index', 'indices', 'info', 'ingest', 'mget', 'msearch', 'msearch_template', 'mtermvectors', 'nodes', 'ping', 'put_script', 'reindex', 'reindex_rethrottle', 'remote', 'render_search_template', 'scroll', 'search', 'search_shards', 'search_template', 'snapshot', 'tasks', 'termvectors', 'transport', 'update', 'update_by_query', 'xpack'] |



Pilot the ObjectRocket Platform Free!
Try Fully-Managed CockroachDB, Elasticsearch, MongoDB, PostgreSQL (Beta) or Redis.
Get Started