How To Bulk Index Elasticsearch Documents Using Golang
Introduction
If you’re storing documents in Elasticsearch, it’s important to know how to index large numbers of documents at a time. Fortunately, it’s easy to accomplish this task using the Bulk() API method to index Elasticsearch documents with the help of the Olivere Golang driver. In this article, we’ll provide step-by-step instructions for performing a bulk index in Elasticsearch with Golang.
Prerequisites for bulk indexing Elasticsearch documents in Golang
Before we check out the code we’ll need to perform our bulk index, let’s take a moment to review the essential prerequisites for this task:
First, Golang needs to be installed, and both the
$GOPATHand$GOROOTneed to be exported in your bash profile. You can use thego versionandgo envcommands to make sure Golang is installed and the correct paths are set.Elasticsearch also needs to be installed on the node that will be running and compiling the Golang scripts. You can use the Kibana UI or the following cURL request to verify that your Elasticsearch cluster is running:
1 | curl -XGET "localhost:9200" |
1 | go get github.com/olivere/elastic |
If Elasticsearch is not installed, Go will try to find it and install it, and you’ll see a terminal response like the following:
1 2 | go: finding github.com/olivere/elastic/v7 v7.0.4 go: downloading github.com/olivere/elastic/v7 v7.0.4 |
Create a Go script and import the packages necessary for bulk indexing
Now that we’ve covered all the necessary prerequisites, let’s go ahead and create a new Golang script with a .go extension. We’ll import the necessary packages for the API calls to Elasticsearch and declare package main at the top of the script:
1 2 3 4 5 6 7 8 9 10 11 12 13 | package main import ( "context" "fmt" "log" // log errors "reflect" // get client attributes "strconv" // to convert ID int to string "time" // set timeout for connection // Import the Olivere Golang driver for Elasticsearch 7 "github.com/olivere/elastic/v7" ) |
You can use either the latest default package version ( "github.com/olivere/elastic" ), or you can specify a particular version of the Olivere package driver.
Declare a struct type collection of fields for the Elasticsearch documents
Next, let’s create a new struct type that will represent the document fields of the Elasticsearch index. Please note that the struct field names used in this example will overwrite the index’s _mapping schema:
1 2 3 4 5 6 7 | // Declare a struct for Elasticsearch fields type ElasticDocs struct { SomeStr string SomeInt int SomeBool bool Timestamp int64 } |
Declare the main() function and connect to Elasticsearch
We’ll need to declare the main() function for all of the code and API calls to Elasticsearch, and we’ll use the Olivere package to declare a new client instance for the Bulk API calls that are used to index documents:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | func main() { // Allow for custom formatting of log output log.SetFlags(0) // Use the Olivere package to get the Elasticsearch version number fmt.Println("Version:", elastic.Version) // Create a context object for the API calls ctx := context.Background() // Declare a client instance of the Olivere driver client, err := elastic.NewClient( elastic.SetSniff(true), elastic.SetURL("http://localhost:9200"), elastic.SetHealthcheckInterval(5*time.Second), // quit trying after 5 seconds ) |
Check if Elasticsearch returned any HTTP errors while Golang was connecting
It’s important to use the log.Fatalf() function call in our code; this function will quit the script if any errors were returned by Elasticsearch while attempting to connect and instantiate a client:
1 2 3 4 5 6 7 8 9 | // Check and see if olivere's NewClient() method returned an error if err != nil { fmt.Println("elastic.NewClient() ERROR:", err) log.Fatalf("quitting connection..") } else { // Print client information fmt.Println("client:", client) fmt.Println("client TYPE:", reflect.TypeOf(client)) } |
Declare an Elasticsearch index and check if it exists on the cluster
If the connection to Elasticsearch was successful, we can declare the index’s name as a string and pass it to a string slice ( []string ). This will allow us to call the NewIndicesExistsService() method’s Do() method to find out if the index name exists:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | // Index name for the bulk Elasticsearch documents goes here indexName := "some_index" // Declare a string slice with the index name in it indices := []string{indexName} // Instantiate a new *elastic.IndicesExistsService existService := elastic.NewIndicesExistsService(client) // Pass the slice with the index name to the IndicesExistsService.Index() method existService.Index(indices) // Have Do() return an API response by passing the Context object to the method call exist, err := existService.Do(ctx) |
The IndicesExistsService returns a boolean indicating if the Elasticsearch index exists
If any errors were returned, or if the API response returned a value of false , then the script will not proceed to perform the bulk index in Elasticsearch:
1 2 3 4 5 6 7 | // Check if the IndicesExistsService.Do() method returned any errors if err != nil { log.Fatalf("IndicesExistsService.Do() ERROR:", err) } else if exist == false { fmt.Println("nOh no! The index", indexName, "doesn't exist.") fmt.Println("Create the index, and then run the Go script again") |
Use cURL to create the index if needed
Creating the index, if it doesn’t already exist, is a simple task. Shown below is an example cURL request that can be used for creating an index. Just paste this request into a terminal window, making sure to change the domain, port, index name, and "settings" values as needed:
1 2 3 4 5 6 7 | curl -XPUT 'http://localhost:9200/some_index' -H 'Content-Type: application/json' -d ' { "settings" : { "number_of_shards" : 3, "number_of_replicas" : 2 } }' |
Create some Elasticsearch document struct instances
If the index in question does exist, however, you can go ahead and declare any empty slice that will be used to contain the Elasticsearch documents struct instances. You can also create some documents by passing some values to the struct’s fields during declaration:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | // Bulk index the Elasticsearch documents if index exists } else if exist == true { fmt.Println("Index name:", indexName, " exists!") // Declare an empty slice for the Elasticsearch document struct objects docs := []ElasticDocs{} // Get the type of the 'docs' struct slice fmt.Println("docs TYPE:", reflect.TypeOf(docs)) // New ElasticDocs struct instances newDoc1 := ElasticDocs{SomeStr: "Hello, world!", SomeInt: 42, SomeBool: true, Timestamp: 0.0} newDoc2 := ElasticDocs{SomeStr: "ä½ å¥½ï¼Œä¸–ç•Œï¼", SomeInt: 7654, SomeBool: false, Timestamp: 0.0} newDoc3 := ElasticDocs{SomeStr: "Kumusta, mundo!", SomeInt: 1234, SomeBool: true, Timestamp: 0.0} |
Append the Elasticsearch document structs to the Golang slice
We’ll use the append() function to add the Elasticsearch struct documents to our docs slice:
1 2 3 4 | // Append the new Elasticsearch document struct objects to the slice docs = append(docs, newDoc1) docs = append(docs, newDoc2) docs = append(docs, newDoc3) |
Instantiate an Elasticsearch client bulk object for the Golang Index API calls
The Elasticsearch API call will be made using the client.Bulk() library. This library allows you to perform a bulk index in Elasticsearch with Golang:
1 2 | // Declare a new Bulk() object using the client instance bulk := client.Bulk() |
Declare an integer value for the Elasticsearch document’s _id
If you’d like to specify an _id for the Elasticsearch documents, then you’ll need to pass a string value to the NewBulkIndexRequest() instance’s Id() method later on. Without this value, Elasticsearch will dynamically generate an alpha-numeric ID for the document automatically:
1 2 | // Elasticsearch _id counter starts at 0 docID := 0 |
Iterate over the Golang struct documents and create a timestamp
Next, we’ll use Golang’s for keyword to iterate over the struct documents stored on the slice, and we’ll use range to figure out the length of the iteration:
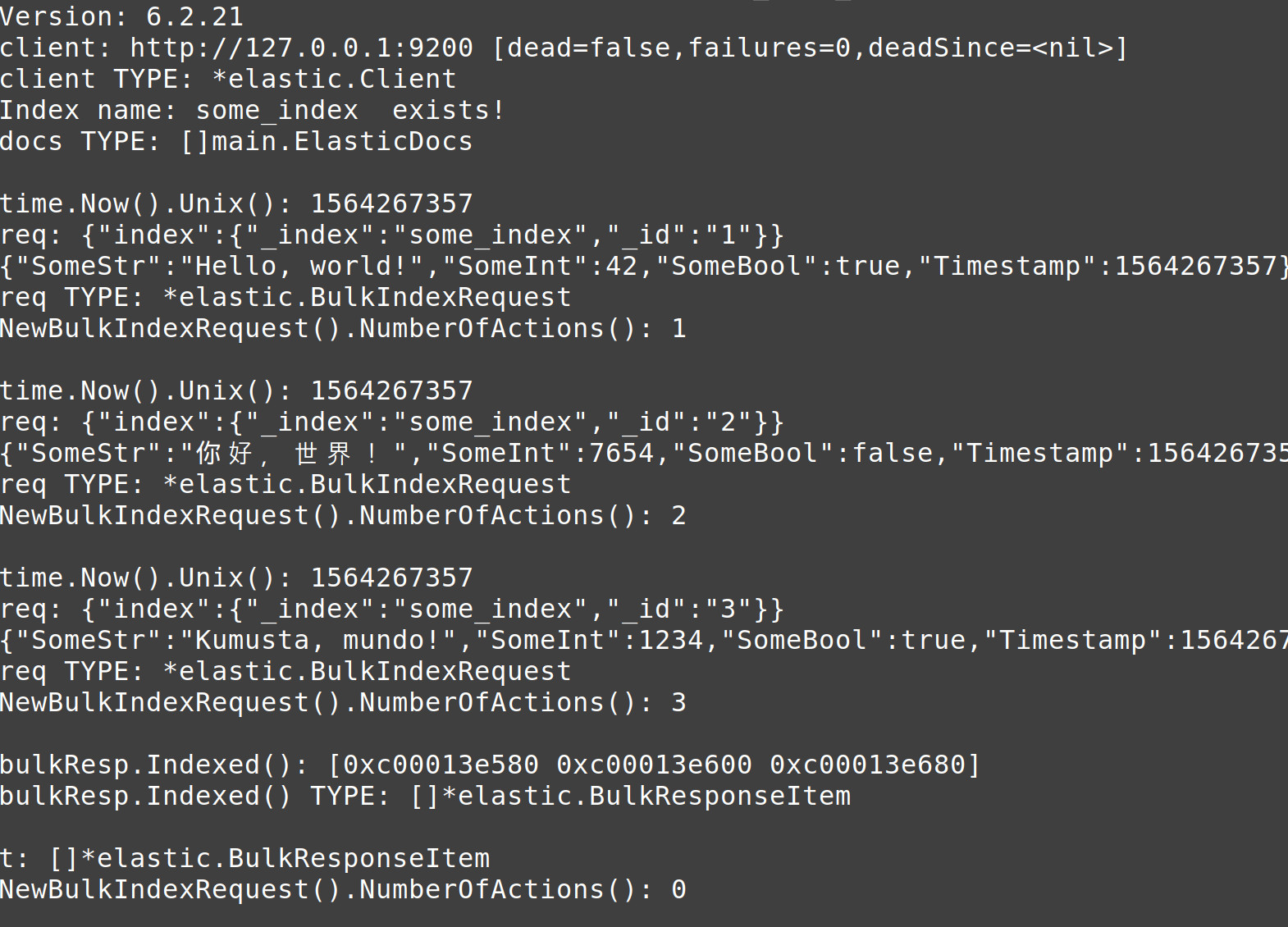
1 2 3 4 5 6 7 8 9 10 11 12 | // Iterate over the slice of Elasticsearch documents for _, doc := range docs { // Incrementally change the _id number in each iteration docID++ // Convert the _id integer into a string idStr := strconv.Itoa(docID) // Create a new int64 float from time package for doc timestamp doc.Timestamp = time.Now().Unix() fmt.Println("ntime.Now().Unix():", doc.Timestamp) |
Make the bulk request to index Elasticsearch documents
Instantiate a NewBulkIndexRequest() object and pass the document’s values to the object’s Doc() method. Make sure to set the OpType() as "index" if you’d like to have Golang return the API response:
1 2 3 4 5 6 7 8 9 10 | // Declate a new NewBulkIndexRequest() instance req := elastic.NewBulkIndexRequest() // Assign custom values to the NewBulkIndexRequest() based on the Elasticsearch // index and the request type req.OpType("index") // set type to "index" document req.Index(indexName) //req.Type("_doc") // Doc types are deprecated (default now _doc) req.Id(idStr) req.Doc(doc) |
Add the Golang index request to the bulk API object
Use the Add() method to add the request to the bulk object:
1 2 3 4 5 6 7 8 | // Print information about the NewBulkIndexRequest object fmt.Println("req:", req) fmt.Println("req TYPE:", reflect.TypeOf(req)) // Add the new NewBulkIndexRequest() to the client.Bulk() instance bulk = bulk.Add(req) fmt.Println("NewBulkIndexRequest().NumberOfActions():", bulk.NumberOfActions()) } |
Make the bulk request in Golang and have it return a response
At this point, we’re ready to perform our bulk index operation. Pass a context object while calling the Bulk object’s Do() method and check if it returned any errors:
1 2 3 4 5 6 7 | // Do() sends the bulk requests to Elasticsearch bulkResp, err := bulk.Do(ctx) // Check if the Do() method returned any errors if err != nil { log.Fatalf("bulk.Do(ctx) ERROR:", err) } else { |
Iterate over the response returned by the Elasticsearch Bulk API
Now we’ll iterate over the response that was returned from the API call:
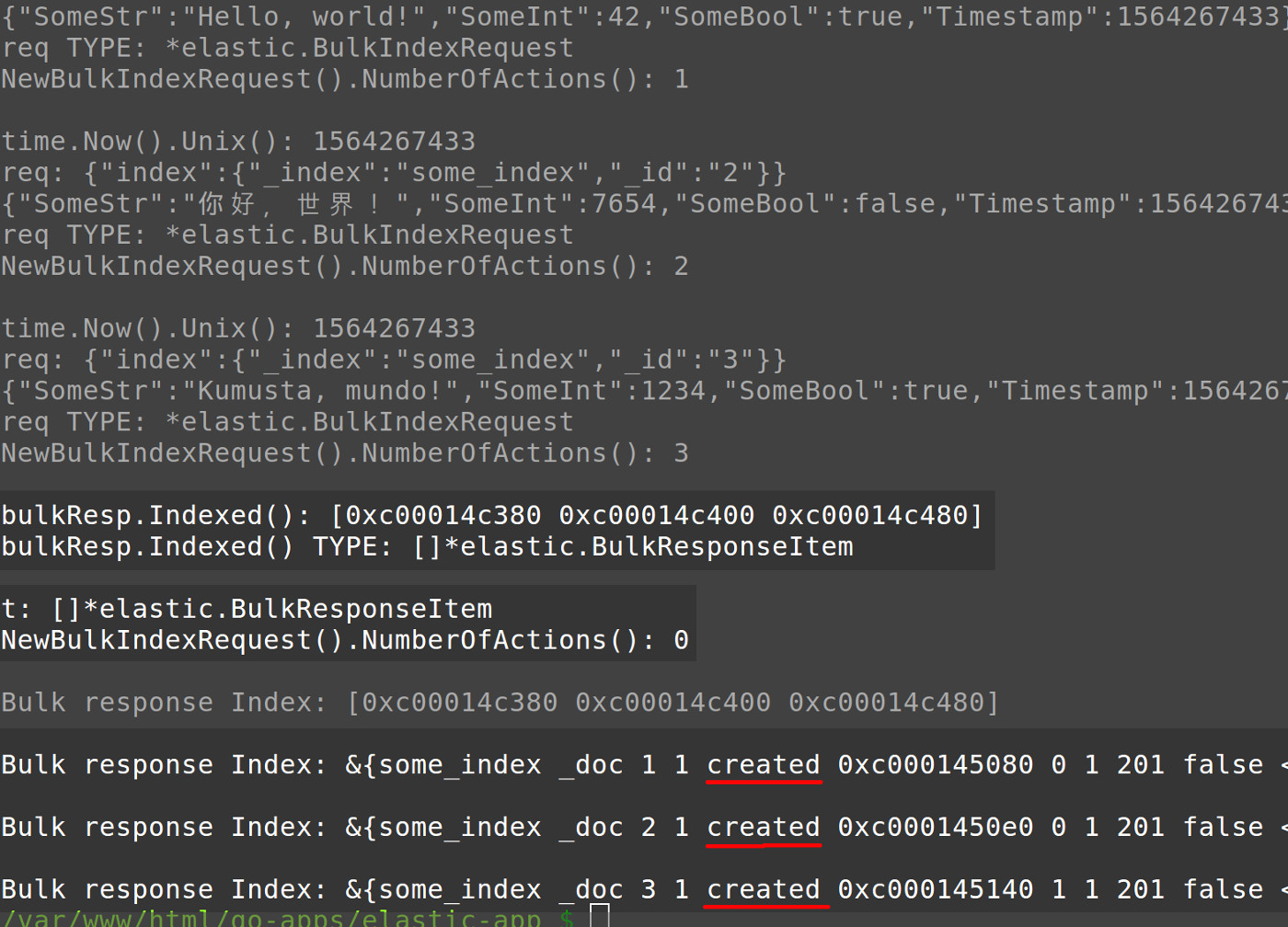
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | // If there is no error then get the Elasticsearch API response indexed := bulkResp.Indexed() fmt.Println("nbulkResp.Indexed():", indexed) fmt.Println("bulkResp.Indexed() TYPE:", reflect.TypeOf(indexed)) // Iterate over the bulkResp.Indexed() object returned from bulk.go t := reflect.TypeOf(indexed) fmt.Println("nt:", t) fmt.Println("NewBulkIndexRequest().NumberOfActions():", bulk.NumberOfActions()) // Iterate over the document responses for i := 0; i < t.NumMethod(); i++ { method := t.Method(i) fmt.Println("nbulkResp.Indexed() METHOD NAME:", i, method.Name) fmt.Println("bulkResp.Indexed() method:", method) } // Return data on the documents indexed fmt.Println("nBulk response Index:", indexed) for _, info := range indexed { fmt.Println("nBulk response Index:", info) //fmt.Println("nBulk response Index:", info.Index) } } } } |
Run the Golang script to bulk index the Elasticsearch documents
We’ve finished creating our Golang script– now it’s time to run it. Navigate to the directory with the Golang script in a terminal window and use the command go run SCRIPT_NAME.go . The script should return a response similar to the following:
1 2 3 4 5 6 7 | Bulk response Index: [0xc00014c380 0xc00014c400 0xc00014c480] Bulk response Index: &{some_index _doc 1 1 created 0xc000145080 0 1 201 false <nil> <nil>} Bulk response Index: &{some_index _doc 2 1 created 0xc0001450e0 0 1 201 false <nil> <nil>} Bulk response Index: &{some_index _doc 3 1 created 0xc000145140 1 1 201 false <nil> <nil>} |
Conclusion
Being able to bulk index documents is an important facet of managing data in Elasticsearch. With the help of the Olivere driver, it’s easy to perform a bulk index in Elasticsearch with Golang. Using the instructions provided throughout this tutorial, you’ll be prepared to write your own script to bulk index documents for your Elasticsearch implementation.
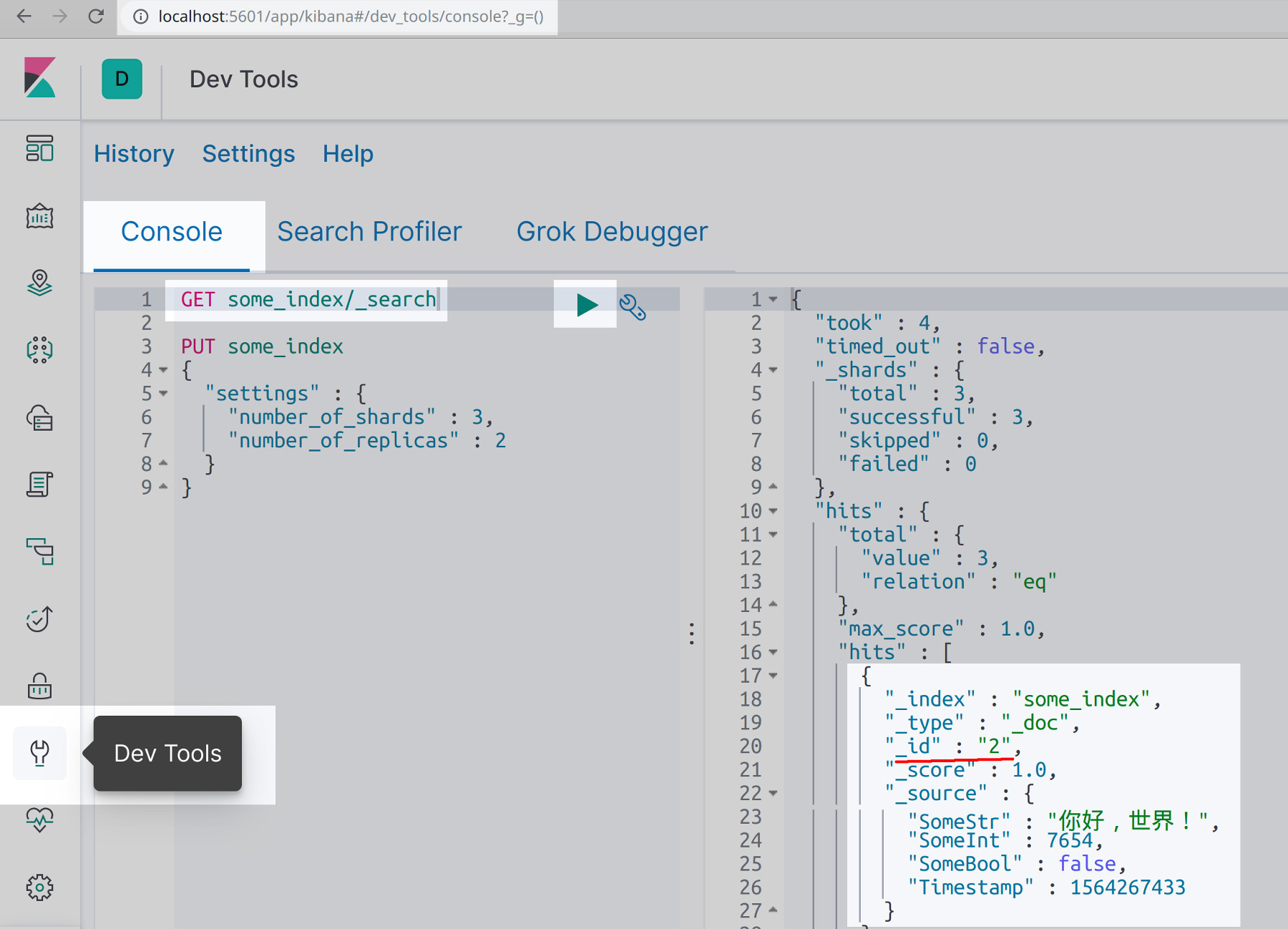
Use Kibana to verify that the Golang script successfully bulk indexed Elasticsearch documents
Once you’ve run your script, it’s a good idea to verify that the documents were successfully indexed. Simply navigate to the Kibana port of your domain in a browser tab, then go the Dev Tools section and click on Console to make the following HTTP request:
1 | GET some_index/_search |
Just the Code
Shown below is the bulk-indexing script in its entirety:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 | package main import ( "context" "fmt" "log" // log errors "reflect" // get client attributes "strconv" // to convert ID int to string "time" // set timeout for connection // Import the Olivere Golang driver for Elasticsearch 7 "github.com/olivere/elastic/v7" ) // Declare a struct for Elasticsearch fields type ElasticDocs struct { SomeStr string SomeInt int SomeBool bool Timestamp int64 } func main() { // Allow for custom formatting of log output log.SetFlags(0) // Use the Olivere package to get the Elasticsearch version number fmt.Println("Version:", elastic.Version) // Create a context object for the API calls ctx := context.Background() // Declare a client instance of the Olivere driver client, err := elastic.NewClient( elastic.SetSniff(true), elastic.SetURL("http://localhost:9200"), elastic.SetHealthcheckInterval(5*time.Second), // quit trying after 5 seconds ) // Check and see if olivere's NewClient() method returned an error if err != nil { fmt.Println("elastic.NewClient() ERROR:", err) log.Fatalf("quiting connection..") } else { // Print client information fmt.Println("client:", client) fmt.Println("client TYPE:", reflect.TypeOf(client)) } // Index name for the bulk Elasticsearch documents goes here indexName := "some_index" // Declare a string slice with the index name in it indices := []string{indexName} // Instantiate a new *elastic.IndicesExistsService existService := elastic.NewIndicesExistsService(client) // Pass the slice with the index name to the IndicesExistsService.Index() method existService.Index(indices) // Have Do() return an API response by passing the Context object to the method call exist, err := existService.Do(ctx) // Check if the IndicesExistsService.Do() method returned any errors if err != nil { log.Fatalf("IndicesExistsService.Do() ERROR:", err) } else if exist == false { fmt.Println("nOh no! The index", indexName, "doesn't exist.") fmt.Println("Create the index, and then run the Go script again") /* curl -XPUT 'http://localhost:9200/some_index' -H 'Content-Type: application/json' -d ' { "settings" : { "number_of_shards" : 3, "number_of_replicas" : 2 } }' */ // Bulk index the Elasticsearch documents if index exists } else if exist == true { fmt.Println("Index name:", indexName, " exists!") // Declare an empty slice for the Elasticsearch document struct objects docs := []ElasticDocs{} // Get the type of the 'docs' struct slice fmt.Println("docs TYPE:", reflect.TypeOf(docs)) // New ElasticDocs struct instances newDoc1 := ElasticDocs{SomeStr: "Hello, world!", SomeInt: 42, SomeBool: true, Timestamp: 0.0} newDoc2 := ElasticDocs{SomeStr: "ä½ å¥½ï¼Œä¸–ç•Œï¼", SomeInt: 7654, SomeBool: false, Timestamp: 0.0} newDoc3 := ElasticDocs{SomeStr: "Kumusta, mundo!", SomeInt: 1234, SomeBool: true, Timestamp: 0.0} // Append the new Elasticsearch document struct objects to the slice docs = append(docs, newDoc1) docs = append(docs, newDoc2) docs = append(docs, newDoc3) // Declare a new Bulk() object using the client instance bulk := client.Bulk() // Elasticsearch _id counter starts at 0 docID := 0 // Iterate over the slice of Elasticsearch documents for _, doc := range docs { // Incrementally change the _id number in each iteration docID++ // Convert the _id integer into a string idStr := strconv.Itoa(docID) // Create a new int64 float from time package for doc timestamp doc.Timestamp = time.Now().Unix() fmt.Println("ntime.Now().Unix():", doc.Timestamp) // Declate a new NewBulkIndexRequest() instance req := elastic.NewBulkIndexRequest() // Assign custom values to the NewBulkIndexRequest() based on the Elasticsearch // index and the request type req.OpType("index") // set type to "index" document req.Index(indexName) //req.Type("_doc") // Doc types are deprecated (default now _doc) req.Id(idStr) req.Doc(doc) // Print information about the NewBulkIndexRequest object fmt.Println("req:", req) fmt.Println("req TYPE:", reflect.TypeOf(req)) // Add the new NewBulkIndexRequest() to the client.Bulk() instance bulk = bulk.Add(req) fmt.Println("NewBulkIndexRequest().NumberOfActions():", bulk.NumberOfActions()) } // Do() sends the bulk requests to Elasticsearch bulkResp, err := bulk.Do(ctx) // Check if the Do() method returned any errors if err != nil { log.Fatalf("bulk.Do(ctx) ERROR:", err) } else { // If there is no error then get the Elasticsearch API response indexed := bulkResp.Indexed() fmt.Println("nbulkResp.Indexed():", indexed) fmt.Println("bulkResp.Indexed() TYPE:", reflect.TypeOf(indexed)) // Iterate over the bulkResp.Indexed() object returned from bulk.go t := reflect.TypeOf(indexed) fmt.Println("nt:", t) fmt.Println("NewBulkIndexRequest().NumberOfActions():", bulk.NumberOfActions()) // Iterate over the document responses for i := 0; i < t.NumMethod(); i++ { method := t.Method(i) fmt.Println("nbulkResp.Indexed() METHOD NAME:", i, method.Name) fmt.Println("bulkResp.Indexed() method:", method) } // Return data on the documents indexed fmt.Println("nBulk response Index:", indexed) for _, info := range indexed { fmt.Println("nBulk response Index:", info) //fmt.Println("nBulk response Index:", info.Index) } } } } |

Pilot the ObjectRocket Platform Free!
Try Fully-Managed CockroachDB, Elasticsearch, MongoDB, PostgreSQL (Beta) or Redis.
Get Started