How to Bulk Index Elasticsearch Documents From A JSON File Using Python
Introduction
When you’re managing data in Elasticsearch, it’s important to know how to bulk index documents in an efficient manner. This article will explain how to bulk index Elasticsearch documents from a JSON file using Python. The Python script will index the data as Elasticsearch documents with the help of the Python client library and Python’s built-in json library. This process is a simple and efficient one because Python has native JSON support built into its language. The Python dict object can easily be converted to a JSON string using its dumps() method.
Prerequisites
Before we dive into the code, let’s review a few prerequisites that must be in place in order to bulk index Elasticsearch documents from a JSON file using Python:
First, the Elasticsearch service must be running on the same machine or server where the JSON file is stored.
It’s recommended that you use Python 3 instead of Python 2.7 since Python 2 is now deprecated.
You will also need the PIP3 package manager for Python 3 if the
elasticsearchclient library for Python 3 is not installed. You can typepip3 listto get a list of all of the packages currently installed on your machine.If it’s not installed already, you can install the low-level client Elasticsearch distribution for Python 3 using PIP3:
1 | pip3 install elasticsearch |
Create a JSON file with documents to be indexed to Elasticsearch
Now that we’ve discussed the prerequisites, we can go ahead and create a new JSON file with the .json file extension. We’ll be adding some documents with fields to be indexed in Elasticsearch. You can use the touch command in a terminal window to create your JSON file:
1 | touch docs.json |
Let’s edit the file and make sure that all of the documents have the same field types; this will prevent Elasticsearch from raising a _mapping exception. For this tutorial, we’ll use the following documents as examples:
1 2 3 4 5 | {"str field": "some string", "int field": 12345, "bool field": True} {"str field": "another string", "int field": 42, "bool field": False} {"str field": "random string", "int field": 3856452, "bool field": True} {"str field": "string value", "int field": 11111, "bool field": False} {"str field": "last string", "int field": 54321, "bool field": True} |
NOTE: The JSON file must be in the same directory as the Python script that’s making the Bulk API call to Elasticsearch. If it’s in a different directory, you must specify the relative path to the JSON file when using the open() command in Python.
Import the Python package libraries for the Elasticsearch Bulk API call
Next, we’ll create a new Python script in the same directory as our JSON file using the command touch bulk_index.py. Let’s make sure to import the package libraries for JSON, as well as the Elasticsearch and helpers method libraries, at the beginning of the script:
1 2 3 4 5 6 7 8 9 10 11 | # import Python's JSON library for its loads() method import json # import time for its sleep method from time import sleep # import the datetime libraries datetime.now() method from datetime import datetime # use the elasticsearch client's helpers class for _bulk API from elasticsearch import Elasticsearch, helpers |
NOTE: In this script, we’ll be using the datetime.now() method call to create a timestamp for the Elasticsearch documents.
Declare a client instance of the Elasticsearch low-level library
The next step is to pass a string to the Elasticsearch() method call. When you follow along with this example, be sure to replace the default values with your cluster’s host name and the port that Elasticsearch is running on:
1 2 | # declare a client instance of the Python Elasticsearch library client = Elasticsearch("localhost:9200") |
NOTE: The default port for Elasticsearch is 9200, but this can be configured in your server’s elasticsearch.yml file.
Open the JSON data and return a list of Elasticsearch documents
In this next bit of code, we declare a function that will open the JSON file’s data and return a list of JSON object strings that can be indexed as Elasticsearch documents:
1 2 3 4 5 6 7 8 9 10 | # define a function that will load a text file def get_data_from_text_file(self): # the function will return a list of docs return [l.strip() for l in open(str(self), encoding="utf8", errors='ignore')] # call the function to get the string data containing docs docs = get_data_from_text_file("data.json") # print the length of the documents in the string print ("String docs length:", len(docs)) |
NOTE: Be sure to pass the relative path to the .json file in the string argument as well if the file is not located in the same directory as the Python script.
Iterate over the list of JSON document strings and create Elasticsearch dictionary objects
Let’s create an empty list object ([]) that will hold the dict documents created from the JSON strings in the .json file. After the list declaration, we use enumerate() and iterate over the list of strings returned from the JSON file:
1 2 3 4 5 6 7 8 | # define an empty list for the Elasticsearch docs doc_list = [] # use Python's enumerate() function to iterate over list of doc strings for num, doc in enumerate(docs): # catch any JSON loads() errors try: |
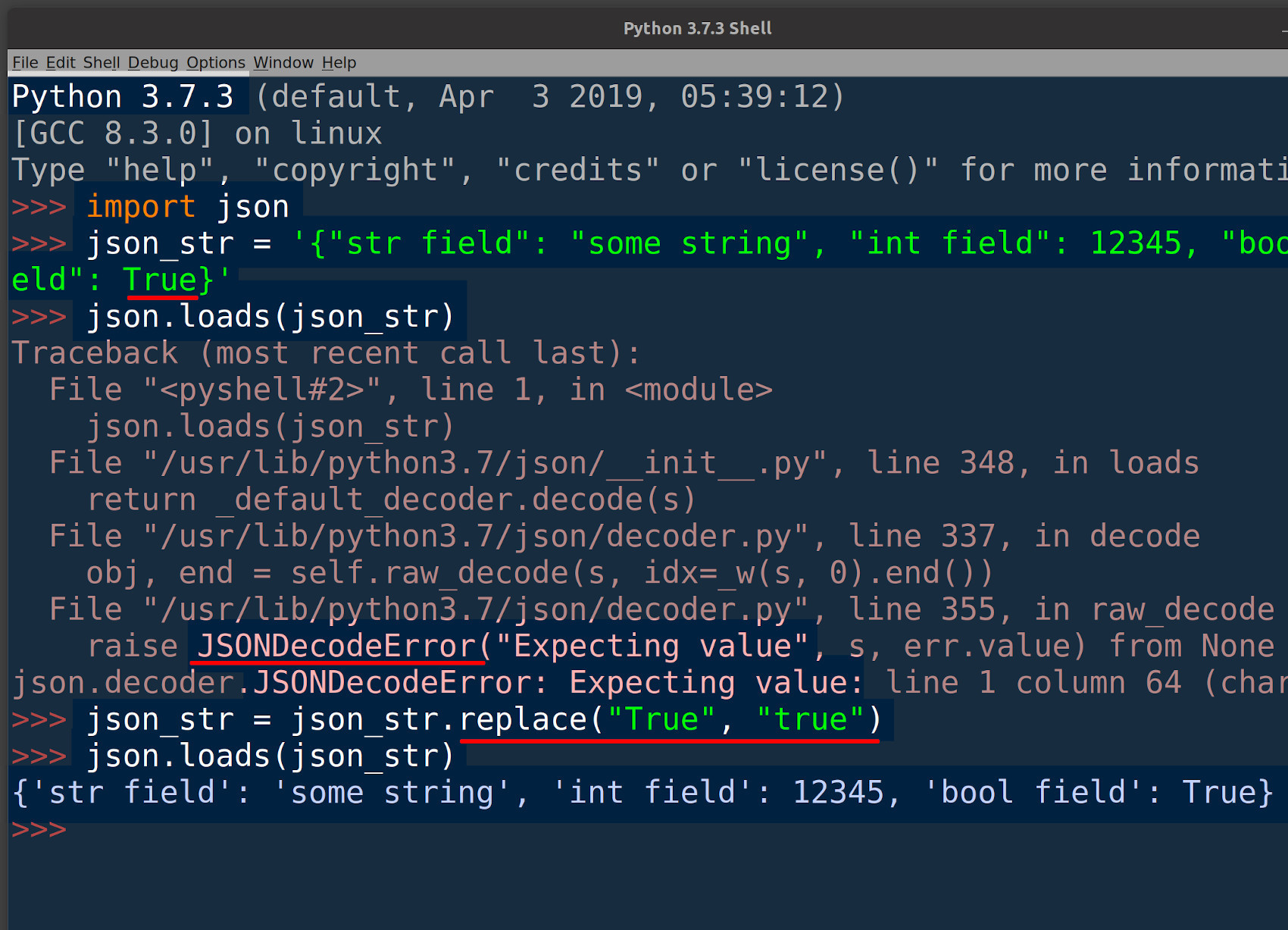
Avoid getting a ‘JSONDecodeError’ by making Boolean values lowercase
It’s important to make any Python Boolean values lowercase before the string is passed to the json.loads() method call; otherwise, Python will return a JSONDecodeError exception.
This can be done using the Python string’s built-in replace() method call:
1 2 3 | # prevent JSONDecodeError resulting from Python uppercase boolean doc = doc.replace("True", "true") doc = doc.replace("False", "false") |
Pass the JSON string to the ‘json.loads()’ method call
In this section, we’ll pass the fixed JSON string to Python’s json.loads() method. It should return a dict object that will represent the Elasticsearch document:
1 2 | # convert the string to a dict object dict_doc = json.loads(doc) |
Add more fields to the Elasticsearch Python dict document
It’s possible to add more fields to the document by assigning a value to a new key in the dictionary object. The following example assigns the documents a new field called "timestamp", and it uses the datetime.now() method call to generate the value for this field:
1 2 | # add a new field to the Elasticsearch doc dict_doc["timestamp"] = datetime.now() |
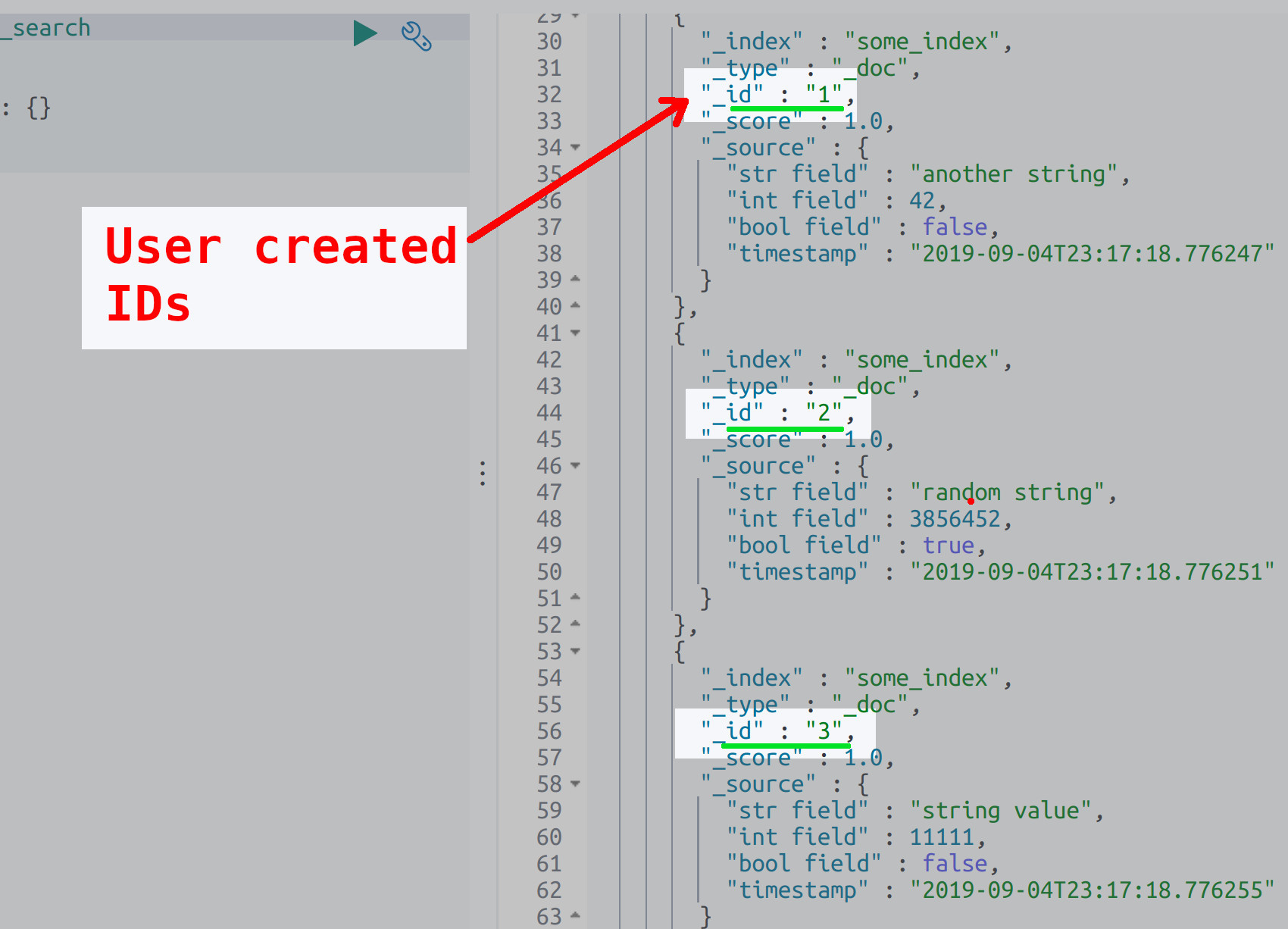
Create a custom _id for the Elasticsearch Python document
You don’t have to assign an "_id" value to the Elasticsearch document; however, Elasticsearch will generate a unique alpha-numeric _id for you if this value is omitted:
1 2 | # add a dict key called "_id" if you'd like to specify an ID for the doc dict_doc["_id"] = num |
The enumerate() iterator function returns an integer, representing a tally of each iteration and the value. The following example uses that num value to create a number _id for each document.
Append the Elasticsearch ‘dict’ object to the list
We use the += Python operator to append the dict JSON object to the list that will eventually be passed to the helpers.bulk() method:
1 2 3 4 5 6 7 8 | # append the dict object to the list [] doc_list += [dict_doc] except json.decoder.JSONDecodeError as err: # print the errors print ("ERROR for num:", num, "-- JSONDecodeError:", err, "for doc:", doc) print ("Dict docs length:", len(doc_list)) |
NOTE: If there are any JSONDecodeError exceptions raised, then those documents will not be added to the list. You can print the length of the list object using len() to see how many documents were added.
Pass the list of Elasticsearch documents to the client’s helpers.bulk() method
In this section, we’ll pass the doc_list of Elasticsearch documents objects to the helpers.bulk() method. Make sure to pass the client instance and specify an index name when you call the method:
1 2 3 4 5 6 7 8 9 10 11 | # attempt to index the dictionary entries using the helpers.bulk() method try: print ("\nAttempting to index the list of docs using helpers.bulk()") # use the helpers library's Bulk API to index list of Elasticsearch docs resp = helpers.bulk( client, doc_list, index = "some_index", doc_type = "_doc" ) |
NOTE: The document’s doc_type parameter has been deprecated since Elasticsearch v6.0. Pass the "_doc" string as an argument instead if you’re using a newer version of Elasticsearch.
Print the API response returned by the Elasticsearch cluster
The try-catch indentation will exit the script if any errors occur. Otherwise, the method call should return a response indicating how many documents were indexed:
1 2 3 4 5 6 7 8 9 | # print the response returned by Elasticsearch print ("helpers.bulk() RESPONSE:", resp) print ("helpers.bulk() RESPONSE:", json.dumps(resp, indent=4)) except Exception as err: # print any errors returned while making the helpers.bulk() API call print("Elasticsearch helpers.bulk() ERROR:", err) quit() |
Make a search request to get all of the Elasticsearch index’s documents
In the next bit of code, we’ll create a query filter that will return all of the documents in the Elasticsearch index:
1 2 3 4 5 6 7 | # get all of docs for the index query_all = { 'size' : 10000, 'query': { 'match_all' : {} } } |
NOTE: The default number of documents returned by the search() method is 10, and the maximum integer value you can pass to the size parameter is 10_000. Any value larger than 10,000 will return an error saying "Result window is too large, from + size must be less than or equal to: [10000]".
Make the script pause before searching for the documents
We can use Python’s time library to have our script “sleep” for a few seconds. This ensures that the Elasticsearch cluster has time to index the documents before another API call is made to return them with search():
1 2 | print ("\nSleeping for a few seconds to wait for indexing request to finish.") sleep(2) |
Verify that the JSON string objects were indexed into Elasticsearch as documents
Let’s call the Elasticsearch Python client instance’s search() method and have it return all of the documents:
1 2 3 4 5 6 7 8 9 10 | # pass the query_all dict to search() method resp = client.search( index = "some_index", body = query_all ) print ("search() response:", json.dumps(resp, indent=4)) # print the number of docs in index print ("Length of docs returned by search():", len(resp['hits']['hits'])) |
NOTE: The documents will be nested inside the response object’s ['hits']['hits'] keys.
Conclusion
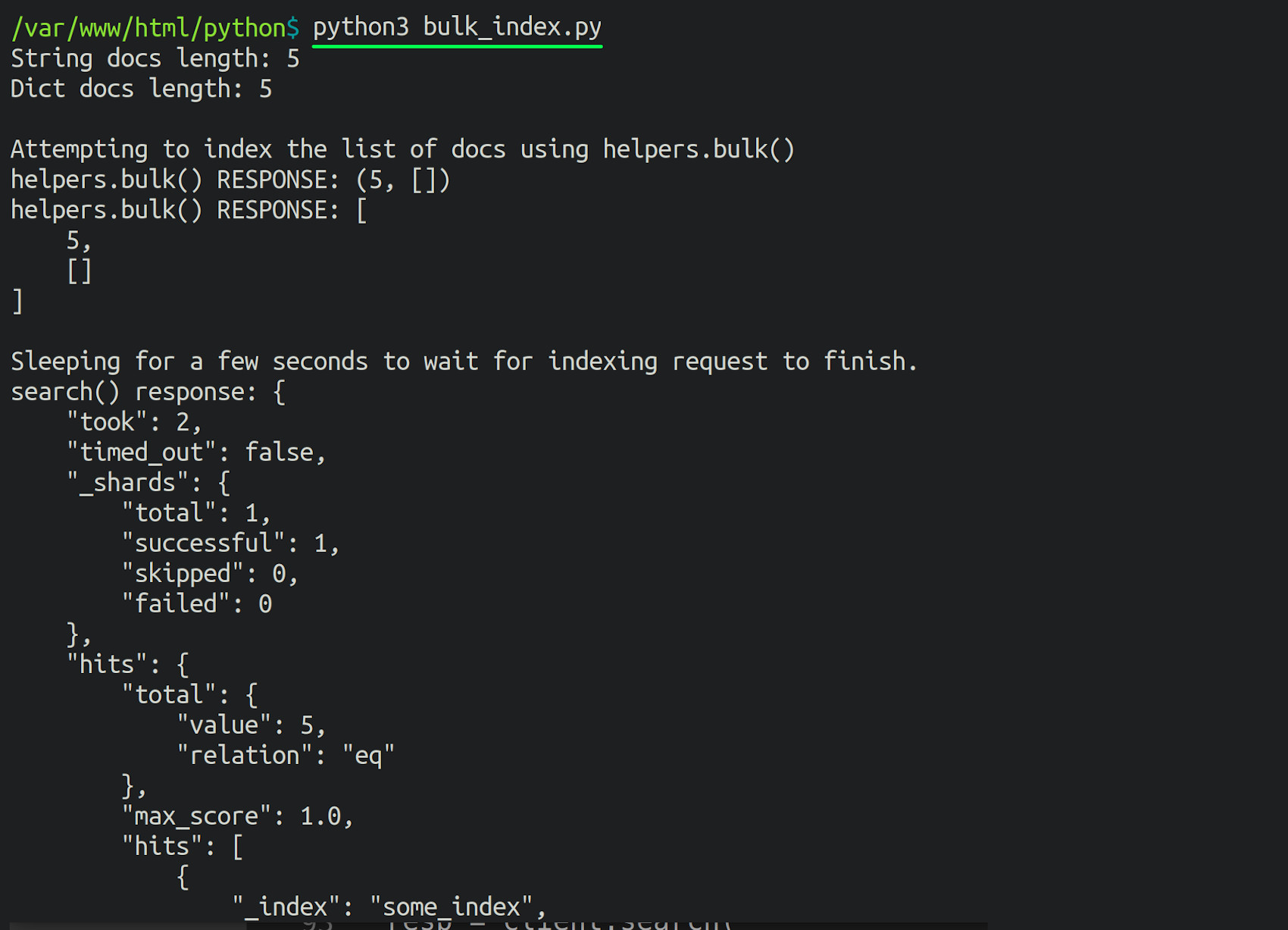
In this article, we’ve explained how to bulk index Elasticsearch documents from a JSON file using Python. We’ve completed our example script; now, all we need to do is run it. We can run the Python script using the python3 command:
1 | python3 bulk_index.py |
The following output should be returned at the end of the script:
1 | Length of docs returned by search(): 5 |
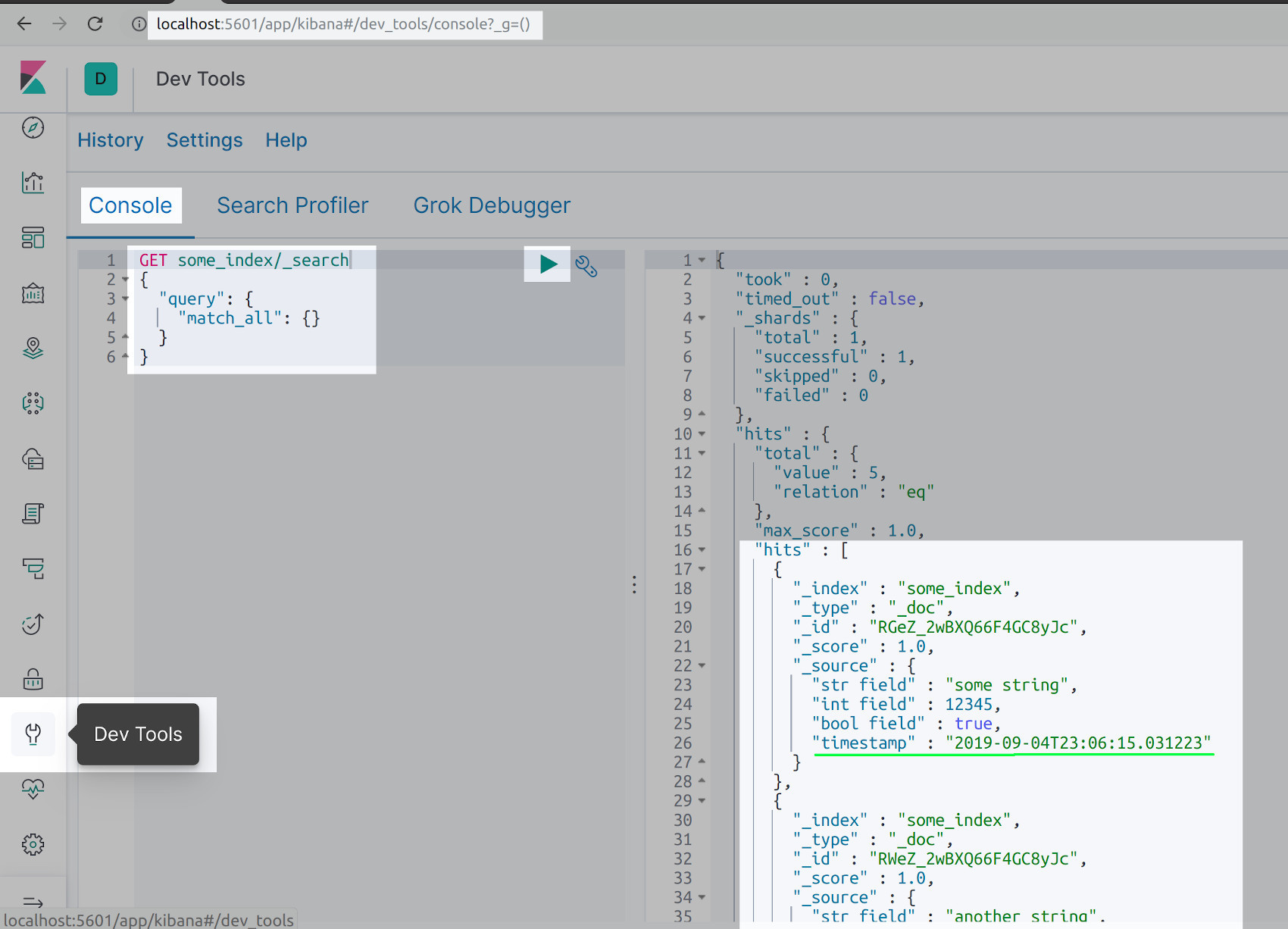
Use Kibana to get the Elasticsearch documents indexed using helpers.bulk()
You can also make an HTTP GET request within Kibana’s Console UI to get all of the documents you just indexed:
1 2 3 4 5 6 | GET some_index/_search { "query": { "match_all": {} } } |
Just the Code
Throughout our tutorial, we looked at the example code one section at a time. In this section, we’ve included the Python script in its entirety:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 | #!/usr/bin/env python3 #-*- coding: utf-8 -*- # import Python's JSON library for its loads() method import json # import time for its sleep method from time import sleep # import the datetime libraries datetime.now() method from datetime import datetime # use the Elasticsearch client's helpers class for _bulk API from elasticsearch import Elasticsearch, helpers # declare a client instance of the Python Elasticsearch library client = Elasticsearch("localhost:9200") """ JSON DATA IN FILE: {"str field": "some string", "int field": 12345, "bool field": True} {"str field": "another string", "int field": 42, "bool field": False} {"str field": "random string", "int field": 3856452, "bool field": True} {"str field": "string value", "int field": 11111, "bool field": False} {"str field": "last string", "int field": 54321, "bool field": True} """ # define a function that will load a text file def get_data_from_text_file(self): # the function will return a list of docs return [l.strip() for l in open(str(self), encoding="utf8", errors='ignore')] # call the function to get the string data containing docs docs = get_data_from_text_file("data.json") # print the length of the documents in the string print ("String docs length:", len(docs)) # define an empty list for the Elasticsearch docs doc_list = [] # use Python's enumerate() function to iterate over list of doc strings for num, doc in enumerate(docs): # catch any JSON loads() errors try: # prevent JSONDecodeError resulting from Python uppercase boolean doc = doc.replace("True", "true") doc = doc.replace("False", "false") # convert the string to a dict object dict_doc = json.loads(doc) # add a new field to the Elasticsearch doc dict_doc["timestamp"] = datetime.now() # add a dict key called "_id" if you'd like to specify an ID for the doc dict_doc["_id"] = num # append the dict object to the list [] doc_list += [dict_doc] except json.decoder.JSONDecodeError as err: # print the errors print ("ERROR for num:", num, "-- JSONDecodeError:", err, "for doc:", doc) print ("Dict docs length:", len(doc_list)) # attempt to index the dictionary entries using the helpers.bulk() method try: print ("\nAttempting to index the list of docs using helpers.bulk()") # use the helpers library's Bulk API to index list of Elasticsearch docs resp = helpers.bulk( client, doc_list, index = "some_index", doc_type = "_doc" ) # print the response returned by Elasticsearch print ("helpers.bulk() RESPONSE:", resp) print ("helpers.bulk() RESPONSE:", json.dumps(resp, indent=4)) except Exception as err: # print any errors returned w ## Prerequisiteshile making the helpers.bulk() API call print("Elasticsearch helpers.bulk() ERROR:", err) quit() # get all of docs for the index # Result window is too large, from + size must be less than or equal to: [10000] query_all = { 'size' : 10_000, 'query': { 'match_all' : {} } } print ("\nSleeping for a few seconds to wait for indexing request to finish.") sleep(2) # pass the query_all dict to search() method resp = client.search( index = "some_index", body = query_all ) print ("search() response:", json.dumps(resp, indent=4)) # print the number of docs in index print ("Length of docs returned by search():", len(resp['hits']['hits'])) """ Length of docs returned by search(): 5 """ |



Pilot the ObjectRocket Platform Free!
Try Fully-Managed CockroachDB, Elasticsearch, MongoDB, PostgreSQL (Beta) or Redis.
Get Started