How to Build an Optical Character Recognition OCR App for an Elasticsearch Index using Python and Tesseract
Introduction to using Google’s Tesseract with Elasticsearch
Python-Tesseract is an optical character recognition, or OCR, tool for Python designed to read text embedded in any image supported by the Leptonica and Pillow imaging libraries. This tutorial will explain how build an optical character recognition OCR Elasticsearch app with Python Tesseract software in Elasticsearch using the PyTesseract library. This will allow for creating string data from an image file that can then be indexed as a document in Elasticsearch.
A screenshot of the ObjectRocket example image used in this tutorial
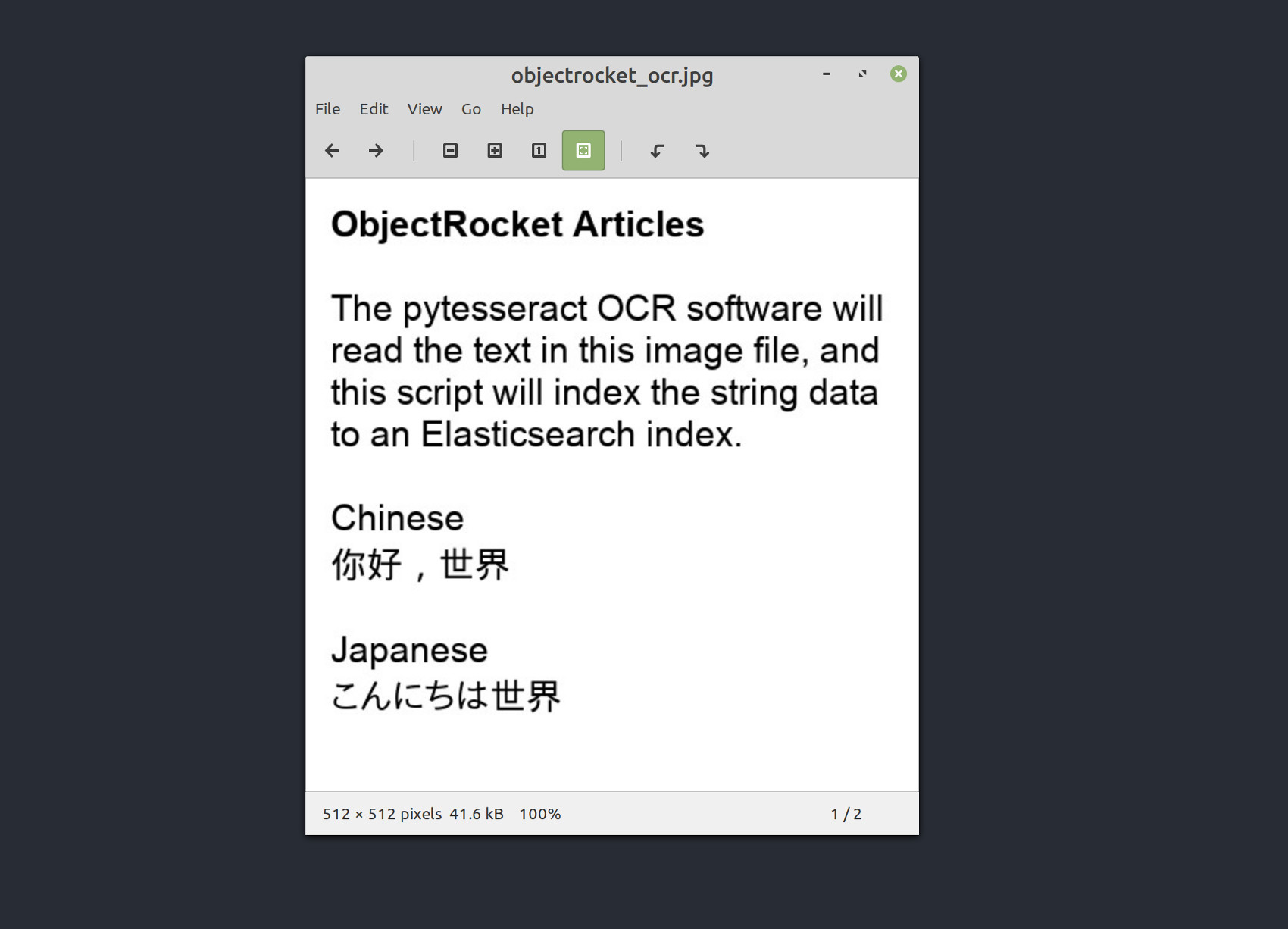
The image intentionally includes some Chinese and Japanese characters to demonstrate that Python 3, Elasticsearch and Tesseract all have multi-language Unicode support.
Prerequisites to Build an Optical Character Recognition, or OCR, Elasticsearch App using the Python Tesseract Library with Elasticsearch
- Have an Elasticsearch cluster running on the same machine or server with the image and Tesseract library installed. Execute the following command to install the Elasticsearch low-level client for Python 3 using the PIP3 package manager:
1 | pip3 install elasticsearch |
- PyTesseract relies on the Python Pillow Imaging Library package. Install both Pillow and the PyTesseract module for Python 3 using the following
pip3command:
1 2 | pip3 install Pillow pip3 install pytesseract |
NOTE: The examples in this tutorial are executed using Python 3. The code examples used here have not been tested with Python 2. The next section supplies instructions for installing the Tesseract software.
How to specify the OCR installation location for PyTesseract on Windows
The PyTesseract OCR installation location must be specified when running this script on a Windows machine. Specify the installation location with the following command:
1 | pytesseract.pytesseract.tesseract_cmd = 'C:\Program Files (x86)\Tesseract-OCR\tesseract.exe' |
How to Install the Tesseract OCR Library for the Elasticsearch Cluster’s Server
If using Windows to run the example Python code in this article, then download the executable installer for Windows.
How to install the Tesseract OCR library on a Debian-based distro of Linux
If using a Debian-based distro of Linux, such as Debian, Linux Mint, or Ubuntu, execute the following command to install the Tesseract dependencies for using the APT-GET repository:
1 | sudo apt-get install libicu-dev libpango1.0-dev libcairo2-dev |
Then use the APT repository to install the Tesseract OCR library:
1 | sudo apt install tesseract-ocr |
How to install the Tesseract library on macOS using Homebrew
To run this Python script in macOS, use the following Homebrew brew command to install the Tesseract library and language support:
1 | brew install tesseract --all-languages |
How to install language support for the Tesseract OCR library in Linux
Execute the following command to install traditional Chinese language support for Tesseract:
1 | sudo apt-get install tesseract-ocr-chi-tra |
Execute the following command to install Japanese language support for Tesseract:
1 | sudo apt-get install tesseract-ocr-jpn |
Following is a screenshot showing the before and after configurations:
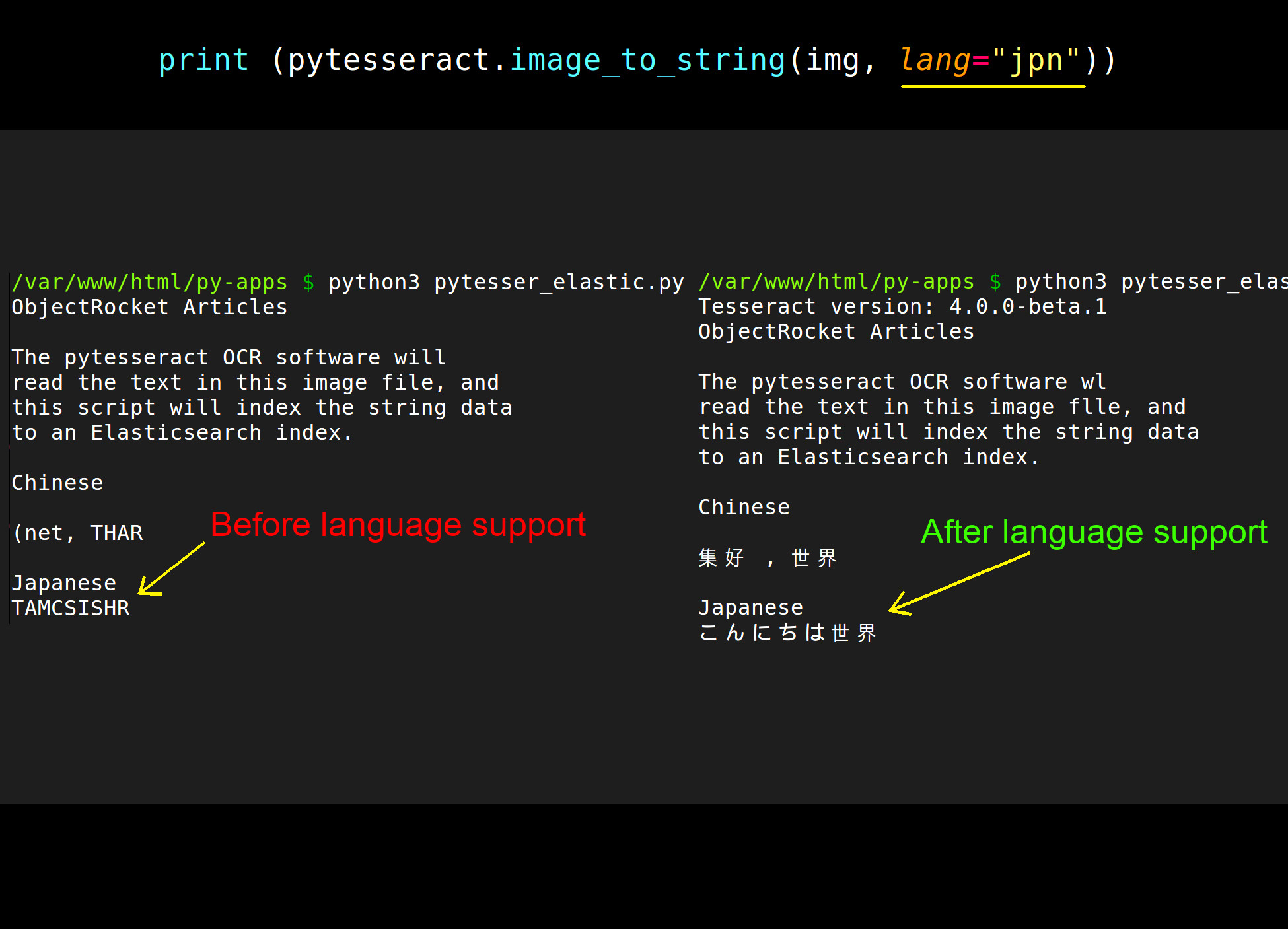
NOTE: Calling the image_to_string() method, with Japanese language support specified in the method call, will likely produce accurate OCR results. This is true even if some of the source text is in both Chinese and Japanese. This is because the Japanese “Kanji” writing system borrowed many of its characters from Chinese. However, notice that the OCR reading of the image did misinterpret “will” as “wl” when using the Japanese language support in the method call.
How to Import the Elasticsearch and PyTesseract Libraries into a Python Script
Once inside the Python script, make sure to import the PyTesseract library and the PIL (Pillow) library for loading and reading image data. Use Python’s JSON library to parse the dictionary response returned by Elasticsearch so both are more readable when printed. Execute the follow script:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | # import the Pytesseract library import pytesseract # import the Image method library from PIL from PIL import Image # import the JSON library for Python for pretty print import json # import the Base64 library for Python for encoding OCR data import base64 # import the datetime() method for timestamps from datetime import datetime # import the Elasticsearch low-level client library from elasticsearch import Elasticsearch |
Additionally, import the Base64 library for Python so the string data parsed from the image can be encoded and indexed as an Elasticsearch document. Note that the datetime.now() method call is used in this tutorial for the Elasticsearch document’s timestamp field.
How to have Python return a string of the Tesseract version installed
Call the PyTesseract library’s get_tesseract_version() method to verify the Tesseract package is installed on the machine running the Elasticsearch cluster:
1 2 3 | # get the version of PyTesseract installed tesseract_ver = pytesseract.get_tesseract_version() print ("Tesseract version:", tesseract_ver) |
How to Declare a Function that will Index Tesseract OCR Data as an Elasticsearch Document
Use the def keyword in Python used to define a new function that will take the image data and file name and then index both into an Elasticsearch document:
1 2 | # Elasticsearch will dynamically create _id by default def index_ocr_data(file, data, doc_id=""): |
The default parameter for the function’s Elasticsearch document _id is an empty string (""). This will cause Elasticsearch to automatically create a dynamically generated alpha-numeric document ID for the user, provided none were passed to the function call.
How to convert the OCR data to a bytes string and encode it with Base64
to pass the data to the bytes() function and use UTF-8 character encoding:
1 2 3 4 | try: # convert PyTesser data to bytes object bytes_string = bytes(str(data), "utf-8") print ("\nPyTesser data bytes_string:", bytes_string) |
Execute the folloing script to acquire the bytes string and encode it using the Base64 library’s b64encode() method:
1 2 | # convert bytes to base64 encoded string encoded_data = base64.b64encode(bytes_string) |
How the Python client returns a mapper_parsing_exception when making an index() API call
To avoid the mapper_parsing_exception error when indexing to Elasticsearch, convert the string of data returned by PyTesseract to a Base64 encoded string before passing it to the Elasticsearch client’s index() method nested inside the document (Python dict) body.
How to Build an Elasticsearch Document from the Encoded OCR Data
Build an Elasticsearch document from the encoded OCR data by passing the encoded data to an Elasticsearch field of the body that will represent the document’s _source data.
How to declare a Python dict object for the Elasticsearch document body
Use the "file name” to record the image’s accompanying file name for the OCR data:
1 2 3 4 5 6 7 8 9 10 11 12 | # create a document body for the new Elasticsearch document doc_body = { "file name": file, "data": encoded_data, "timestamp": datetime.now() } # print the doc body and use json.dumps() for indentation try: print ("\nindex_ocr_data() doc body:", json.dumps(doc_body, indent=4)) except: print ("\nindex_ocr_data() doc body:", doc_body) |
How to Pass the Elasticsearch Dictionary Object to the Python Client’s Index() Method Call
It is critical to pass the entire dict body to the index() method’s body parameter. The following example script uses the request_timeout parameter to instruct it to attempt the API call for two seconds before returning a timeout error:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | # return a result object from Elasticsearch result = client.index( index = INDEX, doc_type = "_doc", id = doc_id, body = doc_body, request_timeout = 2 ) except Exception as error: # returns a set() object of the Elasticsearch error result = {"index_ocr_data ERROR", str(error)} # return the JSON result return result |
The function will return the JSON response returned by Elasticsearch as a Python dictionary object. If an exception is raised, then the function is designed to instead return information about the error.
How to Setup the Global Variables for the Image File and Elasticsearch Index Name
Global variables for the image’s location and file name can be declared outside the function call as can the Elasticsearch index name and client instance of the Elasticsearch Python library. The location of the file need not be specified if it’s located in the same directory as the Python script. to set up the global variables:
1 2 3 4 5 6 7 8 | # file name of the image being indexed into Elasticsearch file_name = "objectrocket_ocr.jpg" # declare global client instance for the index_ocr_data() function client = Elasticsearch(hosts=["localhost:9200"]) # declare global for index name INDEX = "pytesseract_image_data" |
How to Declare a PIL Object Instance of the Image and Retrieve its OCR Data
Use the following script to have the PIL library to return a PIL.JpegImagePlugin object of the image’s data that can then be passed to PyTesseract’s image_to_string() method call to return a string that will, hopefully, contain accurately transcribed text data from the image:
1 2 3 4 5 6 | # return a PIL.JpegImagePlugin Image object of the local image img = Image.open(file_name) print ("img TYPE:", type(img)) # return a string of the image's data by passing the PIL object to the image_to_string() method data_from_image = pytesseract.image_to_string(img, lang="jpn") |
The above example passes the string "jpn" to the method’s lang parameter so the OCR software knows to look for Japanese writing in the image.
How to Call the Index_OCR_Data( ) Function and Print the API Response from Elasticsearch
Call the index_ocr_data() function declared earlier and pass the image’s file name and OCR data to its function calls:
1 2 | # call the index_ocr_data() function and return the response resp = index_ocr_data(file_name, data_from_image) |
NOTE: The option exists to pass a document _id parameter to the function call, such as doc_id=42, to explicitly choose the document’s ID.
How to print the OCR function’s JSON response from Elasticsearch
Print the response returned by the function call:
1 2 3 4 5 6 | # print the results of the API call made to Elasticsearch print ("\nRESULT:") if type(resp) == dict: print ("index_ocr_data() resp:", json.dumps(resp, indent=4)) else: print ("index_ocr_data() resp:", resp) |
At this point in the code the Base64 encoded OCR data, retrieved from the image, will have been indexed in Elasticsearch as a document’s _source data when the script is executed.
How to run the Python script to get the OCR data from the image and index it in Elasticsearch
Navigate to the directory containing the Python script and execute the following code using the python3 command:
1 | python3 pytesser_elastic.py |
How to use Kibana to verify the encoded Tesseract OCR data was actually indexed in Elasticsearch
If the Kibana Console UI is installed and open in a browser tab, a GET HTTP request can be made to retrieve the Base64 encoded OCR data stored on the pytesseract_image_data Elasticsearch index. Execute the following GET command:
1 | GET pytesseract_image_data/_search |
The result should resemble the following:
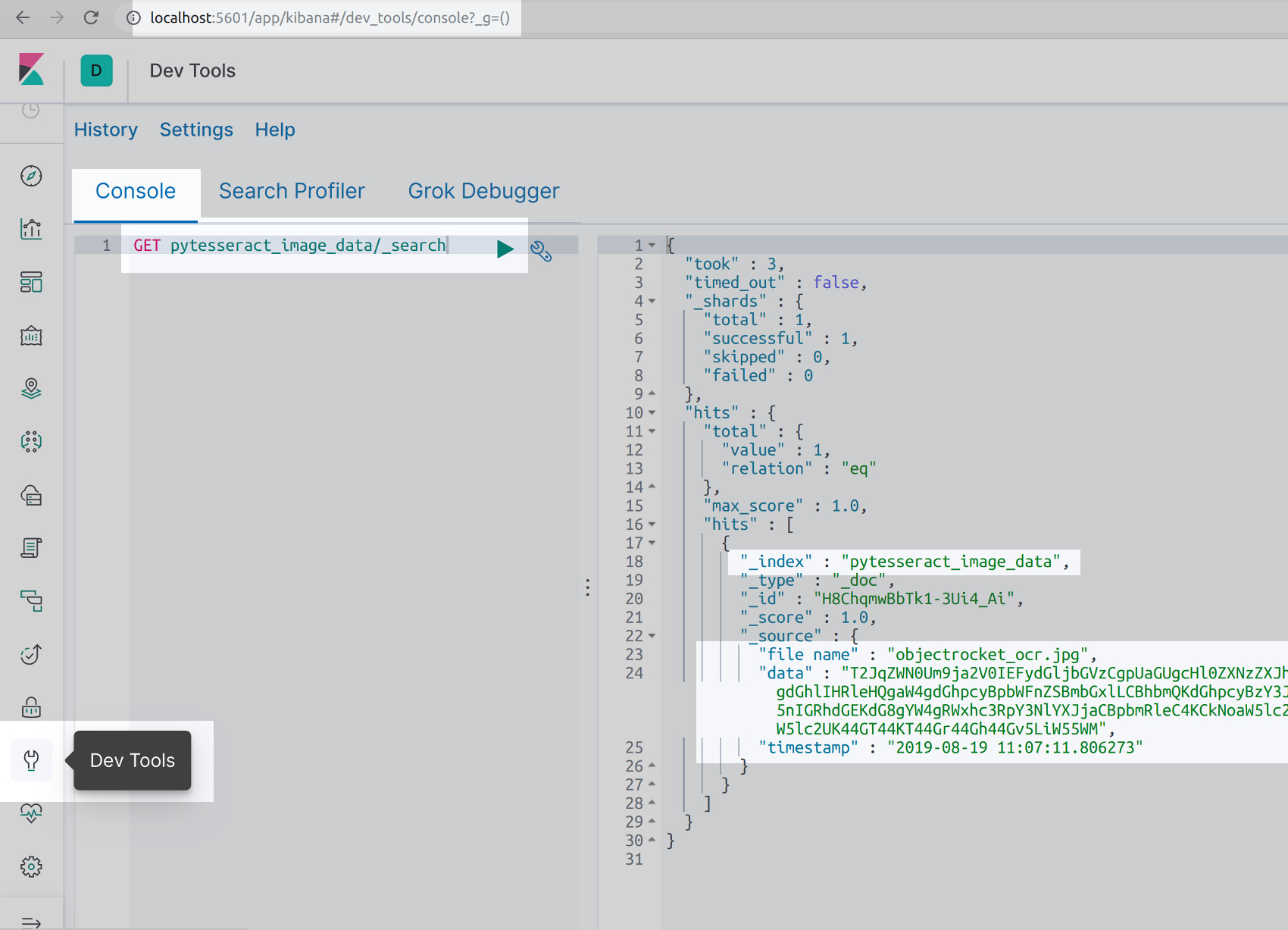 As shown in the above screenshot, the OCR data is an unreadable, encoded Base64 string. Another call must be made to Elasticsearch and the string decoded in order to read the indexed text from the image file. Alternatively, copy and paste the encoded string into another application to have it decoded.
As shown in the above screenshot, the OCR data is an unreadable, encoded Base64 string. Another call must be made to Elasticsearch and the string decoded in order to read the indexed text from the image file. Alternatively, copy and paste the encoded string into another application to have it decoded.
How to use the Elasticsearch Python client’s get( ) method to retrieve the PyTesseract document data
After the OCR data has been indexed as an Elasticsearch document, the Python client’s get() method can be used to retrieve the Base64 encoded data. It can then be decode back into a string to verify the OCR image data was indexed and stored successfully. Execute the following script:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | # get the data indexed and convert back into a string try: # get the indexed doc _id from response dict doc_id = resp["_id"] # pass the doc _id to the client's get() method doc_info = client.get( index = INDEX, id = doc_id ) # print the entire JSON document response from get() print ("doc_info reponse:", json.dumps(doc_info, indent=4)) # get the _source field's data stored from image source_data = doc_info["_source"]["data"] # decode the base64 data returned from Elasticsearch decoded_data = base64.b64decode(source_data).decode("utf-8") print ("\ndecoded_data:", decoded_data) except Exception as error: print ("Elasticsearch client get() ERROR:", error) |
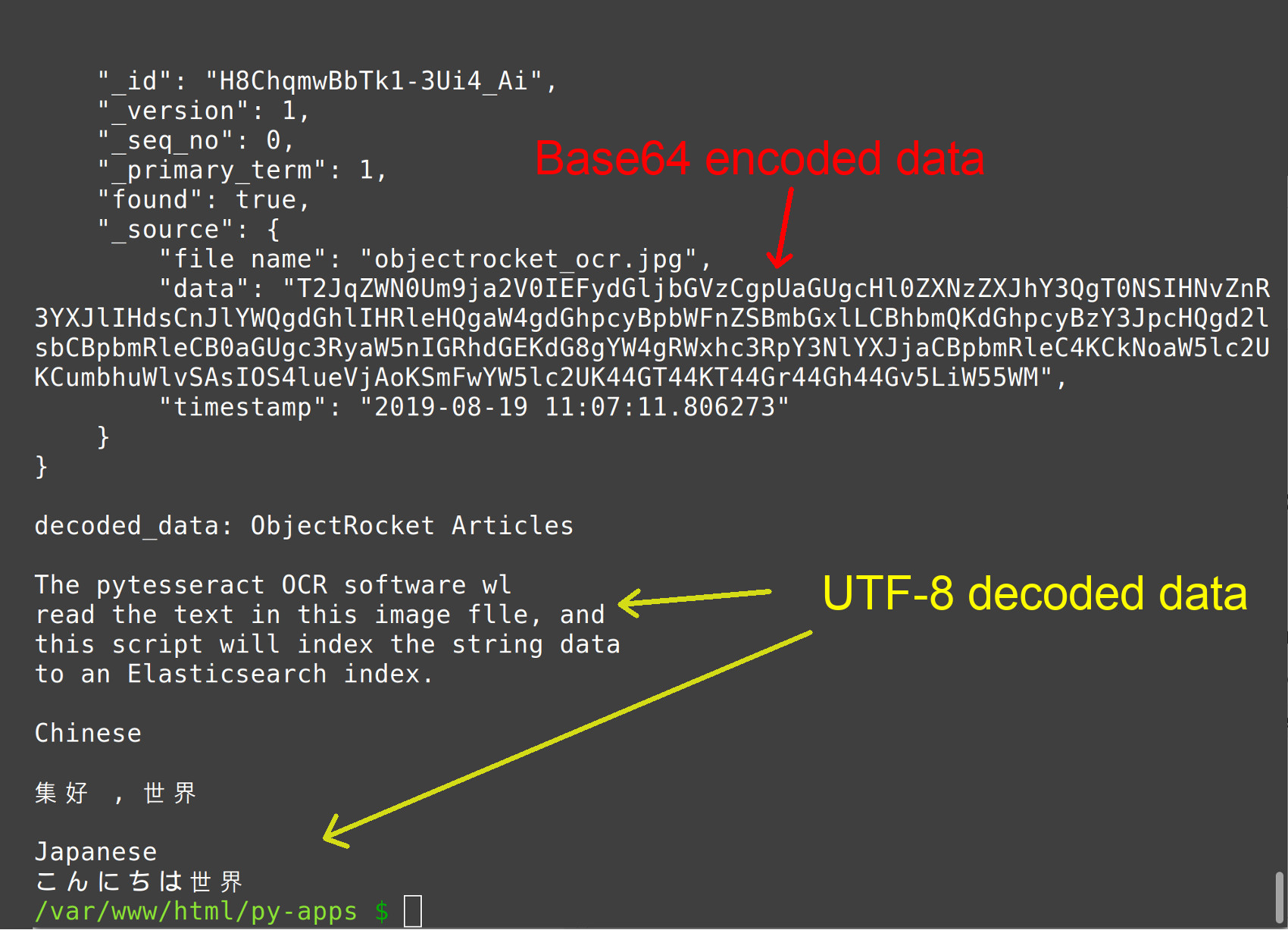
The results should look like the following screenshot:
Conclusion
This tutorial covered how build an optical character recognition, or OCR, Elasticsearch app with Python Tesseract software in Elasticsearch using the PyTesseract library. The article specifically explained how to specify the OCR installation location for PyTesseract on Windows, Linux and macOS. The tutorial also covered how to import the Elasticsearch and PyTesseract libraries into a Python Script, convert the OCR data to a bytes string and encode it with Base64, pass the Elasticsearch dictionary object to the Python client’s index( ) method call and setup the global variables for the image file and Elasticsearch index name. Finally, the tutorial covered how to print the OCR function’s JSON response from Elasticsearch, how to use Kibana to verify the encoded Tesseract OCR data was indexed in Elasticsearch and how to use the Elasticsearch Python client’s get( ) method to retrieve the PyTesseract document data. Remember that all the examples in this tutorial were executed with Python 3 and Python 2 has not been tested with these scripts.
Just the Code
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 | #!/usr/bin/env python3 #-*- coding: utf-8 -*- # import the Pytesseract library import pytesseract # import the Image method library from PIL from PIL import Image # import the JSON library for Python for pretty print import json # import the Base64 library for Python for encoding OCR data import base64 # import the datetime() method for timestamps from datetime import datetime # import the Elasticsearch low-level client library from elasticsearch import Elasticsearch # get the version of Tesseract installed tesseract_ver = pytesseract.get_tesseract_version() print ("Tesseract version:", tesseract_ver) # Elasticsearch will dynamically create _id by default def index_ocr_data(file, data, doc_id=""): try: # convert PyTesser data to bytes object bytes_string = bytes(str(data), "utf-8") print ("\nPyTesser data bytes_string:", bytes_string) # convert bytes to base64 encoded string encoded_data = base64.b64encode(bytes_string) # create a document body for the new Elasticsearch document doc_body = { "file name": file, "data": encoded_data, "timestamp": datetime.now() } # print the doc body and use json.dumps() for indentation try: print ("\nindex_ocr_data() doc body:", json.dumps(doc_body, indent=4)) except: print ("\nindex_ocr_data() doc body:", doc_body) # return a result object from Elasticsearch result = client.index( index = INDEX, doc_type = "_doc", id = doc_id, body = doc_body, request_timeout = 2 ) except Exception as error: # returns a set() object of the Elasticsearch error result = {"index_ocr_data ERROR", str(error)} # return the JSON result return result # file name of the image being indexed into Elasticsearch file_name = "objectrocket_ocr.jpg" # declare global client instance for the index_ocr_data() function client = Elasticsearch(hosts=["localhost:9200"]) # declare global for index name INDEX = "pytesseract_image_data" # return a PIL.JpegImagePlugin Image object of the local image img = Image.open(file_name) print ("img TYPE:", type(img)) # return a string of the image's data by passing the PIL object to the image_to_string() method data_from_image = pytesseract.image_to_string(img, lang="jpn") # call the index_ocr_data() function and return the response resp = index_ocr_data(file_name, data_from_image) # print the results of the API call made to Elasticsearch print ("\nRESULT:") if type(resp) == dict: print ("index_ocr_data() resp:", json.dumps(resp, indent=4)) else: print ("index_ocr_data() resp:", resp) # get() the OCR data indexed in Elasticsearch and decode it try: # get the indexed doc _id from response dict doc_id = resp["_id"] # pass the doc _id to the client's get() method doc_info = client.get( index = INDEX, id = doc_id ) # print the entire JSON document response from get() print ("doc_info reponse:", json.dumps(doc_info, indent=4)) # get the _source field's data stored from image source_data = doc_info["_source"]["data"] # decode the base64 data returned from Elasticsearch decoded_data = base64.b64decode(source_data).decode("utf-8") print ("\ndecoded_data:", decoded_data) except Exception as error: print ("Elasticsearch client get() ERROR:", error) |


Pilot the ObjectRocket Platform Free!
Try Fully-Managed CockroachDB, Elasticsearch, MongoDB, PostgreSQL (Beta) or Redis.
Get Started