Guide How To Create Test Data In Python And Convert It Into An Elasticsearch JSON File
Introduction
- If you have a large dataset that is stored as a nested dictionary in Python code, and you want to be able to use it in Elasticsearch, it must be formatted for compatibility. This tutorial will show the method to convert that Python data into a JSON file that the Elastic search engine can use. The information contained here will explain every step in the process and provide valuable links to more documentation on related topics. This tutorial is also very useful if you want/need to learn how to generate random test data in the Python language and then use it with the Elastic Stack.
Prerequisites:
This article assumes the user is on a UNIX-based machine, like macOS or Linux, but the Python code will work on Windows machines as well.
It’s recommended that you use Python 3 since Python 2 is depreciating by 2020.
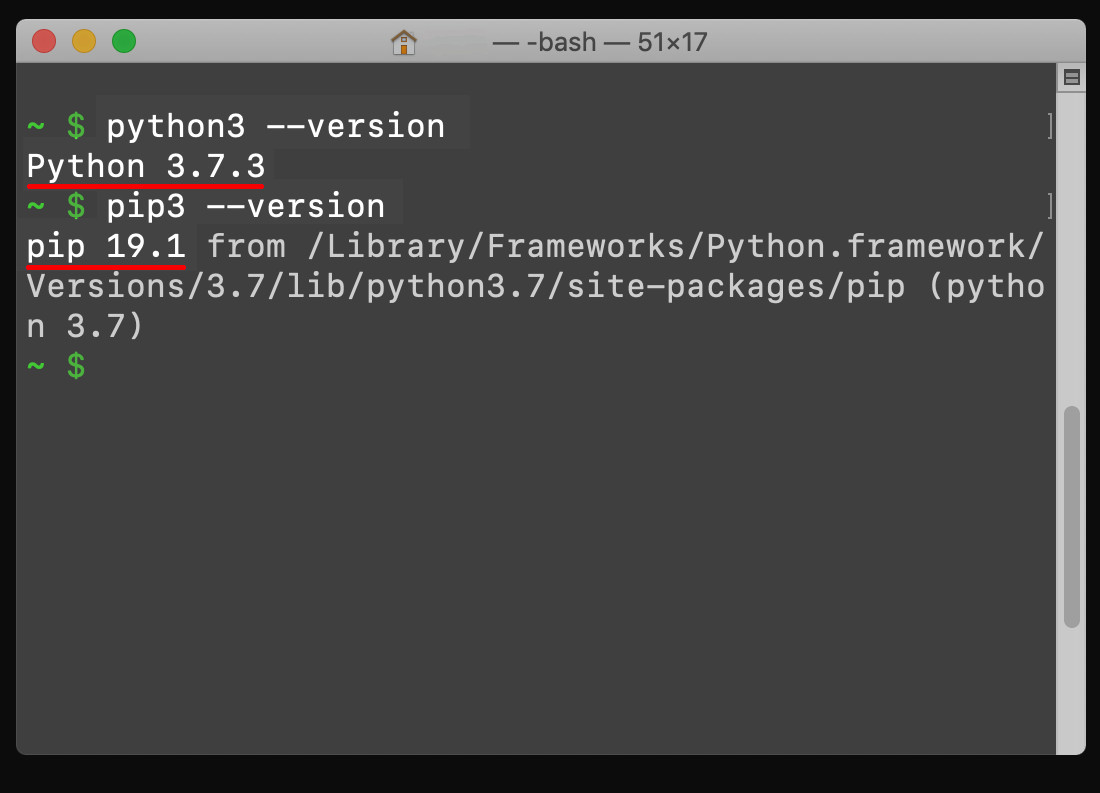
Get the latest stable release of Python 3.
- The Python 3 commands for
python3and thepip3package manager each respectively follow this format (ending with a3) :
1 2 | python3 some_script.py pip3 install examplemodule |
- The Elastic Stack needs to be installed and running in order to import data into the target cluster. Be sure to have an existing index created on your cluster that you can put the Python data into.
- Have SSH access to your server with a private key
Structure of a Python Nested Dictionary:
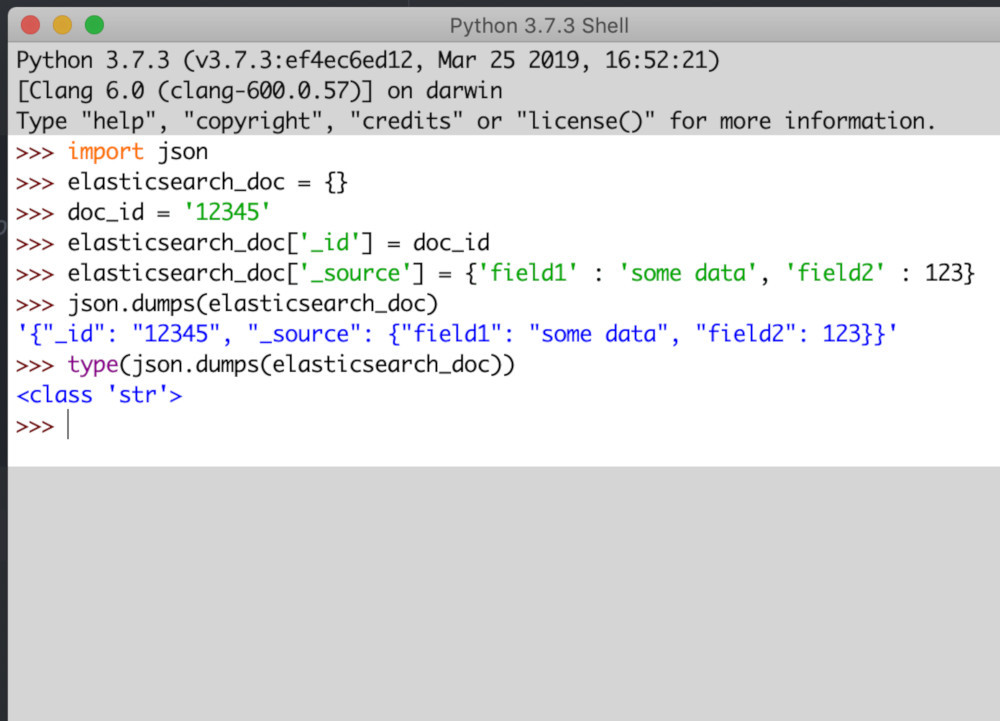
- A Python nested dictionary is essentially a dictionary inside of a dictionary
- The
jsonPython module takes a dictionary and converts it into a JSON file:
Setup the Python Script:
- Create a new directory for the Python app:
1 2 | mkdir python2elastic cd python2elastic |
- If you haven’t created the Python script yet, you can use touch to create one:
1 | sudo touch elastic_json.py |
Edit the Python Script:
Use
nanoto edit the script if you’re using a UNIX terminal.Once you’re inside the file, import the
jsonPython module that was included with “The Python Standard Library”:
1 | import json |
Importing Python Modules:
- Import the
uuidandrandomlibraries so that you can generate test data using random UUID’s for the Elasticsearch documents’ keys:
1 | import uuid, random |
- Other modules to import as well:
1 | import os, pickle |
Create a Randomized Python Dictionary:
- If you want to start with creating some test data, you can use this code to randomly generated values and then stick them into a nested Python dictionary:
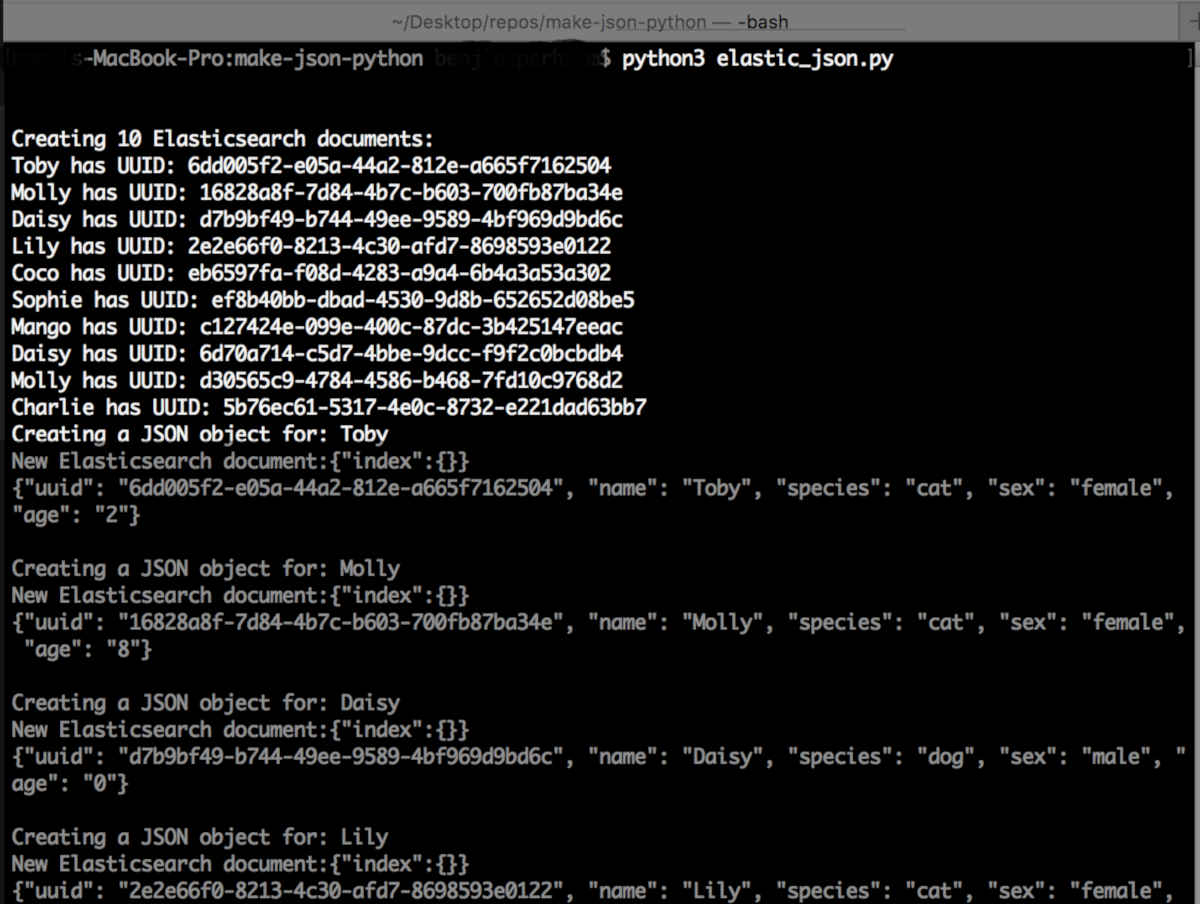
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 | # create an empty dictionary test_data = {} # specify the number of keys (or 'documents') to create total_documents = 10 print ("\n\nCreating " + str(total_documents) + " Elasticsearch documents:") for key in range(total_documents): # give each pet document a UUID new_uuid = uuid.uuid4() # convert UUID to string new_uuid = str(new_uuid) # create a nest dictionary which represents the Elasticsearch document test_data[new_uuid] = {} # list for pet's name names = ['Bailey', 'Bear', 'Buddy', 'Charlie', 'Coco', 'Cosmo', 'Daisy', 'Lily', 'Lola', 'Maggy', 'Mango', 'Molly', 'Sadie', 'Sophie', 'Sunny', 'Tiger', 'Toby'] # randomly select a name name = names[random.randint(0, len(names)-1)] # randomly select a dog or cat species = ['dog', 'cat'][random.randint(0, 1)] # randomly select the sex of the pet sex = ['male', 'female'][random.randint(0, 1)] # NOTE: The value for an Elasticsearch JSON document's field MUST # be a string, regardless of the actual data type age = str(random.randint(0, 10)) # randomly select the age of the pet # put all of the values into the dictionary test_data[new_uuid]['uuid'] = new_uuid test_data[new_uuid]['name'] = name test_data[new_uuid]['species'] = species test_data[new_uuid]['sex'] = sex test_data[new_uuid]['age'] = age # print the UUID and name of the JSON document print (name + " has UUID: " + new_uuid) |
Serialize the Python Dictionary with Pickle for Later Use:
- Optionally, you can also serialize (using
pickle.dump) the randomized data if you want to store it for later use:
1 2 3 | # serialize the data with open('pets.pickle', 'wb') as handle: pickle.dump(test_data, handle, protocol=pickle.HIGHEST_PROTOCOL) |
- If you don’t want to create any test data, but you already have data serialized, pickle also has a
loadmethod to access it:
1 2 | with open('pets.pickle', 'rb') as handle: test_data = pickle.load(handle) |
Create the Elasticsearch Documents from the Dictionary:
- Copy the dictionary’s keys and their respective values. Then from those values, create a new JSON string that is compatible with an Elasticsearch JSON file. Next, you can use the Python
jsonlibrary’s built-in method calleddumpsto convert any Python dictionaries into JSON objects. This code will duplicate the dictionary values and make a new string to represent the Elasticsearch document. Finally, all of the documents will be put into an empty list like this:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | # create an empty list for the JSON documents document_list = [] # iterate over the keys and values of the nested dictionary for key, val in test_data.items(): # create a pet variable to represent the Elasticsearch document pet = test_data[key] # print a message about the pet print ("Creating a JSON object for: " + pet['name']) ''' Elasticsearch requires this 'index' field for every document. Each linebreak and "index" represents a single JSON document. Use '\n' for linebreaks: ''' json_string = '{"index":{}}\n' + json.dumps(pet) + '\n' print ("New Elasticsearch document:" + json_string) # append the document string to the list document_list += [json_string] ''' Elasticsearch requires this 'index' field for every document. Each linebreak and "index" represents a single JSON document. Use '\n' for linebreaks: ''' json_string = '{"index":{}}\n' + json.dumps(pet) + '\n' print ("New Elasticsearch document:" + json_string) # append the document string to the list document_list += [json_string] |
Copy the Document List and Append Each Line to a JSON File:
- The list containing all the document strings is now ready to be put into a JSON document:
1 2 3 4 | # Copy the list and write each document to a JSON file called "data.json" for doc in document_list: with open("data.json", 'a') as log: log.write(doc) |
Add the JSON Documents to an Elasticsearch Index:
- Save the Python script and execute it in a terminal with
python3:
1 | python3 elastic_json.py |
Push the .json file to your server:
- Use
scpcommand in your terminal to push the JSON file to your server using a private key, but (make sure you replace{SERVER_IP}with the correct web server’s IP address:
1 | sudo scp -i /path/to/private/key data.json root@{SERVER_IP}:/some/directory/on/server |
Use the Elasticsearch _bulk_ API to Push the Data to an Index:
- Use a
PUTcURL request to put the JSON data you created with our Python script into an Elasticsearch index:
1 | curl -s -XPUT 'localhost:9200/pets/pets/_bulk?pretty' -H 'Content-Type: application/json' --data-binary @data.json |
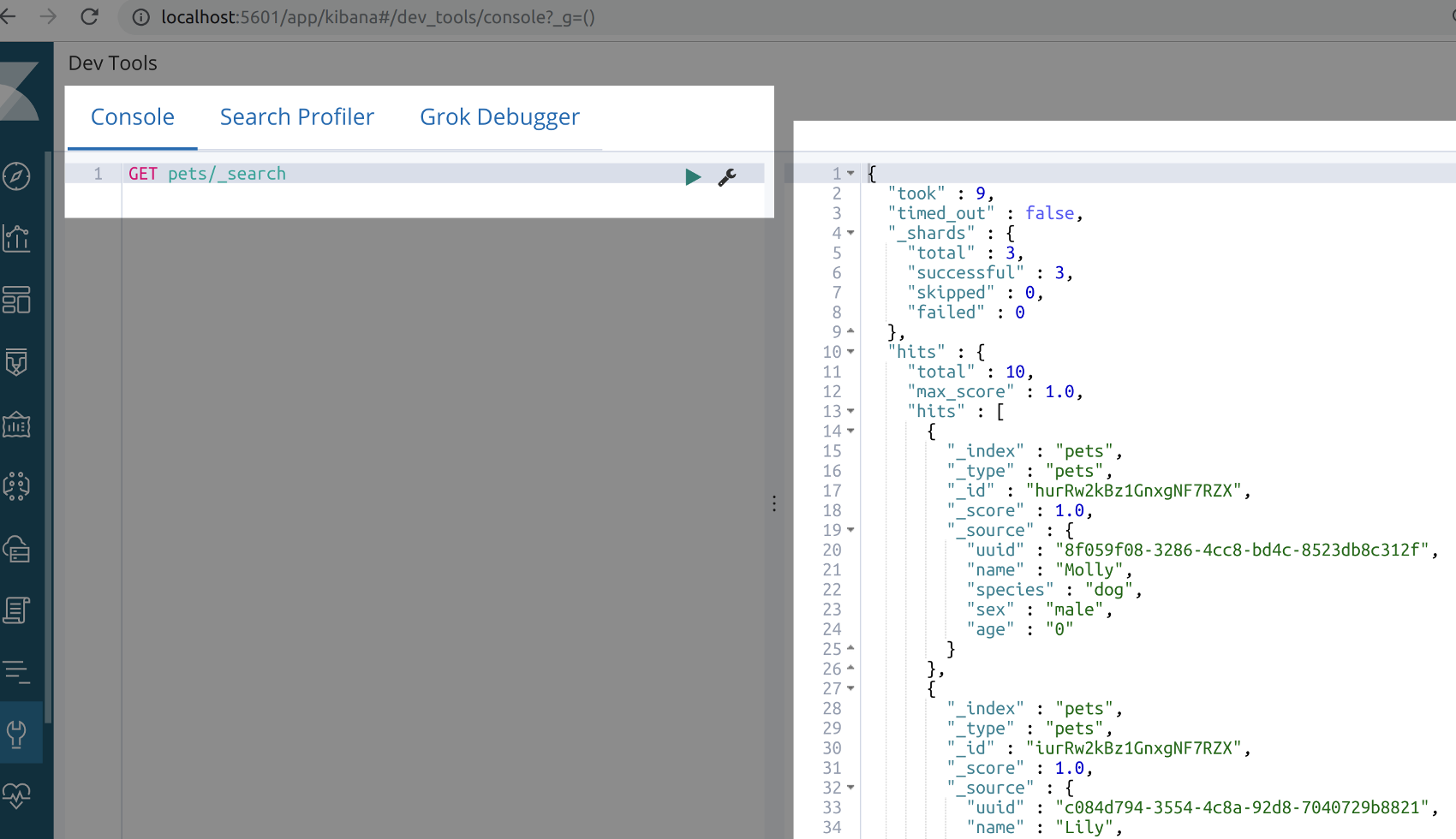
- Voilà! Using the Kibana Console UI we can verify that the data is indeed in the index. There are now 10 documents in the index:
Conclusion
Once you have finished following the procedure explained here, you will have a much better understanding of how to manipulate your Python files for Elastic use. This opens up a whole new resource for adding to your Elasticsearched database network. In addition, it also creates a connection to a host of other programs that are already producing data in Python. Thus, this new ability enables you to begin constructing a more functional network across multiple datatypes, which can all be rapidly accessed with the Elasticsearch service. To see what else can be done with this remarkable platform, look at our other operations and installations we’ve made walkthroughs for.
Just the Code
NOTE: The complete Python script to create randomized JSON objects to use as Finished Elasticsearch Documents Python Script:
- If all you need is the technical stuff, we have the isolated script in its entirety, for your convenience below:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 | #!/usr/bin/env python3 #-*- coding: utf-8 -*- import json, uuid, random import os, pickle # create an empty dictionary test_data = {} # specify the number of keys (or 'documents') to create total_documents = 10 print ("\n\nCreating " + str(total_documents) + " Elasticsearch documents:") for key in range(total_documents): # give each pet document a UUID new_uuid = uuid.uuid4() # convert UUID to string new_uuid = str(new_uuid) # create a nest dictionary which represents the Elasticsearch document test_data[new_uuid] = {} # list for pet's name names = ['Bailey', 'Bear', 'Buddy', 'Charlie', 'Coco', 'Cosmo', 'Daisy', 'Lily', 'Lola', 'Maggy', 'Mango', 'Molly', 'Sadie', 'Sophie', 'Sunny', 'Tiger', 'Toby'] # randomly select a name name = names[random.randint(0, len(names)-1)] # randomly select a dog or cat species = ['dog', 'cat'][random.randint(0, 1)] # randomly select the sex of the pet sex = ['male', 'female'][random.randint(0, 1)] # NOTE: The value for an Elasticsearch JSON document's field MUST # be a string, regardless of the actual data type age = str(random.randint(0, 10)) # randomly select the age of the pet # put all of the values into the dictionary test_data[new_uuid]['uuid'] = new_uuid test_data[new_uuid]['name'] = name test_data[new_uuid]['species'] = species test_data[new_uuid]['sex'] = sex test_data[new_uuid]['age'] = age # print the UUID and name of the JSON document print (name + " has UUID: " + new_uuid) # serialize the data with open('pets.pickle', 'wb') as handle: pickle.dump(test_data, handle, protocol=pickle.HIGHEST_PROTOCOL) ''' with open('pets.pickle', 'rb') as handle: test_data = pickle.load(handle) ''' # create an empty list for the JSON documents document_list = [] # iterate over the keys and values of the nested dictionary for key, val in test_data.items(): # create a pet variable to represent the Elasticsearch document pet = test_data[key] # print a message about the pet print ("Creating a JSON object for: " + pet['name']) ''' Elasticsearch requires this 'index' field for every document. Each linebreak and "index" represents a single JSON document. Use '\n' for linebreaks: ''' json_string = '{"index":{}}\n' + json.dumps(pet) + '\n' print ("New Elasticsearch document:" + json_string) # append the document string to the list document_list += [json_string] # iterate over the list and write each document to a JSON file called "data.json" for doc in document_list: with open("data.json", 'a') as log: log.write(doc) |

Pilot the ObjectRocket Platform Free!
Try Fully-Managed CockroachDB, Elasticsearch, MongoDB, PostgreSQL (Beta) or Redis.
Get Started