Elasticsearch Python Index Example
Introduction
Elasticsearch is the lightning speed search and analytics power engine that helps businesses just like yours discover solutions to their use cases. Couple it with Python, the programming language that streamlines system integration, and you have the most sensible way to index a document in Elasticsearch. This tutorial shows you how to index an Elasticsearch document using Python and gives an Elasticsearch Python index example. Learn how to increase your productivity in daily document indexing activities today.
If you’re familiar with indexing an Elasticsearch document using Python, you can jump to Just the Code.
Prerequisites
Install and run Elasticsearch. To get Elasticsearch, you can also go to a terminal window, use the
curl - XGET "localhost:9200". You’re making an HTTP request. Alternatively, use the address bar of a tab in a browser and go tolocalhost:9200there.Install Python for your OS. When finished, enter in
python --versionin a terminal window to confirm the latest Python version is on your OS. Use Python 3 or later because Python 2.7 is outdated.
Check the Elasticsearch cluster for indexes
Save time and forgo taking steps in advance for index creating prior to Elasticsearch document indexing. If there isn’t an index present for a document you’re trying to index, one will be created in a dynamic way while you attempt to index that document.
- Verify all Elasticsearch indexes on the cluster with this
cURL -XGETrequest:
1 | curl -XGET "localhost:9200/_cat/indices" |
Make an API index call script in Python
In a UNIX-based system terminal, enter the command
mkdirand on your server, construct a project directory.The command
touchis what you’ll use to create the script in Pythonpy.Here’s the script in action:
1 2 3 4 5 | mkdir elastic-project cd elastic-project touch index_doc.py |
>NOTE If you receive access errors, use sudo commands.
Complete the editing for the script
- Here’s an example of the
nanoscript editor being used to edit the Python script:
1 | nano index_doc.py |
Make a client Elasticsearch library importation
*The import function is what you’ll use to add to the Python script the client Elasticsearch library:
1 2 3 | # import the Elasticsearch low-level client library from elasticsearch import Elasticsearch |
Add the library datetime for timestamping
- The document you’re indexing for this Elasticsearch Python index example needs the library
datetime. This gives the document a timestamp of when it was indexed:
1 2 3 | # import the dateime lib for an index timestamp import datetime |
Proclaim a Python client instance for the library Elasticsearch
- Make a Python client instance declaration. Put in the parameter
hoststhe name of the domain or the IP address of your server so they’ll match the client instance.
1 2 3 | # domain name, or server's IP address, goes in the 'hosts' list client = Elasticsearch(hosts=["localhost:9200"]) |
Find additional information about the cluster in Elasticsearch
- The attributes of the client library Elasticsearch can be found in Python using the function
dir().
1 | dir(client) |
Obtain the version of the client Elasticsearch
- Use the
info()method of the client object to get information about the specific cluster:
1 2 3 4 5 | # print the Elasticsearch client instance print (client) print ("Elasticsearch client version:", client.info()["version"], "\n") |
- You should see a response of the
dictobject that is similar to this Elasticsearch Python index example:
1 | Elasticsearch client version: {'number': '7.2.0', 'build_flavor': 'default', 'build_type': 'tar', 'build_hash': '508c38a', 'build_date': '2019-06-20T15:54:18.811730Z', 'build_snapshot': False, 'lucene_version': '8.0.0', 'minimum_wire_compatibility_version': '6.8.0', 'minimum_index_compatibility_version': '6.0.0-beta1'} |
- Besides the
index()method, the client library Elasticsearch has an extensive list of method calls available. Here’s what the list of attributes looks like:
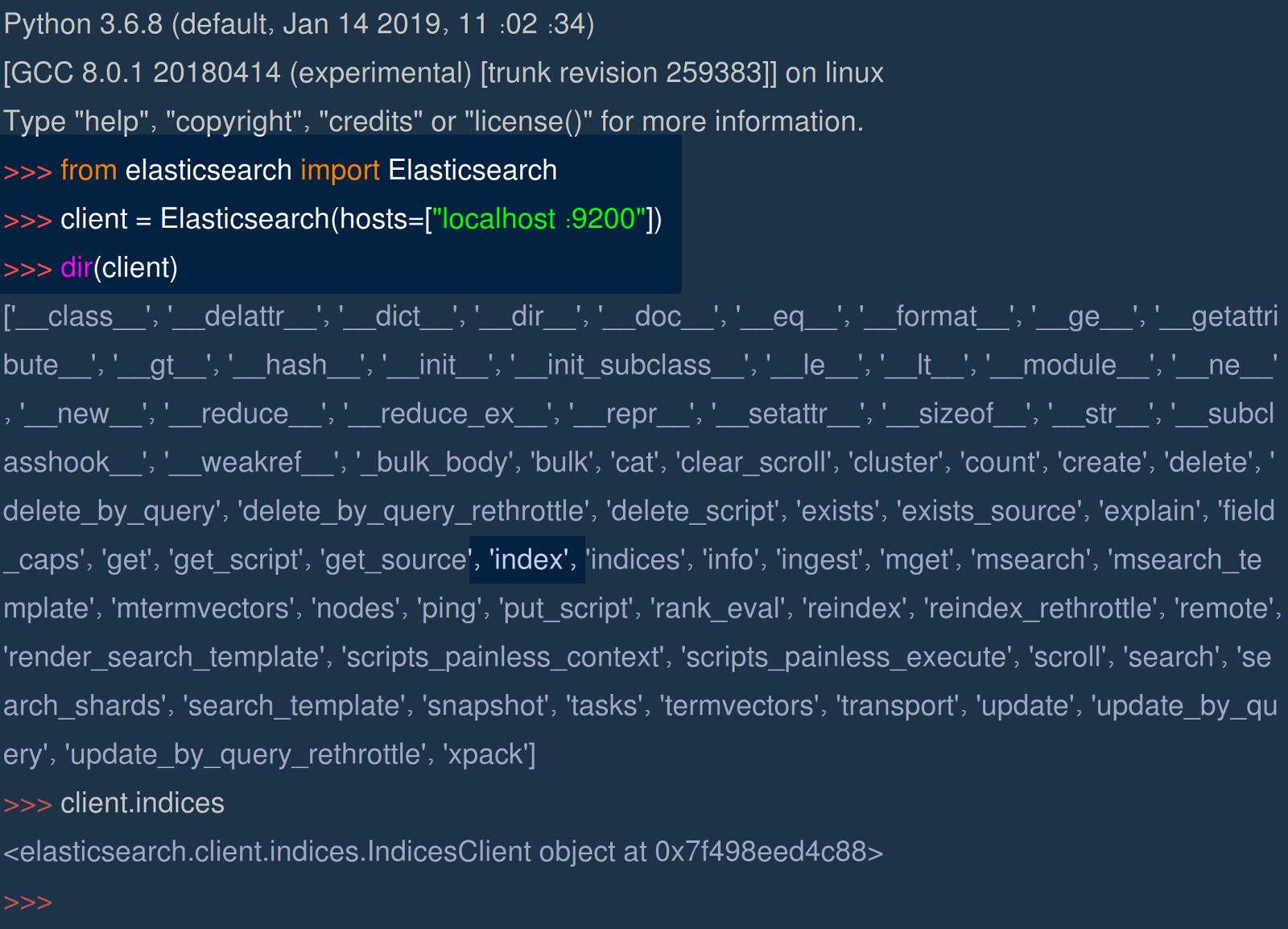
Make a statement for the index name Elasticsearch
- Compose a declaration to make global variables the
_idof the document and its index name so you can pass them to the methodindex().
1 2 3 4 5 | # declare the Elasticsearch index name and document _id INDEX_NAME = "some_index" DOC_ID = 1234 |
Run an index check to determine if it exists
- Use the
index-existsfunction like this to find out if there’s already an Elasticsearch index:
1 2 3 4 5 6 7 8 9 10 11 | # the Elasticsearch index exists index_exists = client.indices.exists(index=INDEX_NAME) # check if the Elasticsearch index exists if index_exists == False: # the Elasticsearch index name does not exist print ("INDEX_NAME:", INDEX_NAME, "does not exist.") |
NOTE:When you make an API Index call, an index will be created if there wasn’t one present.
Proclaim the Elasticsearch Python dictionary
Make a method call to the library
index()of the client by passing thedictPython object. Note that the dictionary keys of Python mirror the index fields of Elasticsearch.See this document example to get an idea of what it should resemble:
1 2 3 4 5 6 7 8 9 10 11 12 13 | # create a document body for the new Elasticsearch document doc_body = { "str field": "Object Rocket", "int field": 1234, "bool field": True, "time field": datetime.datetime.now() } |
How to avoid a mapper_parsing_exception
- When you index your document, you might see a
mapper_parsing_exceptionand an HTTP 400 type of error returned from theindex()method. To avoid this, be sure the schemas of thedictPython and the indexes that pre-existed match.
1 | elasticsearch.exceptions.RequestError: RequestError(400, 'mapper_parsing_exception', 'failed to parse') |
Make a method call to the index() of the client object
You’ll want to get an API Elasticsearch cluster response after you make a method call to the
index()of the client object.This example shows you how an indentation block called “try-catch” identifies exceptions returned from the API. Afterward, it prints the results to the terminal.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | # use a try-catch block for any Elasticsearch index() exceptions try: # call the Elasticsearch client's index() method response = client.index( index = INDEX_NAME, doc_type = '_doc', id = DOC_ID, body = doc_body, request_timeout=45 ) # print the API response returned by the Elasticsearch client print ("response:", response) except Exception as err: print ("Elasticsearch index() ERROR:", err) |
Know what an API response Elasticsearch returned should resemble
- The response
dictobject returned by the Elasticsearch cluster is ready for you to review and determine if the method callindex()worked properly.
1 | response: {'_index': 'some_index', '_type': '_doc', '_id': '1234', '_version': 1, 'result': 'created', '_shards': {'total': 2, 'successful': 1, 'failed': 0}, '_seq_no': 0, '_primary_term': 1} |
Evaluate the Elasticsearch API response returned
- The indicator of a successful API response is that you’ll see a value in the integer format for the key
["_shards"]["successful"].
1 2 3 4 5 6 7 8 9 | # evaluate the response dict object to check that the API was successful if response["_shards"]["successful"] == 1: print ("INDEX CALL WAS SUCCESS:", response["_shards"]["successful"]) else: print ("INDEX CALL FAILED") |
Confirm a successful response with a request HTTP cURL
- In a window from the terminal, verify if an API response was successful by making a request HTTP cURL.
1 | curl -XGET "http://localhost:9200/some_index/_doc/1234" |
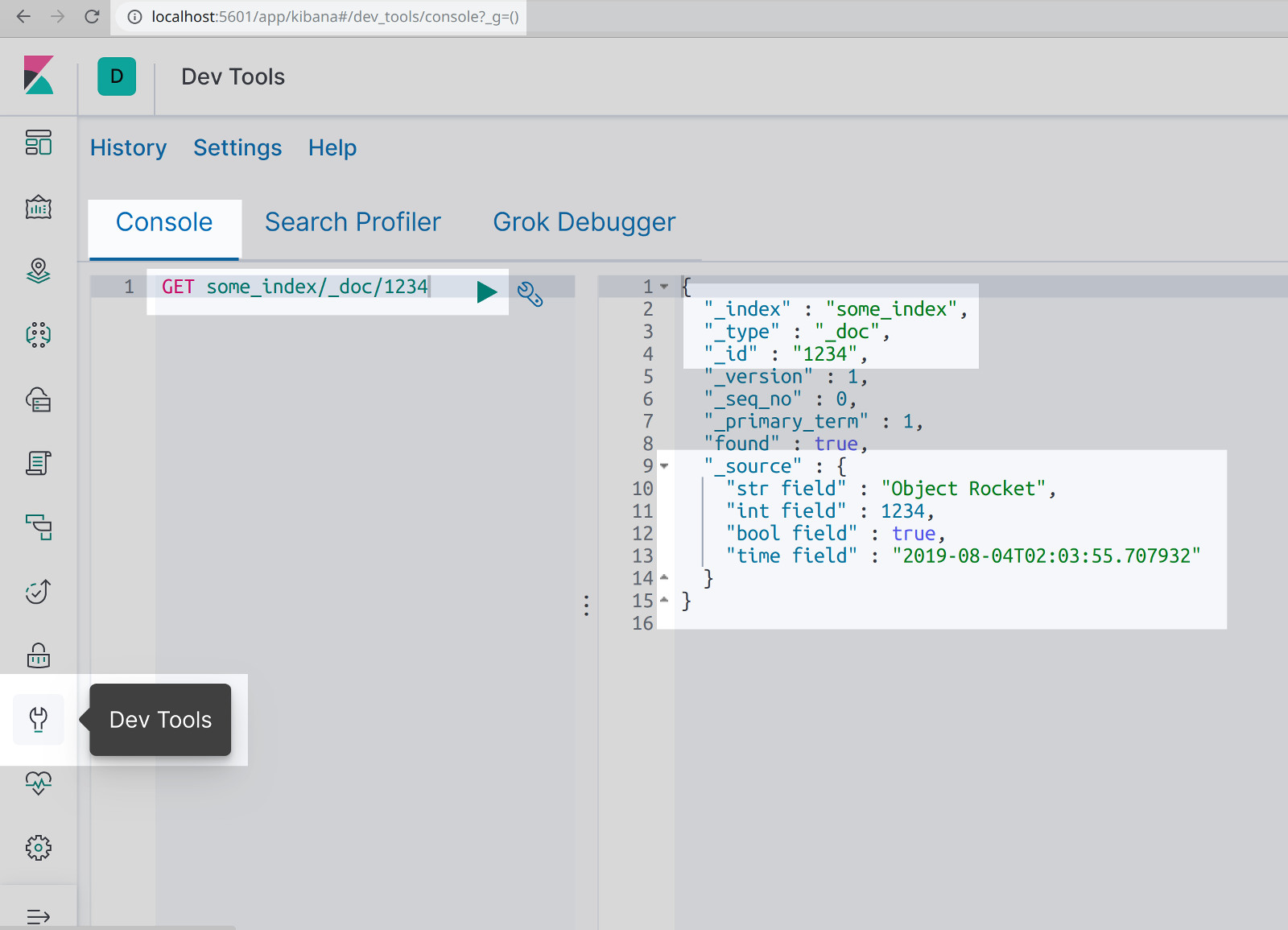
Check with Kibana if the API response was successful
From your server, go to the
5601.Next, select
Dev Tools.Then in Kibana, make a
GETHTTP request.
You can also use Kibana to verify that the document was indexed in the Python script. Navigate to port 5601 on your server and click on the Dev Tools section to make the following HTTP request in Kibana:
1 | GET some_index/_doc/1234 |
Conclusion
This tutorial explained how to use Python to index an Elasticsearch document. In addition, many Elasticsearch Python index examples were given to enhance clarification. Today, you learned how to make an index call, check for errors in the response, and confirm if the method call was successful. Python and Elasticsearch make a great team. Use them regularly to facilitate your coding accuracy from this point on.
Just the Code
Here is the complete Elasticsearch Python index example.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 | #!/usr/bin/env python3 #-*- coding: utf-8 -*- # import the Elasticsearch low-level client library from elasticsearch import Elasticsearch # import the dateime lib for an index timestamp import datetime # domain name, or server's IP address, goes in the 'hosts' list client = Elasticsearch(hosts=["localhost:9200"]) # print the attributes of the Elasticsearch client print (dir(client.index)) # print the Elasticsearch client instance print (client) print ("Elasticsearch client version:", client.info()["version"], "\n") # declare the Elasticsearch index name and document _id INDEX_NAME = "some_index" DOC_ID = 1234 # the Elasticsearch index exists index_exists = client.indices.exists(index=INDEX_NAME) # check if the Elasticsearch index exists if index_exists == False: # the Elasticsearch index name does not exist print ("INDEX_NAME:", INDEX_NAME, "does not exist.") # create a document body for the new Elasticsearch document doc_body = { "str field": "Object Rocket", "int field": 1234, "bool field": True, "time field": datetime.datetime.now() } # use a try-catch block for any Elasticsearch index() exceptions try: # call the Elasticsearch client's index() method response = client.index( index = INDEX_NAME, doc_type = '_doc', id = DOC_ID, body = doc_body, request_timeout=45 ) # print the API response returned by the Elasticsearch client print ("response:", response) # evaluate the response dict object to check that the API was successful if response["_shards"]["successful"] == 1: print ("INDEX CALL WAS SUCCESS:", response["_shards"]["successful"]) else: print ("INDEX CALL FAILED") except Exception as err: print ("Elasticsearch index() ERROR:", err) |


Pilot the ObjectRocket Platform Free!
Try Fully-Managed CockroachDB, Elasticsearch, MongoDB, PostgreSQL (Beta) or Redis.
Get Started