Export Elasticsearch Documents As CSV, HTML, And JSON Files In Python Using Pandas
Introduction
One of the advantages of having a flexible database and using Python’s Pandas Series is being able to export documents in a variety of formats. Because, during a typical day, it is likely that you’ll need to do one or more of the following to export Elasticsearch Pandas: export Elasticsearch HTML, export Elasticsearch CSV files, or export Elasticsearch JSON Python documents.
When you use Pandas IO Tools Elasticsearch to export Elasticsearch files Python, you can analyze documents faster. Learn how with this tutorial that explains how to Export Elasticsearch Documents as CSV, HTML, and JSON Files in Python Using Pandas.
If you already know how to export Elasticsearch in different formats and want to skip the details of this tutorial, you can jump to Just the Code.
Pandas objects writer methods
Let’s start with getting familiar with the list of Pandas objects writer methods.
| Methods |
|---|
to_clipboard() |
to_excel() |
to_feather() |
to_gbq() |
to_hdf() |
to_html() |
to_json() |
to_msgpack() |
to_parquet() |
to_pickle() |
to_sql() |
to_stata() |
Prerequisites
- Use the package manager PIP to install Python 3 – Next, run it.
>NOTE: Python 2 is on its way out, so download Python 3 as instructed above. This way you’ll be able to take advantage of the latest Pythonic technology. The examples in this tutorial are based on Python 3.
Install Elasticsearch – Next, launch it.
Download and install Kibana – Next, make sure it is running.
- In a terminal window or Kibana’s Console UI, confirm Elasticsearch is up and running with a
GETrequest for the default port9200.
1 | curl -XGET "http://localhost:9200" |
- Get ready to test out some of the examples in this tutorial. Go ahead and create an index that contains data as a
sourceand a few documents. The Python Elasticsearch client is the server where you’ll want to make your Search API calls to.
Install Pandas and Elasticsearch packages with PIP
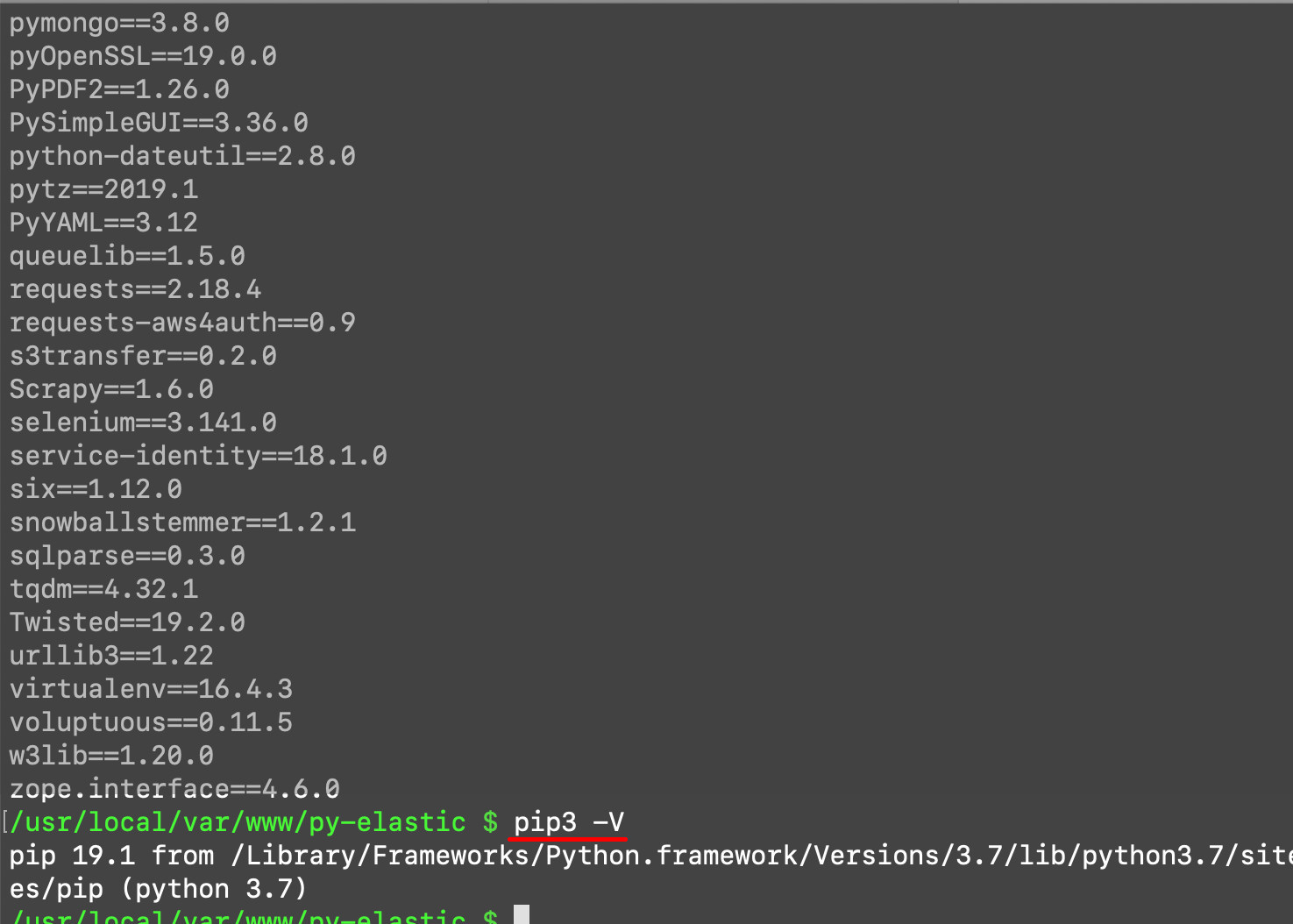
It’s important to install the packages you need with
pip3, not the oldpip. You can check the version you installed easily with the commandpip3 -V.Now check the installed packages with the command
pip3 freeze.
The Python 3 pip3 package manager
The newest distros of macOS, Linux, and Windows already have Python 3’s PIP. That’s convenient.
Use the
aptrepository to install Python 3’s PIP on your distro of Linux, Ubunto-based.
1 | sudo apt install python3-pip |
Use the command
yumon CentOS and other distros of Linux, RPM-based.This example how, on a Python 3.6 version, PIP3 would be installed using
yum.
1 2 3 4 | sudo yum install python36 sudo yum install python36-devel sudo yum install python36-setuptools sudo easy_install-3.6 pip |
Install low-level client library Elasticsearch
- To get data from Search API requests, use
pip3to install the low-level client library ofElasticsearch.
1 | pip3 install elasticsearch |
Install Python 3 Pandas library
- Use
pip3to installPandas.
1 | pip3 install pandas |
Install Python 3 NumPy library
- Use
pip3to installNumPy.
>NOTE: Pandas comes with dependencies of NumPy. Because of this, the NumPy installation is optional. However, since as a separate application, NumPy’s functions and modules are independent of Pandas, they could be a nice addition for you. Therefore, it’s recommended to install NumPy anyway.
1 | pip3 install numpy |
Use a Python script to import additional modules and Elasticsearch
- First, import the
csvandjsonPython packages.
1 | import csv, json |
Import Pandas and Numpy Libraries
Use the alias
npfor NumPy and import it.Import Pandas next.
1 2 | import numpy as np import pandas |
Import the Python Elasticsearch class
- You’ll need to create API requests. To get ready to do that, in Python, import the Elasticsearch library’s
Elasticsearchclass.
1 | from elasticsearch import Elasticsearch |
- Import the Python JSON built-in library just in case you need to do a Python dictionary JSON-string conversion.
1 | import json |
Create an Elasticsearch class client instance
At the beginning of the script, create a new Elasticsearch instance.
Next, make a Search API request to get data
Pass to the parameter
bodya dictionary object ({}) that’s empty if you all of the index’s documents in the returned results.
1 2 3 4 5 | # create a client instance of the library elastic_client = Elasticsearch() # make an API call to the Elasticsearch cluster to get documents result = elastic_client.search(index='some_index', body={}, size=99) |
>NOTE: There’s a return limit of 10 documents in the Elasticsearch cluster unless in the call that you pass to the parameter size is a specific integer. In other words, if you want more than 10 documents returned, set the integer to the number of documents you want to be returned. Query up to 100, however, keep in mind, the higher the integer, the longer it will take the documents to return. Consider testing out your queries, then setting a higher integer after you’re satisfied with the results that you’re getting.
Access the nested Elasticsearch data after iteration
- You’ve got the API call results in the dictionary
result["hits"]["hits"]. All you need to do now is iterate the API call, access, and store the list by declaring a variable.
1 | elastic_docs = result["hits"]["hits"] |
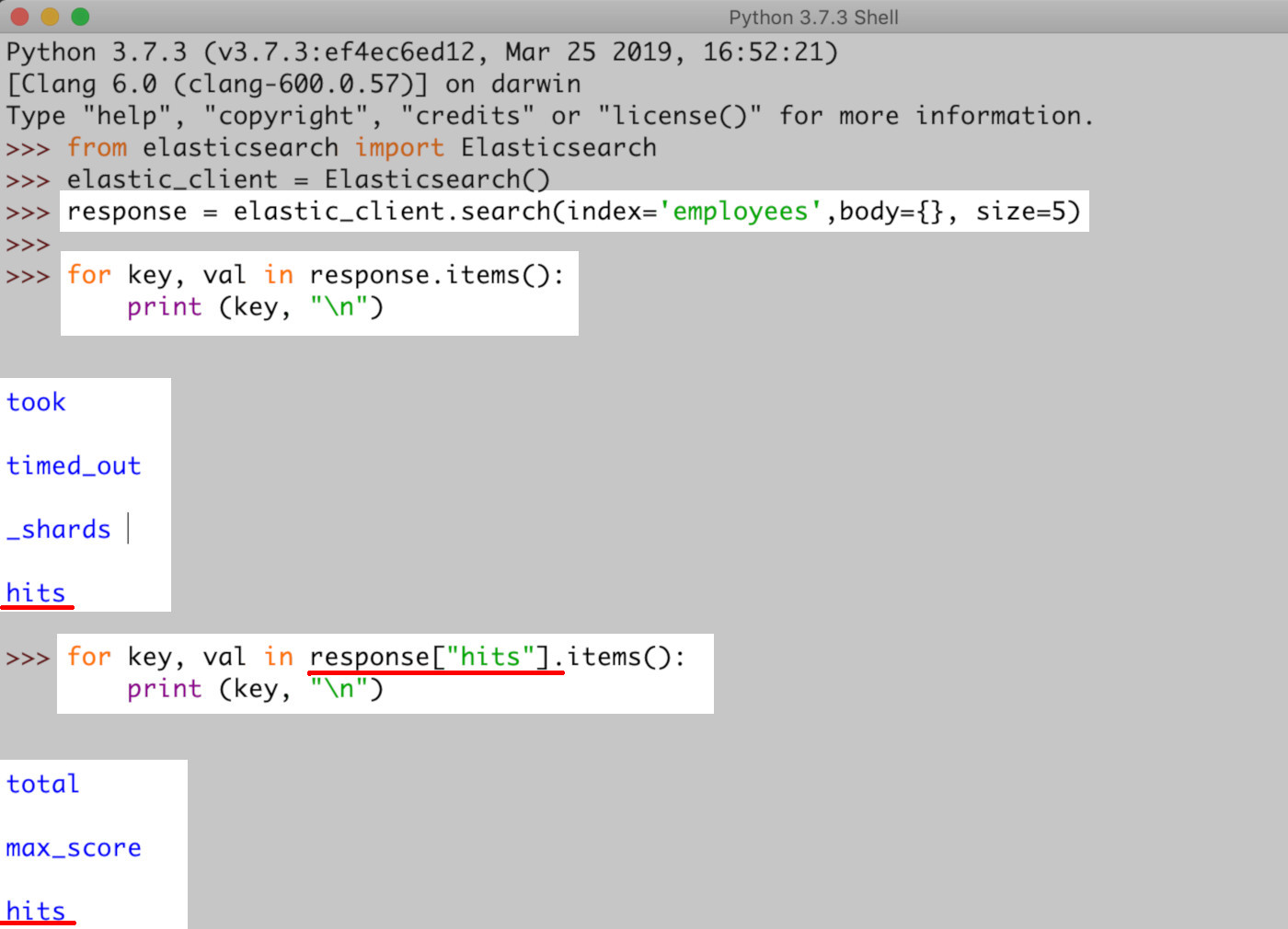
>NOTE: The "_source" key of the Python dictionary for each document (in the result["hits"]["hits"] results list) contains data that is raw and ready to export.
Convert the dictionary of a document into a pandas.core.series.Series object
Here’s where you get the formatting flexibility to export documents into different formats.
First, iterate the Elasticsearch document list.
Next, convert document dictionaries to a
pandas.core.series.Seriesobject.Make a Pandas
DataFrameobject that’s multi-dimensional.
>NOTE: At the beginning of this tutorial, we mentioned a few Pandas object writer methods. The method to_pickle() enables you to bypass an API call and locally save the data.
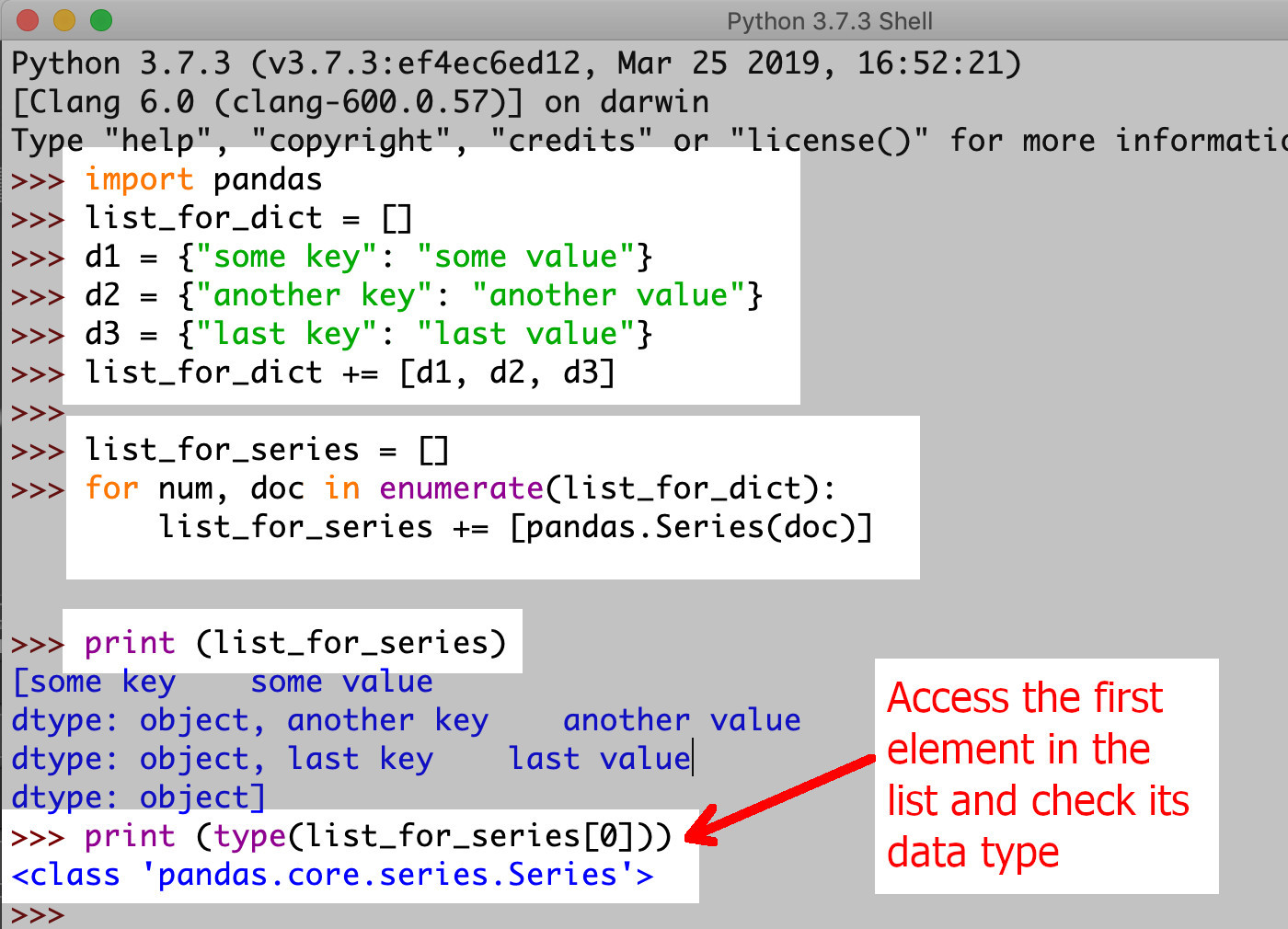
Use the dictionaries list to make a Pandas Series object
- The example below shows a basic dictionaries list and the creation of the Pandas
Seriesobject.
1 2 3 4 5 6 7 8 9 10 | list_for_dict = [] d1 = {"some key": "some value"} d2 = {"another key": "another value"} d3 = {"last key": "last value"} list_for_dict += [d1, d2, d3] # create an empty list list_for_series = [] for num, doc in enumerate(list_for_dict): list_for_series += [pandas.Series(doc)] |
>NOTE: Each Elasticsearch document has a unique index value assigned in it’s "_source" field and metadata. Because of that, it’s unnecessary for each document to have a separate Series object .
Make a DataFrame object to store objects
- The Pandas
DataFrameobject is a container that holds and organizes many types of objects including NumPy object arrays, and Python dictionaries, additional Pandas objects. Create an emptyDataFrameobject to store your Elasticsearch documents.
1 2 | # create an empty Pandas DataFrame object for Elasticsearch docs docs = pandas.DataFrame() |
Use enumerate() to iterate over the Elasticsearch documents list
- Iterate the
elastic_docslist object, the one you made from theresult["hits"]["hits"]results list. To do this, tryenumerate()since that function is built-in and more speedy than the Pythonforloop.
1 2 3 4 5 6 7 | # iterate each Elasticsearch doc in list for num, doc in enumerate(elastic_docs): # get _source data dict from document source_data = doc["_source"] # get _id from document _id = doc["_id"] |
Make new Pandas Series objects
Use the
_sourcedata dictionary object from the Elasticsearch document to make oneSeriesobject.Now it’s time to make Pandas Series objects from iterations.
Append the
Seriesdocument to theDataFrameobject.
1 2 3 4 5 | # create a Series object from doc dict object doc_data = pandas.Series(source_data, name = _id) # append the Series object to the DataFrame object docs = docs.append(doc_data) |
Use Pandas to export Elasticsearch documents to various file formats
- The
DataFrameobject and theSeriesobject contain built-in file format exporting methods. You can export the file to the directory from where you called the Python script or you can specifically identify to which directory you want the file exported.
Export to a JSON file
- Export the stored
DataFrameobject’s Elasticsearch documents as a JSON file wiht theto_json()method.
1 2 | # export the Elasticsearch documents as a JSON file docs.to_json("objectrocket.json") |
>NOTE: Skip passing arguments if you want a data string returned as opposed to an exported JSON file.
1 2 3 | # have Pandas return a JSON string of the documents json_export = docs.to_json() # return JSON data print ("\nJSON data:", json_export) |
Export to a CSV file
- Elasticsearch documents can also be exported to a CSV file with the
to_csv()method. That’s how easy it is to Elasticsearch CSV Python.
1 2 | # export Elasticsearch documents to a CSV file docs.to_csv("objectrocket.csv") |
>NOTE: Delimit the CSV data with the parameter sep like this: (sep=', ').
1 2 3 | # export Elasticsearch documents to CSV csv_export = docs.to_csv(sep=",") # CSV delimited by commas print ("\nCSV data:", csv_export) |
Export as a table in HTML
- The Python library that is built-in is
io. Use it to make tables out of the data in Elasticsearch.
1 2 3 4 5 6 7 8 9 10 11 12 | # create IO HTML string import io html_str = io.StringIO() # export as HTML docs.to_html( buf=html_str, classes='table table-striped' ) # print out the HTML table print (html_str.getvalue()) |
>NOTE: It’s nice to know that saving HTML files, and the export data calls for CSV, and JSON files works the same way.
1 2 | # save the Elasticsearch documents as an HTML table docs.to_html("objectrocket.html") |
Conclusion
This tutorial explained how to use Pandas IO Tools Elasticsearch to export Elasticsearch files Python and export Elasticsearch Pandas. You learned how to export Elasticsearch JSON documents, export Elasticsearch CSV files, and export Elasticsearch HTML. This lesson also covered how to iterate quickly with the enumerate() method. You discovered how to convert an Elasticsearch document’s dictionary into a pandas.core.series.Series object.
In addition, the steps to create a DataFrame object to store exported documents was illustrated. Apply the tips and examples as a refresher on how to export Elasticsearch documents as CSV, HTML, and JSON files in Python using Pandas.
Just the Code
Here’s the entire script for exporting Elasticsearch CSV Python, Elasticsearch JSON Python, plus exporting to HTML formats.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 | #!/usr/bin/env python3 #-*- coding: utf-8 -*- import sys, time, io start_time = time.time() if sys.version[0] != "3": print ("\nThis script requires Python 3") print ("Please run the script using the 'python3' command.\n") quit() try: # import the Elasticsearch low-level client library from elasticsearch import Elasticsearch # import Pandas, JSON, and the NumPy library import pandas, json import numpy as np except ImportError as error: print ("\nImportError:", error) print ("Please use 'pip3' to install the necessary packages.") quit() # create a client instance of the library print ("\ncreating client instance of Elasticsearch") elastic_client = Elasticsearch() """ MAKE API CALL TO CLUSTER AND CONVERT THE RESPONSE OBJECT TO A LIST OF ELASTICSEARCH DOCUMENTS """ # total num of Elasticsearch documents to get with API call total_docs = 20 print ("\nmaking API call to Elasticsearch for", total_docs, "documents.") response = elastic_client.search( index='employees', body={}, size=total_docs ) # grab list of docs from nested dictionary response print ("putting documents in a list") elastic_docs = response["hits"]["hits"] """ GET ALL OF THE ELASTICSEARCH INDEX'S FIELDS FROM _SOURCE """ # create an empty Pandas DataFrame object for docs docs = pandas.DataFrame() # iterate each Elasticsearch doc in list print ("\ncreating objects from Elasticsearch data.") for num, doc in enumerate(elastic_docs): # get _source data dict from document source_data = doc["_source"] # get _id from document _id = doc["_id"] # create a Series object from doc dict object doc_data = pandas.Series(source_data, name = _id) # append the Series object to the DataFrame object docs = docs.append(doc_data) """ EXPORT THE ELASTICSEARCH DOCUMENTS PUT INTO PANDAS OBJECTS """ print ("\nexporting Pandas objects to different file types.") # export the Elasticsearch documents as a JSON file docs.to_json("objectrocket.json") # have Pandas return a JSON string of the documents json_export = docs.to_json() # return JSON data print ("\nJSON data:", json_export) # export Elasticsearch documents to a CSV file docs.to_csv("objectrocket.csv", ",") # CSV delimited by commas # export Elasticsearch documents to CSV csv_export = docs.to_csv(sep=",") # CSV delimited by commas print ("\nCSV data:", csv_export) # create IO HTML string import io html_str = io.StringIO() # export as HTML docs.to_html( buf=html_str, classes='table table-striped' ) # print out the HTML table print (html_str.getvalue()) # save the Elasticsearch documents as an HTML table docs.to_html("objectrocket.html") print ("\n\ntime elapsed:", time.time()-start_time) |


Pilot the ObjectRocket Platform Free!
Try Fully-Managed CockroachDB, Elasticsearch, MongoDB, PostgreSQL (Beta) or Redis.
Get Started