How to Create a Web Scraper with Mongoose, NodeJS, Axios, and Cheerio - Part 4
Introduction
In this fourth part of the tutorial on how to build a webscraper from scratch we will concentrate on creating all the routes that our app will need. At this point we only have two routes, a homepage that serves our primary html page, and a route that scrapes for a term entered. We’ll be adding the following routes:
- A route that retrieves all the idioms in the database
- A route for retrieving idioms already in the database that have an string entered by the user
- A route delete all the idioms in the database
Retrieve all idioms in the database
At this point we’ve seen all the technologies that we’re using and we just need to add the routes that will add functionality to our app. This route will retrieve all the idioms that exist in the database. It will add functionality to our app and also verify that our database is functioning.
1 2 3 4 5 6 7 8 9 10 11 12 13 | // Route for retrieving all idioms app.get("/idioms", function(req, res) { // Find all Idioms Idiom.find({}) .then(function(savedIdioms) { // If all Idioms are successfully found, send them back to the client res.json(savedIdioms); }) .catch(function(err) { // If an error occurs, send the error back to the client res.json(err); }); }); |
You’ll notice this route has the same format as our home route. It is a get route specified by app.get() and the url is to http://localhost:3000/idioms. We again use the Idiom model we’ve imported and utilize the .find() method on it with an empty object inside to specify that we’d want all idioms in the database. The then function will take the idioms and return them in json format.
To check if this works we run our app and hit the “Get All Saved Idioms” button:


Now we’ve verified that our database is working correctly because we’ve scraped idioms, put them in the database, and now retrieved them from the database.
Route to retrieve idioms by string
We want to add some more functionality to our scraper. We want our users to be able to search for idioms that have already been scraped by just searching our database for a term. We’re already familiar with everything so let’s again show the code:
1 2 3 4 5 6 7 8 9 10 | // Route for retrieving idioms that have an entered string app.get("/idioms/search/:searchTerm", function(req, res) { Idiom.find({ "idiom": { "$regex": req.params.searchTerm, "$options": "i" } }) .then(function(foundIdioms) { res.json(foundIdioms); }) .catch(function(err) { res.json(err); }); }); |
The /:searchTerm part in the route allows it to be a variable so that route could be called with any of the following and still hit this route:
http://localhost:3000/idioms/search/lovehttp://localhost:3000/idioms/search/laughhttp://localhost:3000/idioms/search/free
Inside we again use the Idiom model and use the .find() function but this time we pass in the search term which is in the request variable req as req.params.searchTerm and we pass the option i to make it case insensitive. Then we return the results as JSON.
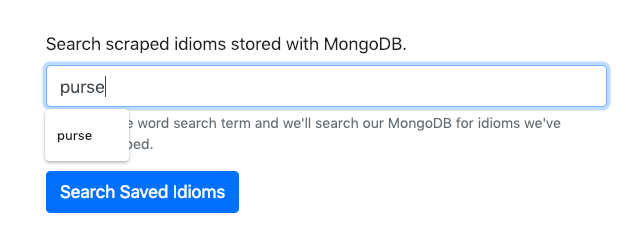
You can test this on the front end with your app typing in search term and then hitting the “Search Saved Idioms” button.

Route to delete all idioms in the database
This next route will delete all idioms in the collection. It’s not much different from the other routes as you’ll see:
1 2 3 4 5 6 7 8 9 10 11 | // Route to drop all the idioms in the database app.get("/idioms/drop", function(req, res) { Idiom.deleteMany({}) .then(function(res) { res.json(res) }) .catch(function(err) { res.json(err) }) }); |
This route we added mainly for development purposes but we won’t make it available to general users so we didn’t create a front-end for it.
Conclusion of Part 4
In this fourth part of the tutorial we connected created more api routes that our front end could access that added a lot of functionality to our application with very few lines of code. There’s lots more routes and functionality you can create with the skills you have now. These api routes are the basis for most web applications out there and we encourage you to experiment with them and see what you can do.
In Part 5 of this tutorial we’ll discuss the front end index.js which we glossed over. You have already seen the code but we never really described what it did or how it did it. It’s the last piece of the puzzle and combines back-end and front-end functionality.

Pilot the ObjectRocket Platform Free!
Try Fully-Managed CockroachDB, Elasticsearch, MongoDB, PostgreSQL (Beta) or Redis.
Get Started