Encoding Data in a Database
Introduction
If you’d like to conserve server space and keep your data secure, you may want to consider encoding the data in your database. Using encoding and compression methods can help you safeguard data and save space on a server by streamlining redundant data. In this article, we’ll provide an overview of some common encoding and compression methods and explain how they work.
Data Compression
Let’s start our discussion by taking a closer look at the process of data compression. When data is compressed, what’s really happening is that the bytes are being rearranged, using a particular algorithm, in order to reduce the size that the data takes up on the server. There are two different types of data compression: Lossless and Lossy.
Lossless Compression of Data
Data compressed using a “lossless” method can be reconstructed seamlessly without any data loss.
One of the most common examples of lossless data compression is the ZIP file archive, which includes the “tarball” (e.g. tar.xz) compression standards for UNIX systems. Other well-known forms of lossless data compression include the FLAC and ALAC (Apple Lossless Audio Codec) audio codecs and PNG image files.
Lossy Compression of Data
As you might have already guessed, “lossy” compression comes with a certain degree of data loss. Any data that gets archived or compressed using a lossy standard will lose some of its data integrity; therefore, it cannot be completely restored to its original state.
Unlike the FLAC audio codec, MP3 (MPEG Audio Layer III) is a lossy form of audio compression. Another lossy format is the JPEG image format, which doesn’t provide an alpha channel to support transparency.
UTF Encoding Standards
The UTF-8 and UTF-16 encoding standards are used to convert Unicode characters into binary numerals.
UTF-8 vs UTF-16
While both of these encoding standards are used for a similar purpose, there’s an important difference between them. The UTF-16 standard represents a character with either 2 or 4 bytes of data, while UTF-8 uses only one byte.
UTF-16 is the oldest of all the UTF encoding algorithms, and it’s natively supported by the Java programming language.
Unicode
The ASCII (American Standard Code for Information Interchange) encoding schema has a 7-bit range, and it encompasses the Roman alphabet, Arabic numerals, and a few other special characters (like $ and &). This format is limited to just 128 characters.
Because of these limitations, ASCII is not feasible for storing and rendering special characters, foreign alphabets, emojis or any other kind of data outside of the ASCII character range– that’s where UTF-8 and Unicode comes into play.
The U+ notation represents a Unicode “code point”, which is used by ASCII encoding to signify a Unicode character.
Unicode in the Python Scripting Language
Python has a built-in library called struct that allows you to generate a C struct object represented as a bytes type string. This object is generated by passing a one-character string as the first parameter to the pack() method:
1 2 3 | import struct struct.pack('f', 128) # returns bytes value: b'x00x00x00C' |
Return the Unicode String for a Character in Python
Let’s look at a Python example that uses bit manipulation to get the Unicode string for the Chinese 好 character using a base-16 encoding value:
1 2 | print (ord('好')) # returns int value of 22909 print (chr(int('22909', 16))) # returns 'U00022909' |
NOTE: The default for the chr() function in Python is base-10 encoding if no second value is passed to specify the encoding system.
Base64 Encoding
The Base64 encoding algorithm, also known as ASCII encoding, converts binary data into ASCII strings in order to keep data more secure. Base64 converts 3-byte data into 4 bytes– this means that data will take up over 30% more space after conversion.
Base64 encoding isn’t the ideal choice for security, as it can easily be decoded; instead, it serves as an effective way to make non-HTTP-compatible data readable. Put simply, it’s a convenient way to store and read Unicode characters. It’s also a convenient way to store other file types that may contain Unicode characters, such as audio files or images, in a database.
NOTE: There is an older encoding algorithm called Base32, but this encoding scheme uses about 20% more disk space than Base64 and is not recommended.
Base64 Encoding in Python
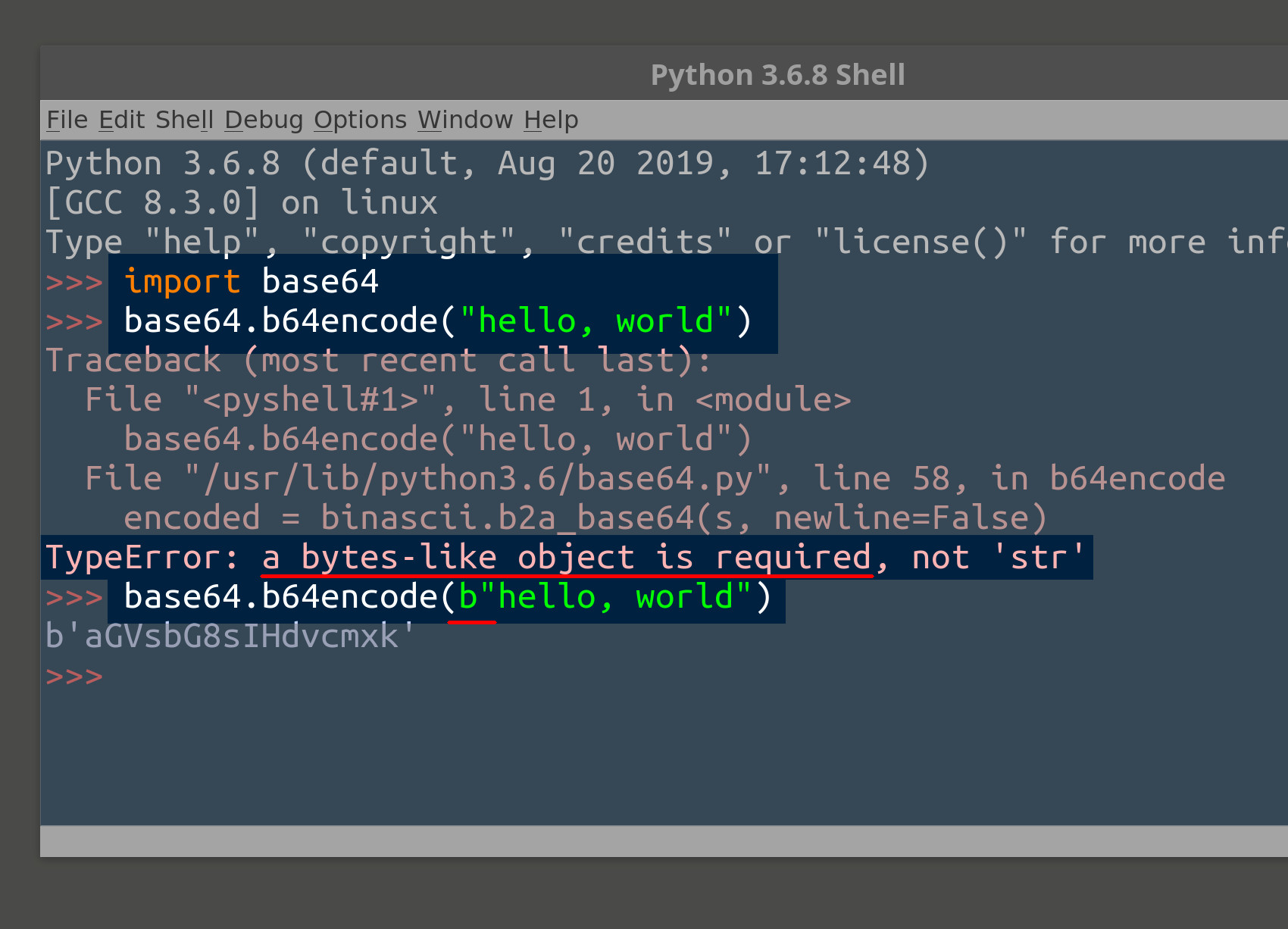
Python 2.7 and Python 3 both come with a built-in Base64 library. Let’s look at an example that shows how you can encode a bytes string using the Base64 encoding algorithm:
1 2 | import base64 print (base64.b64encode(b"hello, world")) |
NOTE: If you’re using Python 2.7, you’ll need to import the unicode_literals library so that Python will recognize a bytes object instead of interpreting it as a string.
Encoding and Unicode Support in Python 2.7
Creating byte strings can be a little tricky in Python 2. One way to get around the issue of Unicode characters in Python 2 is to enclose the string value in ''. An example of this method is shown below:
1 2 | # using the unicode function in Python 2.7 print unicode('好', 'utf8') |
Base64 Encoding in JavaScript
JavaScript has two built-in functions called atob() and btoa() that allow you to encode and decode Base64 strings. In the following example, we pass a string to the window.btoa() method call, and then the encoded string is printed to the console:
1 |
Base64 can be particularly helpful if your application or web page renders drawings or videos; these situations often occur when using something like the p5.js JavaScript library.
Conclusion
It’s clear that encoding the data in your database offers important benefits: Not only does it keep your data secure, but it also can save space on your server. In this article, we looked at a variety of compression and encoding formats. With this overview to help guide you, you’ll be able to make a more informed decision about the right encoding or compression method to use in your own database environment.


Pilot the ObjectRocket Platform Free!
Try Fully-Managed CockroachDB, Elasticsearch, MongoDB, PostgreSQL (Beta) or Redis.
Get Started