SQL Select Count
Introduction
In this article, we will be discussing the COUNT function in SQL. Before getting in the details, let’s just explain briefly what exactly are functions in an SQL database.
Functions
Functions in SQL are used to perform certain operations on the result returned from the SELECT statement. Functions are performed on some attribute values. They take as argument a column and return a single answer. Functions are always used with the SELECT statement. The general syntax is:
1 2 3 | SELECT FUNCTION(COLUMN_NAME) FROM TABLE1, TABLE2 [WHERE condition] |
SQL database supports many functions and their functionalities are mostly interpretable by their name. For example, MIN () and MAX () functions are used to find the minimum and maximum form the values in the column specified. AVG () and SUM () are used to return the average and sum of the column values that are passed as an argument in the function.
SQL COUNT () function
In the real world, when we use the word ‘count’ with something, we mean the number of units of that particular thing. For example, ‘word count’ or ‘character count’ means the number of words and the number of characters respectively. When we ask someone to count, we specify them something and what they need to do is to tell us the number of units of that something.
In SQL, COUNT () works in pretty much the same way. COUNT () is used to count the results from a SELECT FROM WHERE query. COUNT () returns us the number of rows returned by the query. The general syntax is:
1 2 3 | SELECT COUNT (column_name | *) FROM tableA [, tableB ] [WHERE condition ] |
The asterisk symbol can be given as an argument to the COUNT function. It works in the same way as we can specify * in a SELECT statement but this time it returns the count of the records returned by the query.
If we specify a column name, the COUNT function will return the number of ‘non- null’ values in the column specified.
Now, this syntax is identical to the one we use in the English language, so it is very easy to understand. We are giving SQL something to count and we are specifying what SQL needs to count in the argument of the COUNT function.
Consider the following example:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 | CREATE TABLE developers ( d_id INT PRIMARY KEY, d_name TEXT NOT NULL, d_age INT NOT NULL, d_address CHAR(50), d_salary INT NOT NULL ); INSERT INTO developers ( d_id, d_name, d_age, d_address, d_salary ) VALUES (0,'JOHN CONNER',19,'23 BOULEVARD ST.',20000), (1,'ADAM SMITH',21,'28 BOULEVARD ST.',25000), (2,'BLAKE JONES',23,'22 BOULEVARD ST.',30000), (3,'BRIDGETTE JOHNSON',18,'21 BOULEVARD ST.',40000), (4,'CMAILIA BLACK',20,'27 BOULEVARD ST.',35000), (5,'AMY WINEHOUSE',20,'23 BOULEVARD ST.',20600), (6,'CHRIS JONES',23,'01 BOULEVARD ST.',37000); CREATE TABLE pragrams ( p_id INT PRIMARY KEY, p_date TEXT NOT NULL, d_id INT NOT NULL, p_value INT NOT NULL, FOREIGN KEY f_key (d_id) referances developers(d_id) ); INSERT INTO programs ( p_id, p_date, d_id, p_value ) VALUES (0,'09-01-2018',5, 3000), (1,'11-02-2019',1, 2110), (2,'20-03-2015',0, 4500), (3,'25-03-2019',6, 1010), (4,'26-12-2018',0, 350); |
When the above code is executed, we get the following tables:
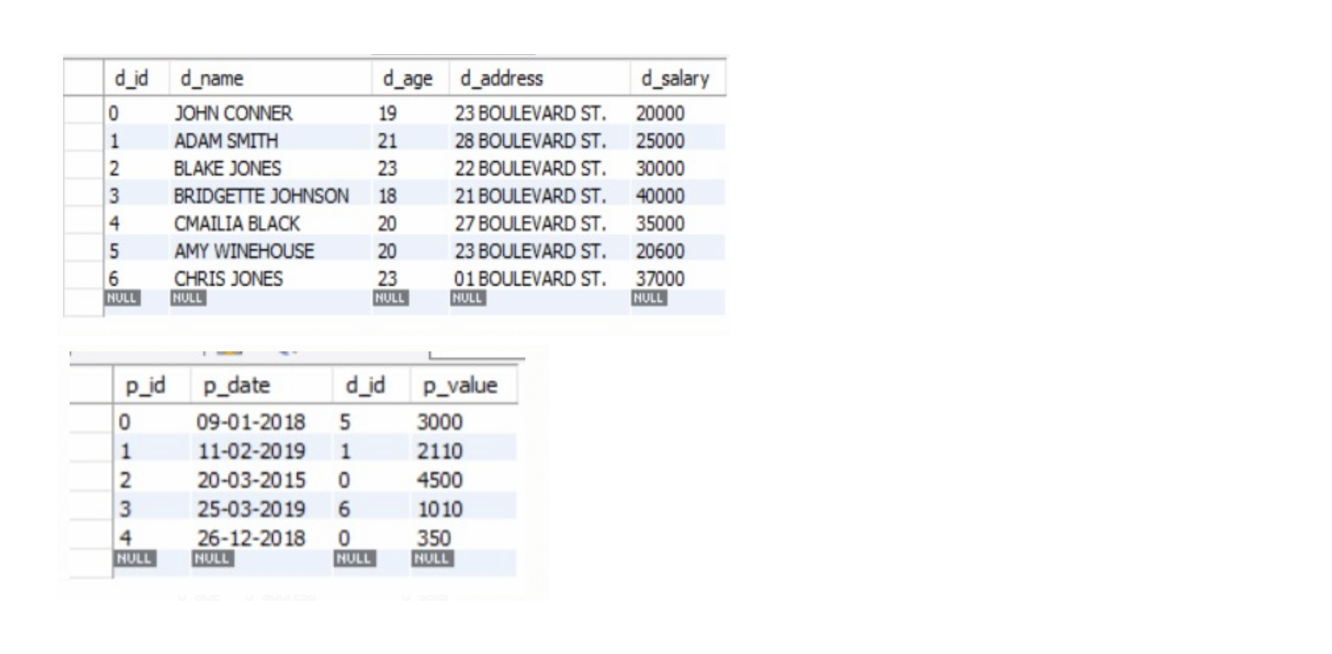
Now if we want to know how many developers are on the payroll of the company:
1 2 | SELECT COUNT(*) FROM developers; |
The ‘SELECT * FROM developers’ statement would have returned the 7 records in the ‘developers’ table. So our count functions return 7. We can also specify a condition using the WHERE clause while using the COUNT function is a SELECT statement. For example, if we want to get the number of developers who have a salary of more than 30000, we can use the following query.
1 2 3 | SELECT COUNT(*) FROM developers WHERE d_salary > 30000; |
This would return the number of developers with the condition specified.
The DISTINCT clause can be used with the column given as an argument in COUNT to get the number of unrepeated entries in that column i.e. the number of distinct entries. For example, we want to know how many developers have worked on some program, we can do this by:
1 2 | SELECT COUNT (DISTINCT d_id) FROM programs; |
We can also combine the COUNT function with AS clause, GROUP BY or any other clause that can be used with SELECT statement
Conclusion
COUNT () function is used to count the number of values. It is only used with SELECT FROM statement and it can be combined with different clauses to increase the functionality. It takes as argument some values and counts the number of values.

Pilot the ObjectRocket Platform Free!
Try Fully-Managed CockroachDB, Elasticsearch, MongoDB, PostgreSQL (Beta) or Redis.
Get Started