SQL GROUP BY vs ORDER BY - The Difference Explained
Introduction
In this article, we will be discussing the difference between the “group by” clause and the “order by” clause of the PostgreSQL database. Before getting in the details, let’s just explain briefly what exactly are clauses in the PostgreSQL database.
Clauses
Clauses in the PostgreSQL are keywords that have definite meaning (similar to their English language counterpart) and purpose. The purpose is self-explanatory by the name of the clause. For example, the WHERE clause is used to query a specific condition. LIKE clause is used for string text comparison on a specific pattern. EXCEPT clause is used to limit the search results of a query on a specific condition. etc.
Some clauses in PostgreSQL can only be used with another clause and they usually enhance the functionality of the clause they are being used with. For example, the HAVING clause can only be used with a group by clause and it restricts the results of the group by clause on a condition. The FROM clause is mandatory with the SELECT statement to specify from which table the data needs to be selected.
PostgreSQL GROUP BY clause
The GROUP BY clause in the PostgreSQL database is used with the SELECT statement and it, as the name suggests, groups the results of the SELECT statement by an attribute value. This functionality is very useful if we want to apply some aggregate functions on the data such as COUNT (), MAX (), MIN (), AVERAGE (), etc.
We can also say that GROUP BY statement removes duplicates from the results and only show a unique categorical representation of the databases on a specific attribute. This reduces the redundancy in our search results. The general syntax is:
1 2 3 4 | SELECT columnA [, columnB ] FROM tableA [, tableB ] [WHERE condition] GROUP BY columnA [, columnB]; |
A query result can be grouped by more than one column. In that case, the data is grouped by the unique combination of the columns. But we have to keep the fact in mind that a data can only be grouped by a column or combination of columns if the column[s] are specified with the SELECT statement.
Consider the following example of a company’s developer’s database where it has stored a list of its hired developers and the programs written by those developers:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 | CREATE TABLE developers ( D_id INT PRIMARY KEY, D_name TEXT NOT NULL, D_age INT NOT NULL, D_address CHAR(50), D_salary INT NOT NULL ); INSERT INTO developers ( D_id, D_name, D_age, D_address, D_salary ) VALUES (0, 'JOHN CONNER', 19, '23 BOULEVARD ST.', 20000), (1, 'ADAM SMITH', 21, '28 BOULEVARD ST.', 25000), (2, 'BLAKE JONES', 23, '22 BOULEVARD ST.', 30000), (3, 'BRIDGETTE JOHNSON', 18, '21 BOULEVARD ST.', 40000), (4, 'CMAILIA BLACK', 20, '27 BOULEVARD ST.', 35000), (5, 'AMY WINEHOUSE', 20, '23 BOULEVARD ST.', 20600), (6, 'CHRIS JONES', 23, '01 BOULEVARD ST.', 37000); CREATE TABLE programs ( P_id INT PRIMARY KEY, P_date TEXT NOT NULL, D_id INT, P_value INT NOT NULL, FOREIGN KEY f_key (D_id) REFERENCES developers(D_id) ); INSERT INTO programs ( P_id, P_date, D_id, P_value ) VALUES (0, '09-01-2018', 5, 3000), (1, '11-02-2019', 1, 2110), (2, '20-03-2015', 0, 4500), (3, '25-03-2019', 6, 1010), (4, '26-12-2018', 0, 350), (5, '10-01-2018', 2, 3000), (6, '10-02-2019', 2, 2110), (7, '27-03-2015', 3, 4500), (8, '20-03-2019', 6, 1010), (9, '29-12-2018', 4, 350); |
When the above code is executed, we get the following tables:
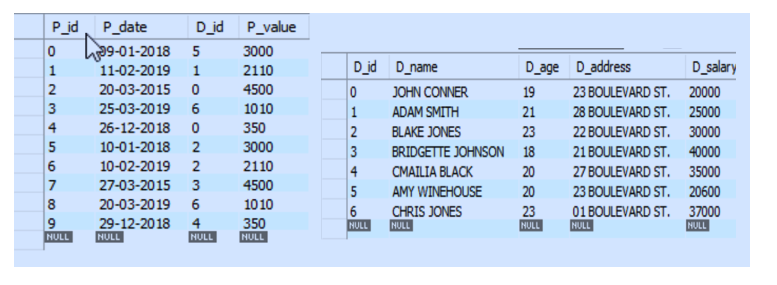
Now if we want to see how much revenue each developer has generated, i.e. the value of his programs, we can do that by:
1 2 3 | SELECT D_id, D_name , SUM(P_value) AS revenueGenerated FROM developers JOIN programs USING (D_id) GROUP BY D_id; |
The above query uses two tables and joins them on the same developer’s id and then uses the resulting table to calculate the revenue. It output to:
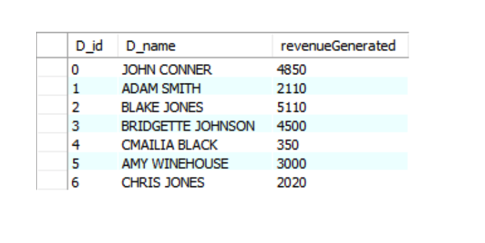
We now know what purpose does the GROUP BY clause serves in the PostgreSQL database.
PostgreSQL ORDER BY clause
The functionality of the ORDER BY clause is pretty self-explanatory from the name. The ORDER BY clause is used to output our data in some order, i.e. ascending or descending. The data is arranged so that depends on some attribute values. The ORDER BY clause is used in combination with the SELECT statement and can’t be used on its own. The general syntax of the ORDER BY clause is:
1 2 3 4 | SELECT columnA [, columnB ] FROM tableA [, tableB ] [WHERE condition] ORDER BY columnA [, columnB] [ASC OR DESC] |
We can use multiple columns in the ORDER BY clause but we have to keep in mind that the columns must be specified in the SELECT statement. The ASC or DESC describes whether you want the ORDER BY to arrange data in ascending order or descending order.
For example, in the developer’s database, we want to know how much the company is paying to each developer from the most paid to the lowest paid developer. Now the ORDER BY clause would be very handy in such a situation.
1 2 3 | SELECT D_id, D_name, D_salary FROM developers ORDER BY D_salary DESC; |
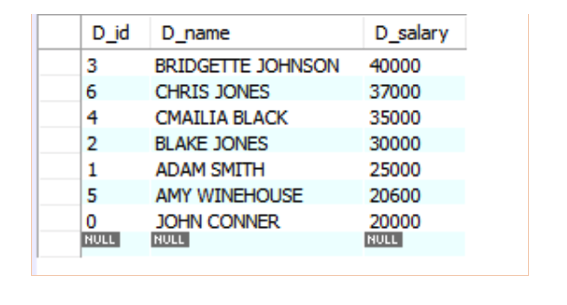
The query outputs the following result telling us that BRIDGETTE JOHNSON is the highest-paid while JOHN CONNER is the lowest-paid developer in the company. We now have a list of developer’s data in decreasing order of their salaries.
In some situations, it is handy to use both ORDER BY and GROUP BY clauses. We can use both these in the same query to serve some purpose. The basic syntax for that is:
1 2 3 4 5 | SELECT columnA [, columnB ] FROM tableA [, tableB ] [WHERE condition] GROUP BY columnA [, columnB] ORDER BY columnA [, columnB] [ASC OR DESC] |
The ORDER BY clause can be used after the GROUP BY clause. It is a syntax error if we use ORDER BY first and then GROUP BY clause.
Consider the above example we gave with GROUP BY clause where we wanted to see how much revenue is generated by each developer. The company has decided to kick out 3 developers who have generated the least revenue and want to know the revenues generated by each developer from lowest to highest. Now this can be done by:
1 2 3 4 | SELECT D_id, D_name , SUM(P_value) AS revenueGenerated FROM developers JOIN programs USING (D_id) GROUP BY D_id ORDER BY revenueGenerated; |
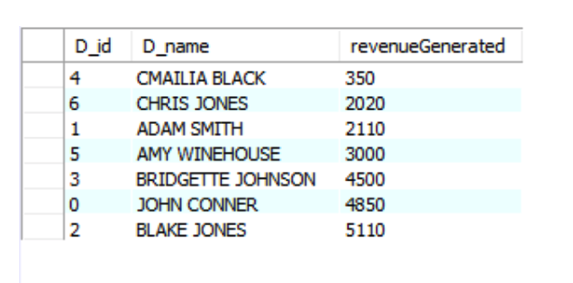
This query returned us the revenue generated by each developer in ascending order. One key point to note here is that we did not specify an order in the ORDER BY clause, but it gave us the result in ascending order. This shows us that the ORDER BY gives te results in ascending order by default.
Conclusion
ORDER BY and GROUP BY are two very useful features of the PostgreSQL database. There is no relation between them and they both serve two different purposes. But they can be combined to serve some purpose at hand or they can be used individually depending on the circumstances. But both of them can only be used with the SELECT statement.

Pilot the ObjectRocket Platform Free!
Try Fully-Managed CockroachDB, Elasticsearch, MongoDB, PostgreSQL (Beta) or Redis.
Get Started