SQL DISTINCT vs UNIQUE - What's the Difference?
Introduction
In this article, we will be discussing the difference between “unique” constraint and the “distinct” statement in PostgreSQL. It may not be obvious but we used two different terms to refer to the two because UNIQUE is a constraint while DISTINCT is a statement. Statements might be self-explanatory, but what are constraints? First, we need to look deeper into that question. Stick with us as we discuss and demo the differences between SQL DISTINCT vs UNIQUE.
Constraints
In real-life scenarios, there always has been a need for constraints on data so that we may have data that is mostly bug-free and consistent to ensure data integrity. Constraints make data accurate and reliable.
Constraints in PostgreSQL are used to limit the type of data that can be inserted in a table. So we can say that constraints define some rules which the data must follow in a table. Constraints cannot be violated so they are very much reliable.
There are many constraints in PostgreSQL, they can be applied to either a column or to a table itself. Applying a constraint at the column level lets you apply that constraint to a single column. While if you define a constraint at the table level, multiple columns don’t need to be assigned the same constraint separately.
For example, consider this code:
1 2 3 4 5 6 7 8 | CREATE TABLE sample ( myCode INT, myNAME TEXT NOT NULL, myAGE INT NOT NULL, myADDRESS CHAR (50), mySALARY REAL, FOREIGN KEY (myName, myCode) ); |
In the above code, NOT NULL is a column-level constraint which is individually applied to two attributes while FOREIGN KEY is a table-level constraint which lets us apply the constraint on two attributes at the same time. The same can also be applied column-wise.
PostgreSQL ‘Unique’ Constraint
In many real-life scenarios, we encounter situations where a certain attribute of an object cannot have repeated values. For example, the registration number of the students in a university can never have repeated values, i.e. two students cannot have the same registration number. That’s where the UNIQUE constraint comes into play. Unique constraint over an attribute would make sure that no value entered in the table has duplicate value for that attribute.
For example, when defining a student table, we may want that registration numbers can’t be repeated. So the table student is created as:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | CREATE TABLE students ( S_id INT PRIMARY KEY, S_name TEXT NOT NULL, S_age INT NOT NULL, S_address CHAR(50), S_regsitration_no INT UNIQUE ); INSERT INTO students ( S_id, S_name, S_age, S_address, S_regsitration_no ) VALUES (0, 'JOHN CONNER', 19, '23 BOULEVARD ST.', 1), (1, 'ADAM SMITH', 21, '28 BOULEVARD ST.', 2), (2, 'BLAKE JONES', 23, '22 BOULEVARD ST.', 3), (3, 'BRIDGETTE JOHNSON', 18, '21 BOULEVARD ST.', 4), (4, 'CMAILIA BLACK', 20, '27 BOULEVARD ST.', 5), (5, 'AMY WINEHOUSE', 20, '23 BOULEVARD ST.', 6), (6, 'CHRIS JONES', 23, '01 BOULEVARD ST.', 7); |
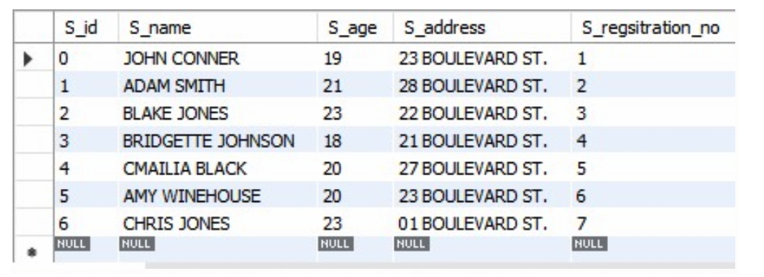
After the above code is executed, we have the following output:
Now we try to enter another record with the same registration number as some previous record:
1 2 3 4 5 6 7 8 9 10 | INSERT INTO students ( S_id, S_name, S_age, S_address, S_regsitration_no ) VALUES (8, 'JOHNATHAN CONNER', 20, 'MAIN BOULEVARD', 10), (7, 'JOHN SMITH', 21, 'XYS ST. GATE', 6), |
When the code is run, we get:
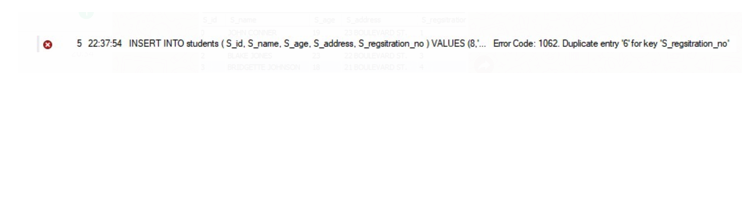
This is because of the UNIQUE constraint applied to the registration number attribute. Now you get the idea of what this constraint does.
PostgreSQL ‘Distinct’ Statement
Many times, we encounter situations where we just want unrepeated values to be returned by our query. The PostgreSQL distinct keyword is used to return unrepeated results of an attribute so only one instance of repeated values is displayed. The distinct keyword is very useful and is often used with a SELECT statement in PostgreSQL. For example, consider the above student example and let’s say that there is another attribute ‘program’ which is the degree program of the student. Now the table created will be:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | CREATE TABLE studentsNew ( S_id INT PRIMARY KEY, S_name TEXT NOT NULL, S_age INT NOT NULL, S_address CHAR (50), S_regsitration_no INT UNIQUE, S_program TEXT NOT NULL ); INSERT INTO studentsNew( S_id, S_name, S_age, S_address, S_regsitration_no, S_program ) VALUES (0, 'JOHN CONNER', 19, '23 BOULEVARD ST.', 1, ’BESE’), (1, 'ADAM SMITH', 21, '28 BOULEVARD ST.', 2, ’BEEE’), (2, 'BLAKE JONES', 23, '22 BOULEVARD ST.', 3, ’BSCS’), (3, 'BRIDGETTE JOHNSON', 18, '21 BOULEVARD ST.', 4, ’BESE’), (4, 'CMAILIA BLACK', 20, '27 BOULEVARD ST.', 5, ’BSCS’), (5, 'AMY WINEHOUSE', 20, '23 BOULEVARD ST.', 6, ’BSCS’), (6, 'CHRIS JONES', 23, '01 BOULEVARD ST.', 7, ’BESE’); |
After executing the above code, we have:
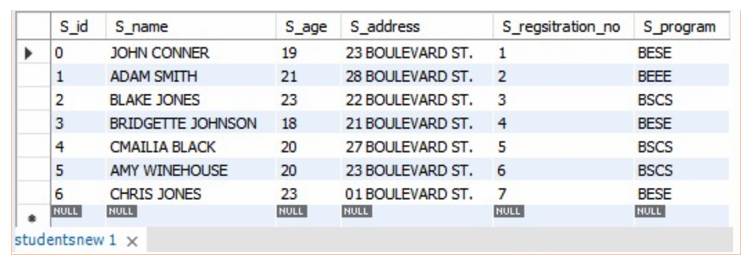
Now if we want to query how many degree programs are currently in the university, then the query would be:
1 | SELECT DISTINCT S_program FROM studentsNew; |
This would return the following output:
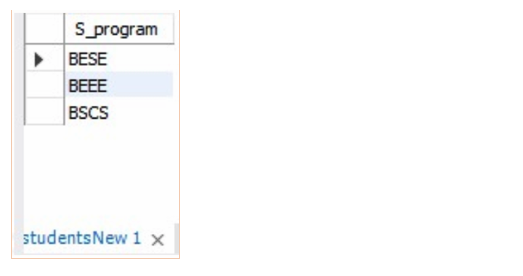
The SELECT DISTINCT statement can be used with the order by or group by clauses for further advanced usage in the same way we use these clauses with the SELECT statement. For example, if we want to count the number of students in each degree program, we would do it like:
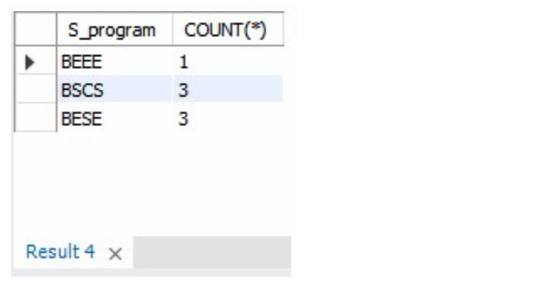
1 | SELECT DISTINCT S_program, COUNT (*) FROM studentsNew GROUP BY S_program; |
We get:
Conclusion
The main difference between unique and distinct is that UNIQUE is a constraint that is used on the input of data and ensures data integrity. While DISTINCT keyword is used when we want to query our results or in other words, output the data. Both UNIQUE and DISTINCT key words ensure the same thing, i.e. data is not repeated. One makes sure during input and other during the output.


Pilot the ObjectRocket Platform Free!
Try Fully-Managed CockroachDB, Elasticsearch, MongoDB, PostgreSQL (Beta) or Redis.
Get Started