Delete Duplicate Rows in PostgreSQL
Introduction
If you’re storing data in a PostgreSQL database, you’ll find that duplicate rows may occasionally make their way into your tables. It’s important to know how to delete these duplicates in order to keep your database clean. In this article, we’ll show you how to use the PostgreSQL DELETE USING statement and other techniques to delete duplicate rows.
Prerequisites
Before you attempt to delete duplicate rows in PostgreSQL, you’ll need to ensure that PostgreSQL server is properly installed and configured. You’ll also need to have the service running in the background. If you’re using Windows or Linux, you can download PostgreSQL here.
Create a Sample Data Set
Let’s begin by creating a small sample data set that we’ll use throughout all the examples in this tutorial.
The statement shown below will create a table named zoo:
1 2 3 4 | CREATE TABLE zoo( animal_id SERIAL PRIMARY KEY, animal VARCHAR(15) NOT NULL ); |
After we create the zoo table, we can insert records into it using the following statement:
1 2 3 4 5 6 7 8 | INSERT INTO zoo(animal) VALUES ('lion'); INSERT INTO zoo(animal) VALUES ('lion'); INSERT INTO zoo(animal) VALUES ('tiger'); INSERT INTO zoo(animal) VALUES ('tiger'); INSERT INTO zoo(animal) VALUES ('tiger'); INSERT INTO zoo(animal) VALUES ('dove'); |
Let’s query the record(s) within the zoo table and make sure they were inserted properly:
1 | SELECT * FROM zoo; |
The output of your SELECT statement should look something like this:
1 2 3 4 5 6 7 8 9 10 | animal_id | animal -----------+-------- 1 | lion 2 | lion 3 | tiger 4 | tiger 5 | tiger 6 | dove (6 ROWS) |
Deleting Duplicate Rows in PostgreSQL
Now that we’ve created our sample data set, we’ll move on to some examples. In this section, we’ll look at different techniques that can be used to delete duplicate rows in PostgreSQL.
Deleting Duplicate Rows via DELETE USING Statement
Let’s look at the following statement, which makes use of the DELETE USING statement to delete rows with duplicate values:
1 2 3 4 5 6 | DELETE FROM zoo x USING zoo y WHERE x.animal_id < y.animal_id AND x.animal = y.animal; |
In this statement, we joined the table zoo to itself, and we looked for instances where rows x and y have identical values in the animal column.
The statement should return results that look like the following:
1 2 3 4 5 6 | animal_id | animal -----------+-------- 2 | lion 5 | tiger 6 | dove (3 ROWS) |
We can see that the duplicate values having the lowest animal_id were deleted. If we wanted to keep the values with the highest animal_id, we could use the following statement:
1 2 3 4 5 6 | DELETE FROM zoo x USING zoo y WHERE x.animal_id > y.animal_id AND x.animal = y.animal; |
Notice that we changed the comparison operator in this part of the syntax: x.animal_id > y.animal_id from less than “<” to greater than “>”. This will impact which duplicate rows are deleted.
Let’s see if the above statement is successful, using another SELECT statement:
1 2 3 4 5 6 7 | testdatabase=# SELECT * FROM zoo; animal_id | animal -----------+-------- 1 | lion 3 | tiger 6 | dove (3 ROWS) |
Deleting Duplicate Rows via a Subquery
The statement shown below uses a subquery to delete duplicate rows having the lowest animal_id:
1 2 3 4 5 6 7 8 9 | DELETE FROM zoo WHERE animal_id IN (SELECT animal_id FROM (SELECT animal_id, ROW_NUMBER() OVER( PARTITION BY animal ORDER BY animal_id ) AS row_num FROM zoo ) x WHERE x.row_num > 1 ); |
We use the subquery to retrieve the duplicate rows, not including the first row within the duplicate group. The DELETE statement deletes the rows that were retrieved by the subquery.
When this statement is executed, PostgreSQL returns the phrase DELETE 3 which means that the delete operation was a success.
Let’s verify by using a SELECT query. The result of the query should look like this:
1 2 3 4 5 6 7 | testdatabase=# SELECT * FROM zoo; animal_id | animal -----------+-------- 1 | lion 3 | tiger 6 | dove (3 ROWS) |
CONCLUSION
When you’re working with a database, it’s normal to find occasional duplicate rows in your tables. The key to keeping your database clean is to make the effort to identify duplicates and delete them. In this article, we demonstrated some different techniques that can be used to delete duplicate rows in PostgreSQL. With these examples as a guide, you’ll be able to manage duplicates in your own PostgreSQL database.
Starting PostgreSQL Server
Shown below are the steps needed to start PostgreSQL server on Linux and Windows systems:
- To start PostgreSQL server on a LINUX machine, use the following command:
1 | sudo service postgresql start |
- You can verify that the service is running with this command:
1 | service postgresql status |
- The output of the command will look something like this:
1 2 3 4 5 6 7 8 9 | â— postgresql.service - PostgreSQL RDBMS Loaded: loaded (/lib/systemd/system/postgresql.service; enabled; vendor prese Active: active (exited) since Thu 2019-08-01 14:51:20 PST; 36min ago Process: 1230 ExecStart=/bin/true (code=exited, status=0/SUCCESS) Main PID: 1230 (code=exited, status=0/SUCCESS) Aug 01 14:51:20 user-UX330UAK systemd[1]: Starting PostgreSQL RDBMS... Aug 01 14:51:20 user-UX330UAK systemd[1]: Started PostgreSQL RDBMS. lines 1-8/8 (END) |
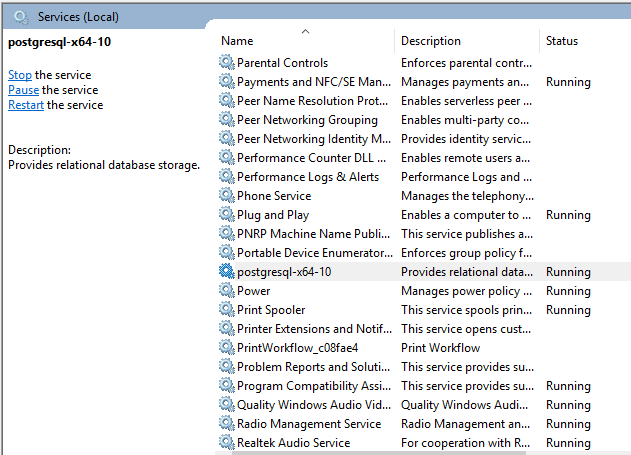
- To start, stop or restart the PostgreSQL service in a Windows environment, a different set of steps is needed:
- Open Control Panel
- Open Administrative Tools
- Open Services
- Find the PostgreSQL Server service
- Finally, stop, start or restart the service


Pilot the ObjectRocket Platform Free!
Try Fully-Managed CockroachDB, Elasticsearch, MongoDB, PostgreSQL (Beta) or Redis.
Get Started