Use Tesseract OCR to Insert MongoDB Documents (Part 1)
Introduction to using Tesseract OCR to insert MongoDB documents
Google’s Tesseract OCR (Optical Character Recognition) software allows you to analyze the text in an image in order to process it and render it as a string of characters. This article series will demonstrate how you can use Python’s pytesseract and pymongo modules to read an image and insert the data string as a MongoDB document.
This article will show you how to install the necessary packages and setup your Python project so that it will use the Tesseract OCR software to read an image’s text data.
Prerequisites to using the pytesser and pymongo modules
Make sure that you have a JPG, BMP, or PNG file, with some legible text data in it, that you can use as a test for the PyTesseract OCR code found in this article series. You can use a simple image editor like MS paint, or a more professional software suite such as GIMP or Adobe Photoshop to export or save your image file.
This MongoDB app will use a simple black and white image called objectrocket-mongo.jpg:
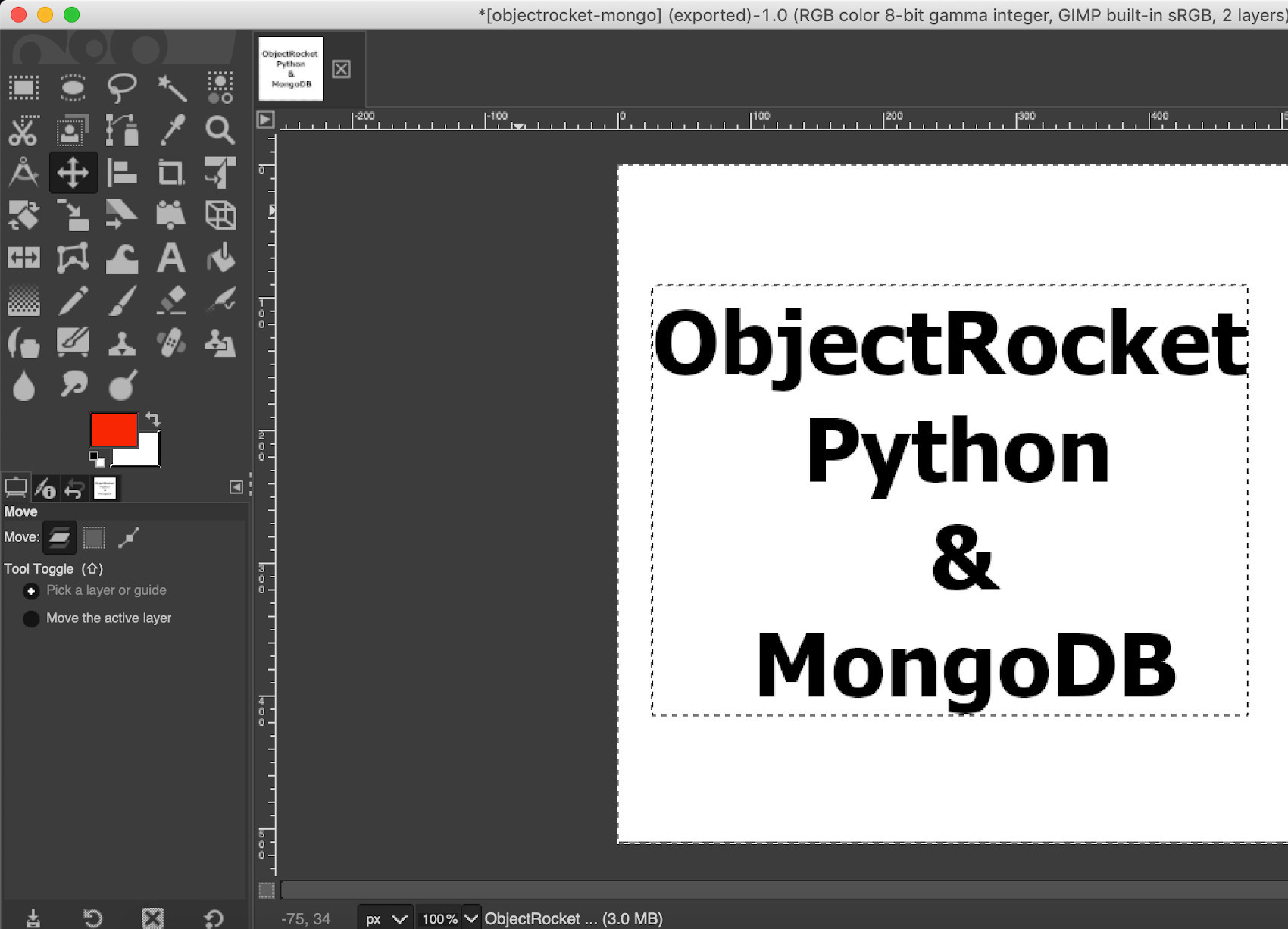
NOTE: The PyTesseract library has its limitations, and it may have trouble interpreting images with a cursive style font type, smaller font sizes, or images where the text and background have similar colors.
The code in this article was developed and tested with Python 3 in mind, and it’s recommended that you move away from Python 2.7 anyways since it’s deprecated and scheduled to lose support. Use the python3 -V command to verify that Python 3 is installed and working on your system by getting its version number.
Install the Python modules for PyTesseract and PyMongo
You’ll need the PIP3 package manager for Python 3 to install PyTesseract and PyMongo on your server or machine (use the pip3 -V command to return its version number, and pip3 list to see the installed packages).
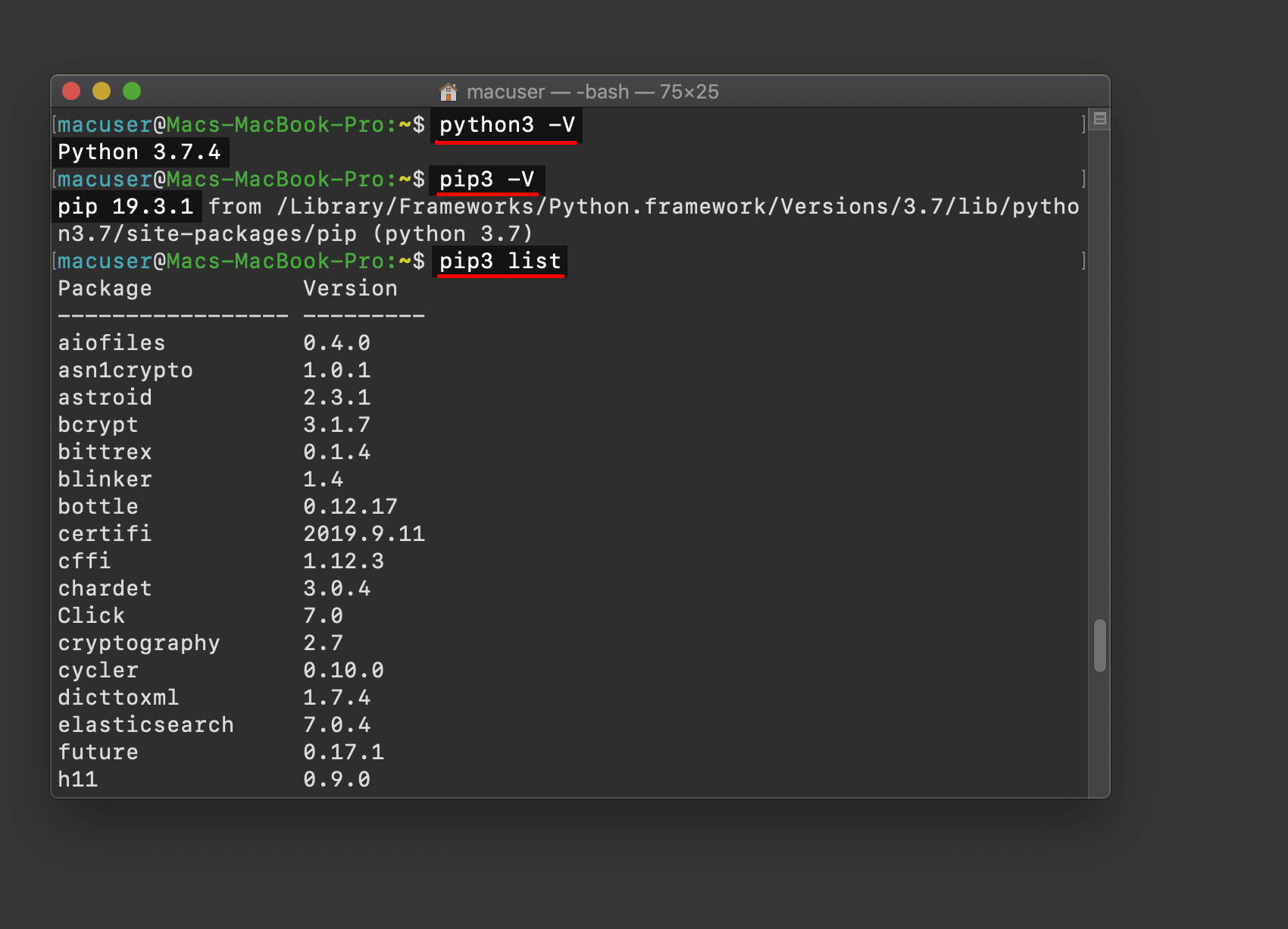
Use the pip3 install command for the “Pip Installs Packages” package manager for Python3 to install the necessary packages. Make sure to install PIP3 on you system if you haven’t already, as it doesn’t always come packaged with Python.
Install PyTesseract with the PIP3 package manager
Now install the pytesseract module so that we can use Google’s Tesseract library in a Python script:
1 | pip3 install pytesseract |
Install Pillow (PIL) for Python3 using the PIP3 package manager
The following bash command will install the Pillow (Python Imaging Library):
1 | pip3 install pillow |
NOTE: Since PyTesseract is dependent on Pillow it may have already been installed for you.
Install the PyMongo Python client for MongoDB
Lastly, use pip3 to install the PyMongo low-level Python client library for MongoDB so that we can make REST API calls to the MongoDB server:
1 | pip3 install pymongo |
Getting a TesseractNotFoundError exception in Python
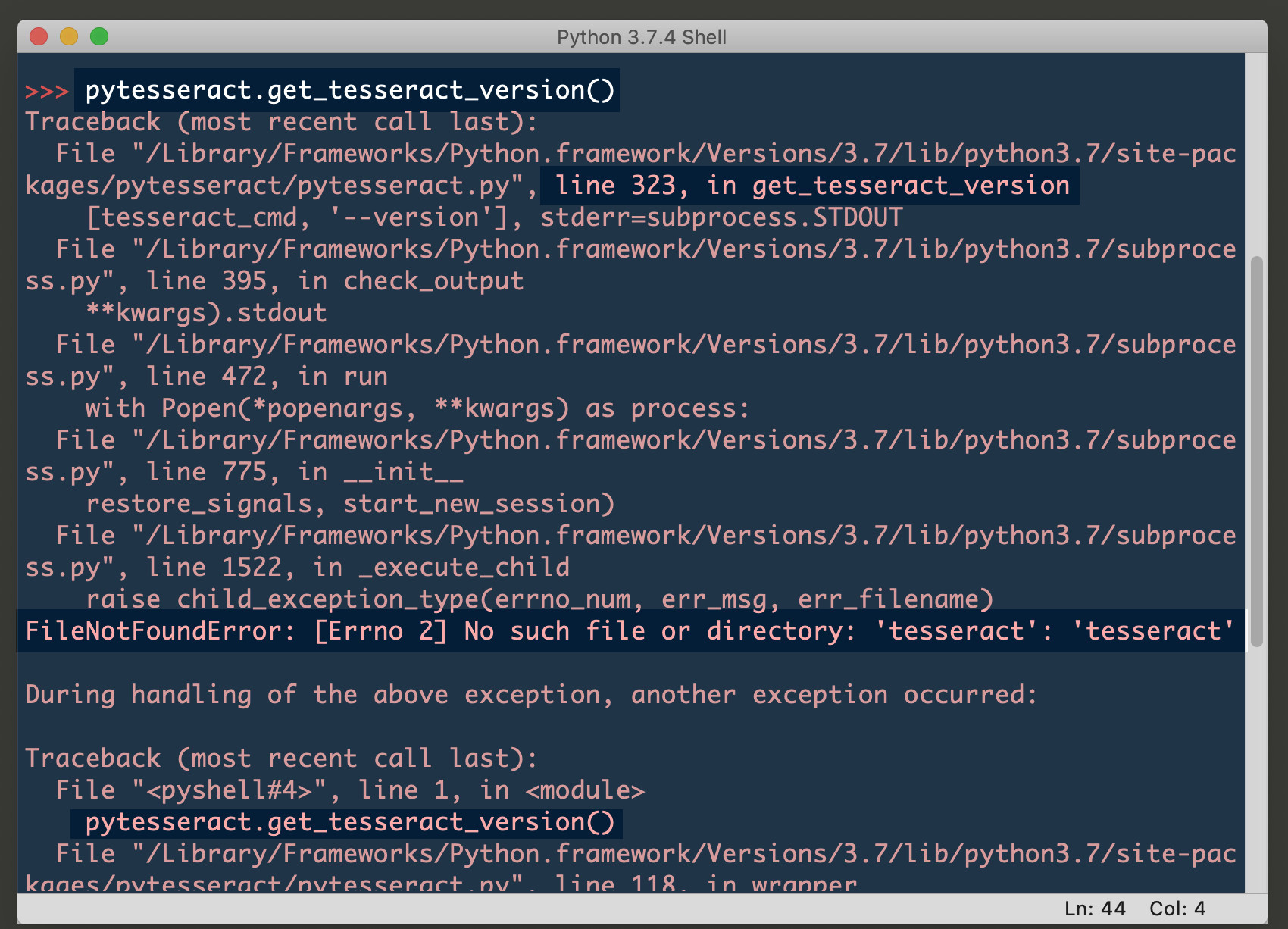
If you get a TesseractNotFoundError while attempting to use PyTesseract then it means you’ll need to install the binary for the library. Use the following bash command to install it on macOS with HomeBrew:
1 | brew install tesseract |
You can also the language libraries for PyTesseract with this brew install command:
1 | brew install tesseract-lang |
NOTE: Make sure that you already have HomeBrew installed on your system before executing the above brew install commands.
On a Linux distro that uses the APT repository you can do the same by executing the following series of bash commands:
1 2 3 | sudo apt update sudo apt install tesseract-ocr sudo apt install libtesseract-dev |
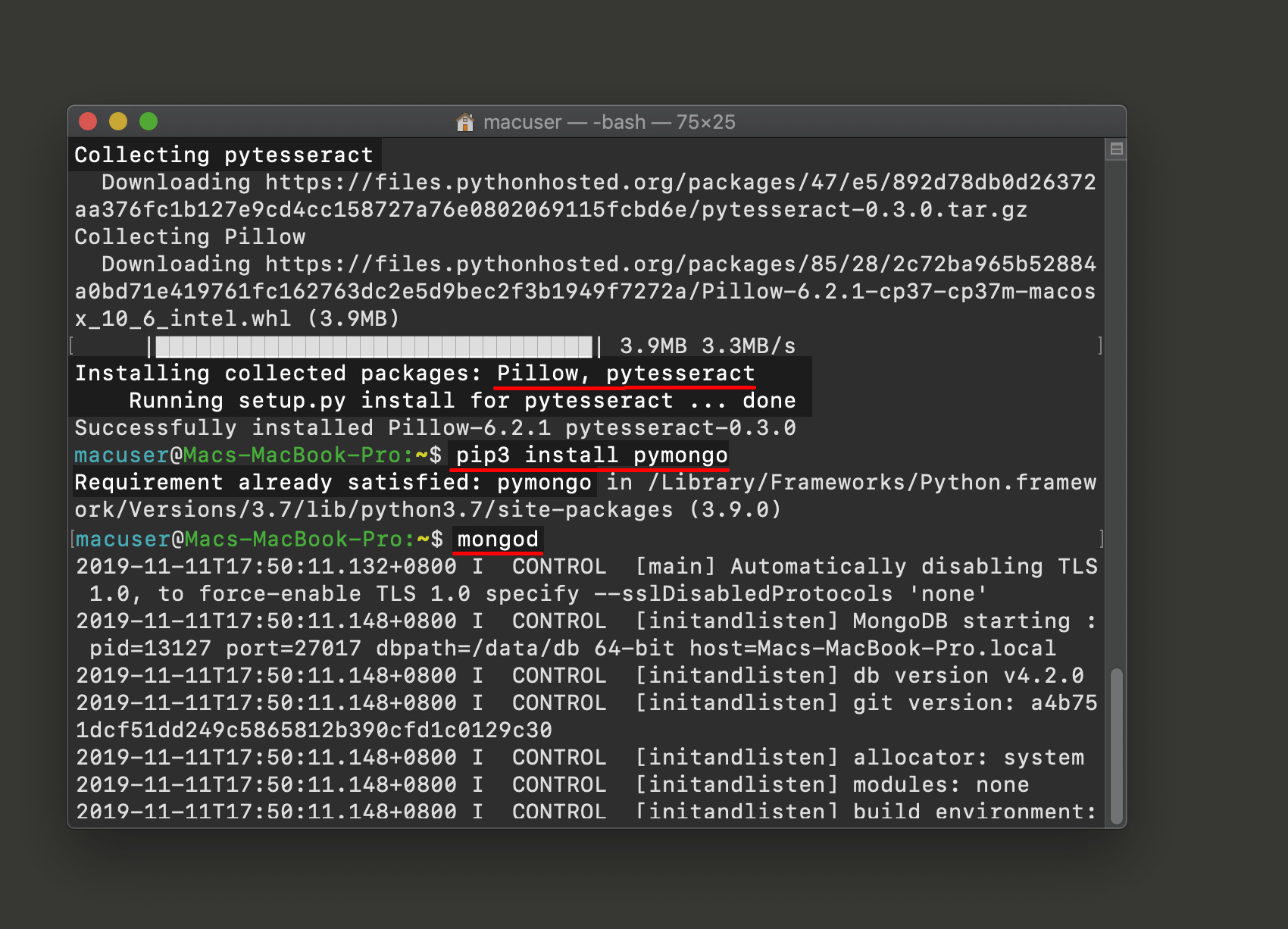
Verify that the MongoDB service is running
Use the mongod command to check that the MongoDB service is running, or type mongo to enter into the mongo Shell JavaScript interface.
Create a Python script for the Tesseract OCR app to insert MongoDB documents
Use the mkdir command to create a folder for the MongoDB-Python app, and make sure to move the image file for your app into the project directory.
You can use the subl command to open the Sublime text editor, or the code command for VS code, although any IDE with Python syntax support will work just fine.
The following bash commands will show you how to create a project directory and a new Python script for the app using Visual Studio Code:
1 2 3 | mkdir mongodb-tesser cd mongodb-tesser code tesseract-app.py |
Import the necessary Python modules for the MongoDB-Tesseract-OCR application
The following Python code will use Python’s built-in import keyword to include the necessary packages for the MongoDB application:
1 2 3 4 5 6 7 8 | # import the Pytesseract library import pytesseract, platform # import the Image method library from PIL from PIL import Image # import PyMongo into the Python script from pymongo import MongoClient |
Use Python’s platform library to troubleshoot the PyTesseract installation
This next block of code will attempt to print the version number for the PyTesseract installation, and, in the case of an import error, it will print some possible solutions to fix the binary and language pack installation depending on the user’s platform:
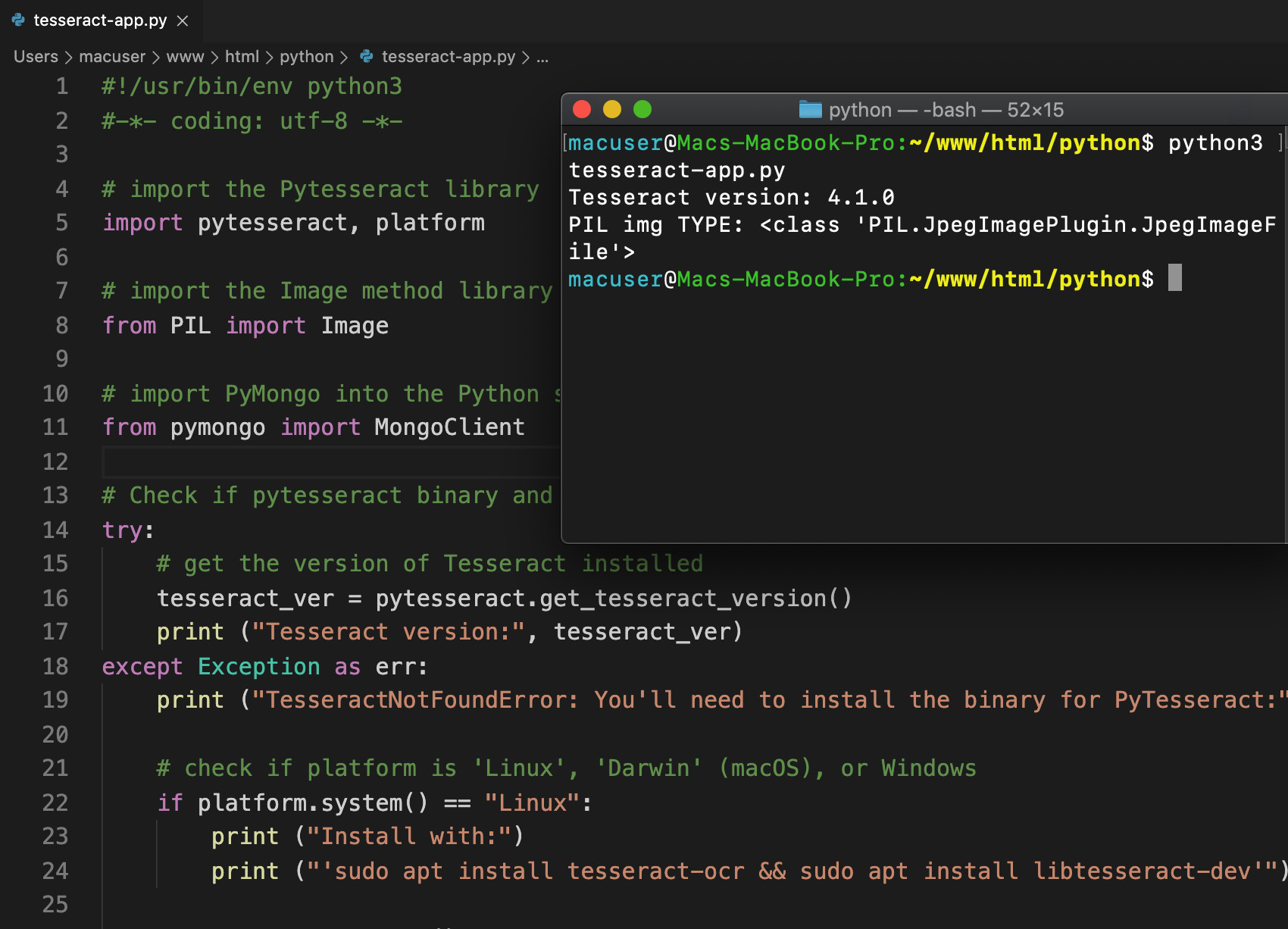
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | # Check if pytesseract binary and language dep are installed try: # get the version of Tesseract installed tesseract_ver = pytesseract.get_tesseract_version() print ("Tesseract version:", tesseract_ver) except Exception as err: print ("TesseractNotFoundError: You'll need to install the binary for PyTesseract:") # check if platform is 'Linux', 'Darwin' (macOS), or Windows if platform.system() == "Linux": print ("Install with:") print ("'sudo apt install tesseract-ocr && sudo apt install libtesseract-dev'") elif platform.system() == "Darwin": print ("Install with:") print ("brew install tesseract && brew install tesseract-lang'") elif platform.system() == "Windows": print ("If you're using Windows then download the binary library and") print ("set the path for 'pytesseract.pytesseract.tesseract_cmd'") |
NOTE: The recommended Linux solution for the TesseractNotFoundError exception will not work if you’re using a “Red Hat” distro of Linux (like Fedora or CentOS). You can, however, try the yum install tesseract && yum install tesseract-langpack-eng commands instead.
Open the image using the Pillow (PIL) library for Python
The following Python code will attempt to load the image file using Pillow’s Image.open() method, and it should return a PIL.JpegImagePlugin object if your target image is a JPEG or JPG image:
1 2 3 4 5 6 7 8 9 10 11 12 | # return a PIL.JpegImagePlugin Image object of the local image try: # target image filename for OCR filename = "objectrocket-mongo.jpg" img = Image.open(filename) print ("PIL img TYPE:", type(img)) except Exception as err: # set the PIL image object to 'None' if exception print ("Image.open() error:", err) img = None |
NOTE: If the image is not located in the same directory as your Python script you’ll have to pass the absolute path for the file, along with its filename, in the string argument for the Image.open() method. The above code should print an error if it cannot find the file, and the img object will subsequently be set to None.
Run the MongoDB Python script using the python3 command
Save the above code and then run the script using the python3 command followed by the Python script’s filename:
1 | python3 tesseract-app.py |
If everything worked properly it should print a response in your terminal or command prompt window that resembles the following:
1 2 | Tesseract version: 4.1.0 PIL img TYPE: <class 'PIL.JpegImagePlugin.JpegImageFile'> |
Conclusion to using Tesseract OCR to insert MongoDB documents
This concludes part one of an article series that will show you how insert text data from an image as a string into a MongoDB collection. In the next part we’ll use the PyTesseract library to read the PIL image object, and then insert that data as a document into a MongoDB collection with a RESTful API call using the PyMongo low-level client library.
Just the Code
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 | #!/usr/bin/env python3 #-*- coding: utf-8 -*- # import the Pytesseract library import pytesseract, platform # import the Image method library from PIL from PIL import Image # import PyMongo into the Python script from pymongo import MongoClient # import the JSON library for Python for pretty print import json # import the datetime() method for timestamps from datetime import datetime # Check if pytesseract binary and language dep are installed try: # get the version of Tesseract installed tesseract_ver = pytesseract.get_tesseract_version() print ("Tesseract version:", tesseract_ver) except Exception as err: print ("TesseractNotFoundError: You'll need to install the binary for PyTesseract:") # check if platform is 'Linux', 'Darwin' (macOS), or Windows if platform.system() == "Linux": print ("Install with:") print ("'sudo apt install tesseract-ocr && sudo apt install libtesseract-dev'") # For Red Hat/Fedora: 'yum install tesseract && yum install tesseract-langpack-eng' elif platform.system() == "Darwin": print ("Install with:") print ("brew install tesseract && brew install tesseract-lang'") elif platform.system() == "Windows": print ("If you're using Windows then download the binary library and") print ("set the path for 'pytesseract.pytesseract.tesseract_cmd'") |


Pilot the ObjectRocket Platform Free!
Try Fully-Managed CockroachDB, Elasticsearch, MongoDB, PostgreSQL (Beta) or Redis.
Get Started