Use Tesseract OCR to Insert MongoDB Documents
Introduction to using Tesseract OCR to insert MongoDB documents
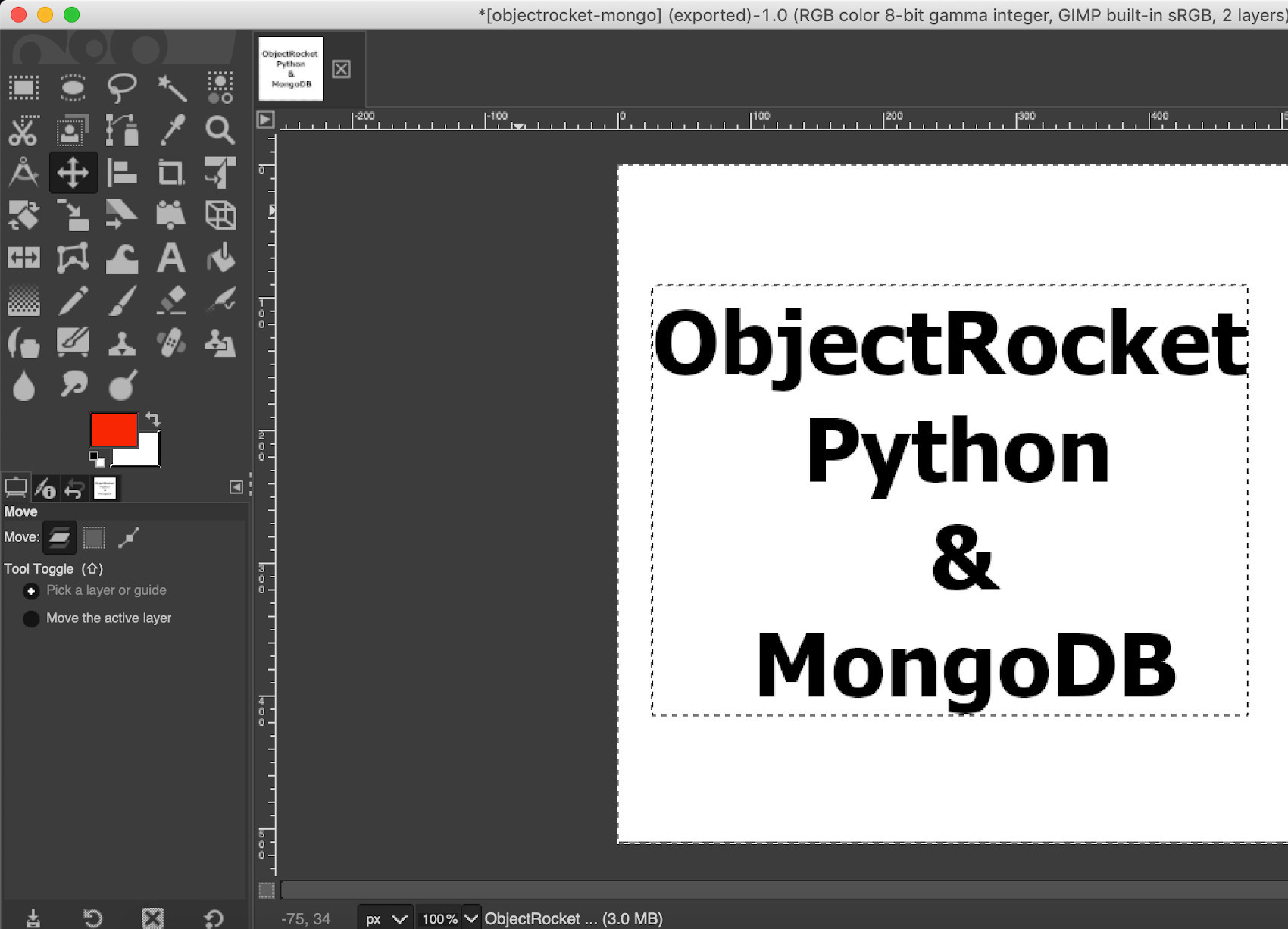
Google’s Tesseract OCR (Optical Character Recognition) software allows you to analyze the text in an image in order to process it and render it as a string of characters. This article will demonstrate how you can use Python’s pytesseract and pymongo modules to read an image and then insert its text data as a MongoDB document.
Check out the first part of this article series for instructions on setting up your project. This article assumes that you already have an image that you can use for extracting text data, and that you’ve already installed the necessary Python modules using PIP3. Please make sure the MongoDB service is installed and running before attempting to run the Python code.
Fixing the ‘TesseractNotFoundError’ in Python
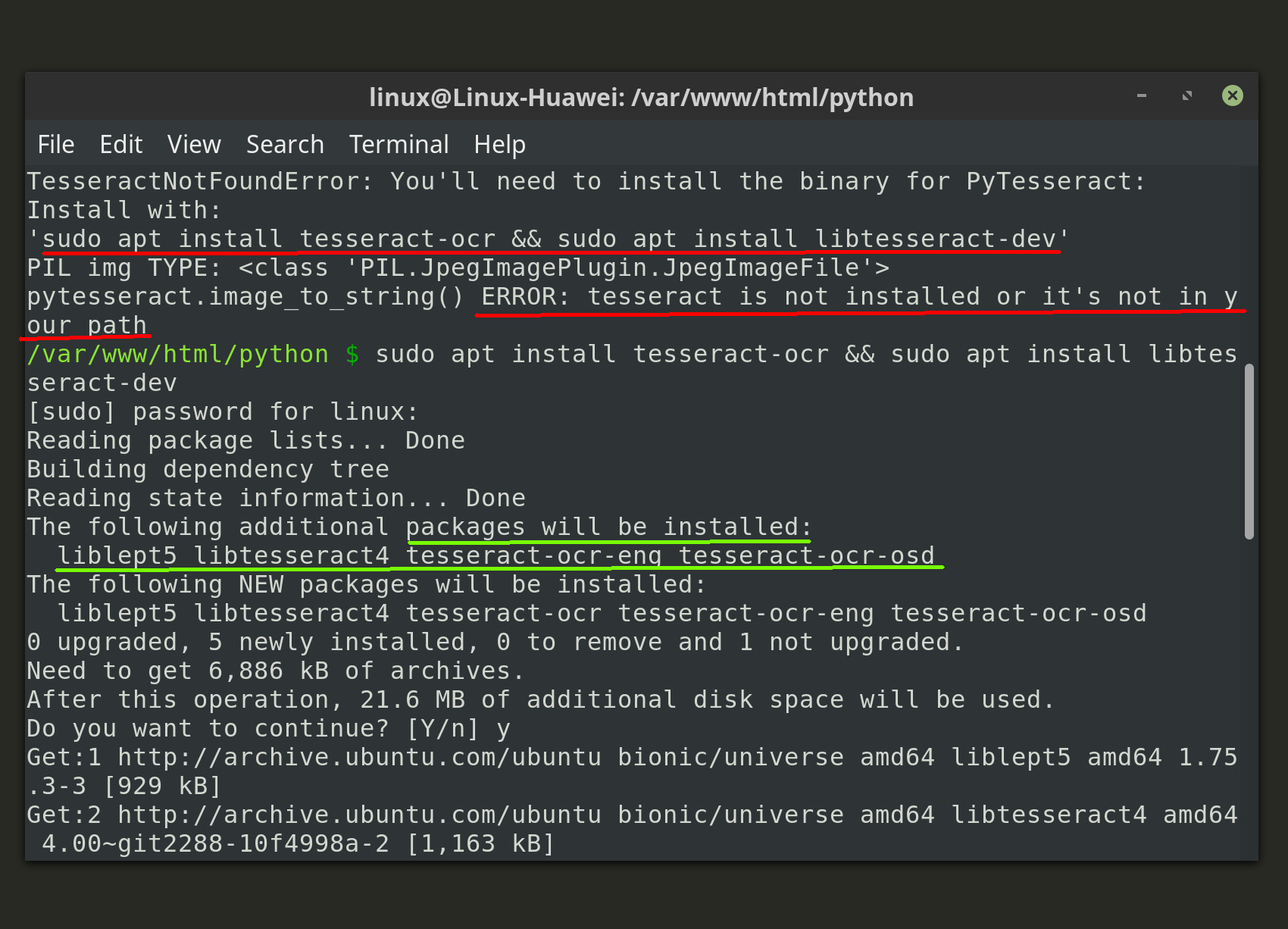
Installing the pytesseract library with the PIP package manager isn’t enough, and Python may return a TesseractNotFoundError while attempting to use the PyTesseract library methods. This typically means that Tesseract’s binary layer dependencies, or its language libraries, are not installed.
Install TesserAct OCR for Debian-based Linux
Use the following bash command to install the libraries on a Debian-based distro of Linux like Ubuntu or Linux Mint:
1 | sudo apt install tesseract-ocr && sudo apt install libtesseract-dev |
Install TesserAct OCR for Red Hat (RHEL) Linux
If you’re using a Red Hat distro of Linux (like Fedora or CentOS) then use the YUM package manager to install the Tesseract libraries:
1 | yum install tesseract && yum install tesseract-langpack-eng |
Install TesserAct OCR for macOS with Homebrew
Use the brew install command to install the necessary packages on macOS:
1 | brew install tesseract && brew install tesseract-lang |
Install TesserACT OCR on Windows
If you’re using Windows then download the correct Tesseract binary executable for your version of Windows, and set the environment path for pytesseract.pytesseract.tesseract_cmd.
Import the Python modules for your Tesseract-MongoDB app
The following Python code will import the PyTesseract and MongoClient libraries, as well as a few other built-in system libraries like os, platform, and the Pillow library, or PIL (Python Imaging Library), so that Python can read the image’s data into memory:
1 2 3 4 5 6 7 8 9 10 11 12 | # import the Pytesseract library import pytesseract, platform, os # import the Image method library from PIL from PIL import Image # import PyMongo into the Python script from pymongo import MongoClient # import the datetime() method for timestamps from datetime import * from time import time |
We’ll use the datetime and time libraries to format timestamps and create a creation date field for the MongoDB document.
Use Pillow (PIL) to load the image file into memory
Now let’s declare a string object for the image’s filename, and then use Pillow’s Image.open() method to load the image’s pixel data into the script’s memory.
Use the following code to execute the code within a try-except indentation block to catch any errors that may arise:
1 2 3 4 5 6 7 8 9 10 11 12 | # return a PIL.JpegImagePlugin Image object of the local image try: # target image filename for OCR filename = "objectrocket-mongo.jpg" img = Image.open(filename) print ("PIL img TYPE:", type(img)) except Exception as err: # set the PIL image object to 'None' if exception print ("Image.open() error:", err) img = None |
NOTE: Make sure to pass the absolute path for the image file, along with the filename, if it’s not located in the same directory as the Python script. If Python cannot find the file, or otherwise raises an exception, then the above code will set our img object to None.
Connect to MongoDB using the PyMongo client library
If no errors were returned then the example JPG image should be rendered by the Pillow library as a PIL.JpegImagePlugin.JpegImageFile object. Use the following code to evaluate the img object and connect to MongoDB with PyMongo’s MongoClient() method library if the PIL object is not set to None:
1 2 3 4 5 6 7 8 9 | # insert image data if Image.open() was successful if img != None: # create a client instance of the MongoClient library client = MongoClient('localhost', 27017) # declare MongoDB database and collection instances db = client.image_db col = db["Images Collection"] |
NOTE: MongoDB collection’s are allowed to have spaces, but database names are not.
Use PyTesseract to extract the image’s text
Now that we’ve connect to MongoDB we can pass img PIL object to the PyTesseract library’s image_to_string() method to make an API call to the Tesseract engine in order to have it return a string of text data from the image object.
Use the following code to get the text data within another try-except indentation block:
1 2 3 | try: # get a string of the PIL image object's text data_from_image = pytesseract.image_to_string(img, lang="eng") |
Use the following line of code if you’d like to replace the newline characters in the image’s text string with spaces:
1 2 3 | # replace the newline chars with a space data_from_image = data_from_image.replace("\n", " ").strip() print ("\ndata_from_image:", data_from_image) |
Get the image’s file stats before inserting into MongoDB
The following code will use Python’s os.stat() method library to get more detailed information from the image file so that it can be inserted into the MongoDB document along with the text data:
1 2 3 | # get the image file's stats file_stats = os.stat( filename ) print ("\nfile_stats:", file_stats, "\n") |
Create a timestamp for the image’s MongoDB document
This next code will attempt to get the creation date for the file so that it can inserted as a field value for the MongoDB document:
1 2 3 4 5 6 7 8 9 10 | # get the creation date for the image file if hasattr(file_stats, 'st_birthtime') == True: date_stamp = file_stats.st_birthtime elif hasattr(file_stats, 'st_mtime') == True: date_stamp = file_stats.st_mtime else: date_stamp = time() # create a datetime object from UNIX time stamp creation_date = datetime.utcfromtimestamp( date_stamp ) |
NOTE: If the meta data for the image file’s creation date cannot be found then the above code will use the current time instead.
Create a Python dict for the MongoDB document
The code in this section will create a Python dict object for the document data that will be passed to PyMongo’s insert_one() method call.
Use this next bit of code to format the filename so that the absolute path is not included (if applicable) when the data gets included with the other document data:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | # fix the file name if needed img_filename = filename # Platform is Windows if platform.system() == "Windows": if "\" in img_filename: start = img_filename.find("\") img_filename = img_filename[start:] # UNIX-based OS like macOS or Linux else: if "/" in img_filename: start = img_filename.find("/") img_filename = img_filename[start:] |
Declare a Python dictionary for the image’s text data
The following code declares a dictionary ({}) that will store the image data as key-value pairs:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | # Declare a Python dict for the MongoDB doc img_doc = { "filename":img_filename, "creation_date": creation_date, "text": data_from_image, "timestamp": datetime.utcnow() } # print the dict object for the doc print (img_doc) except Exception as err: # set the image dict object to 'None' if exception print ("pytesseract.image_to_string() ERROR:", err) img_doc = None |
NOTE: PyMongo has support for Python’s datetime() format, so it will have no problem interpreting datetime.datetime(2019, 11, 11, 6, 16, 23) as 2019-11-11T06:16:23.000+00:00 when it inserts the data.
Insert the image’s text data into MongoDB as a document
The last part of our code will evaluate the img_doc to assert that its value is not set to None, and then it will pass the dict object to the MongoDB collection object’s insert_one() method:
1 2 3 4 5 6 7 8 | try: # attempt to insert the image text as a MongoDB doc if img_doc != None: insert_id = col.insert_one(img_doc).inserted_id print ("MongoDB doc ID for image insertion:", insert_id) except Exception as err: print ("MongoDB client insert_one() ERROR:", err) |
NOTE: The inserted_id method attribute will instruct PyMongo to return only the document ID, otherwise PyMongo will return the complete pymongo.results.InsertOneResult object.
The document data being inserted should look something like the following JSON object:
1 2 3 4 5 6 7 | { "_id":"5dcaa4c7e979d56e233b5c49", "filename":"objectrocket-mongo.jpg", "creation_date":"2019-11-11T06:16:23.000Z", "text":"ObjectRocket Python & MongoDB", "timestamp":"2019-11-12T12:25:43.705Z" } |
Conclusion to using Tesseract OCR to insert MongoDB documents
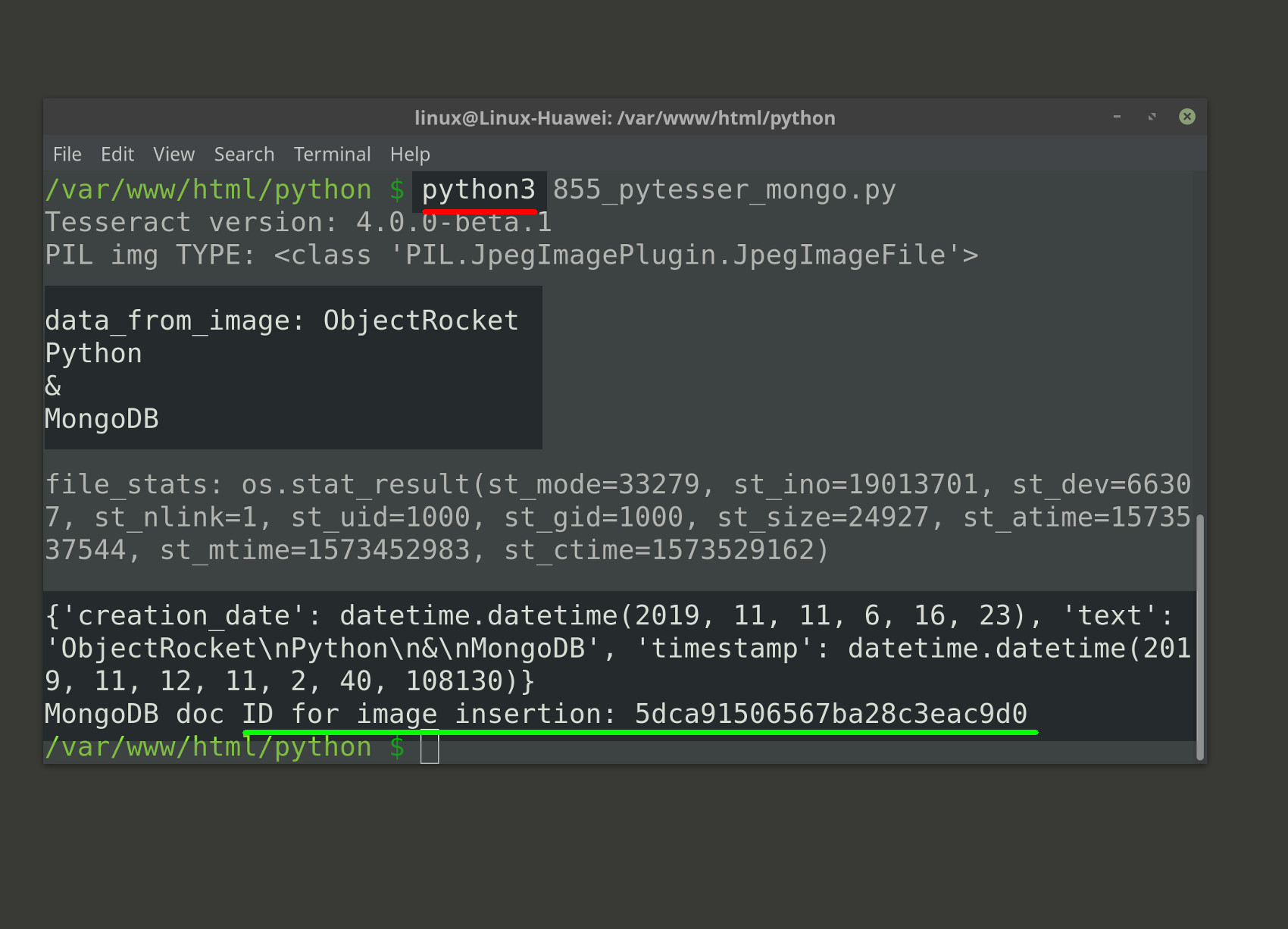
Make sure to save the above code in a Python script (using the .py file extension), and then use the python3 bash command to execute the file:
1 | python3 tesseract-app.py |
The Python code should return something like the following (at the end of the script) if the MongoDB document insertion was successful:
1 | MongoDB doc ID for image insertion: 5dcaa4c7e979d56e233b5c49 |
Use MongoDB Compass to verify that the image data was inserted
If you have it installed already, use the MongoDB Compass GUI application to verify that the image data was successfully inserted using Python.
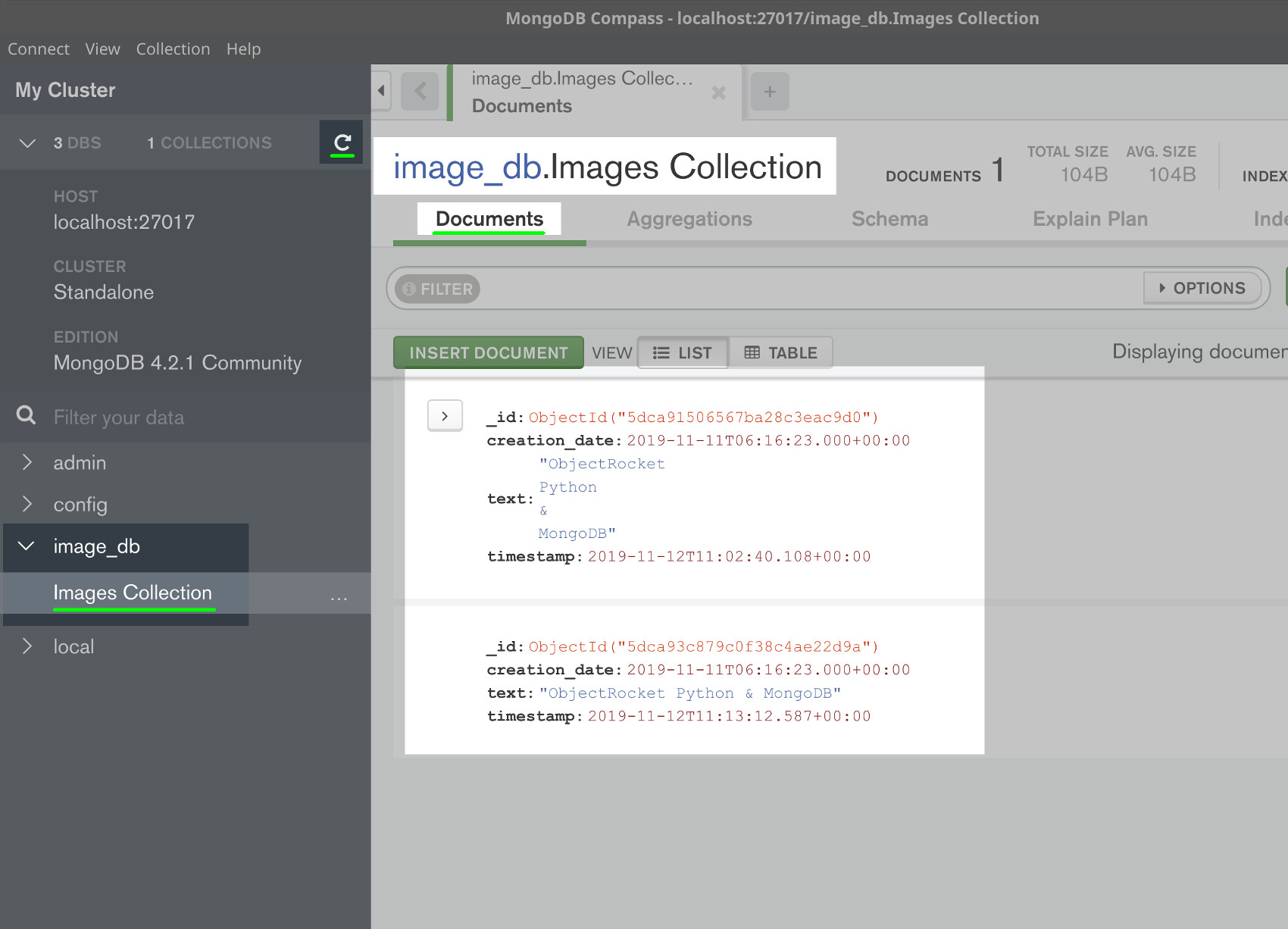
NOTE: The above screenshot shows how your document might look with and without the newline characters (\n) being replaced with spaces.
The document for the image’s text data should look something like the following in the MongoDB Compass application:
_id: 5dcaa4c7e979d56e233b5c49 filename: “objectrocket-mongo.jpg” creation_date: 2019-11-11T06:16:23.000+00:00 text: “ObjectRocket Python & MongoDB” timestamp: 2019-11-12T12:25:43.705+00:00
This concludes the two-part article series demonstrating how you can use Python, PyTesseract, and PyMongo to extract the text data from an image and insert it into a MongoDB collection as a document.
Just the Code
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 | #!/usr/bin/env python3 #-*- coding: utf-8 -*- # import the Pytesseract library import pytesseract, platform # import the Image method library from PIL from PIL import Image # import PyMongo into the Python script from pymongo import MongoClient # import the JSON library for Python for pretty print import json, os # import the datetime() method for timestamps from datetime import * from time import time # Check if pytesseract binary and language dep are installed try: # get the version of Tesseract installed tesseract_ver = pytesseract.get_tesseract_version() print ("Tesseract version:", tesseract_ver) except Exception as err: print ("TesseractNotFoundError: You'll need to install the binary for PyTesseract:") # check if platform is 'Linux', 'Darwin' (macOS), or Windows if platform.system() == "Linux": print ("Install with:") print ("'sudo apt install tesseract-ocr && sudo apt install libtesseract-dev'") # For Red Hat/Fedora: 'yum install tesseract && yum install tesseract-langpack-eng' elif platform.system() == "Darwin": print ("Install with:") print ("'brew install tesseract && brew install tesseract-lang'") elif platform.system() == "Windows": print ("If you're using Windows then download the binary library and") print ("") # return a PIL.JpegImagePlugin Image object of the local image try: # target image filename for OCR filename = "objectrocket-mongo.jpg" img = Image.open(filename) print ("PIL img TYPE:", type(img)) except Exception as err: # set the PIL image object to 'None' if exception print ("Image.open() error:", err) img = None # insert image data if Image.open() was successful if img != None: # create a client instance of the MongoClient library client = MongoClient('localhost', 27017) # declare MongoDB database and collection instances db = client.image_db col = db["Images Collection"] try: # get a string of the PIL image object's text data_from_image = pytesseract.image_to_string(img, lang="eng") # replace the newline chars with a space data_from_image = data_from_image.replace("\n", " ").strip() print ("\ndata_from_image:", data_from_image) # get the image file's stats file_stats = os.stat( filename ) print ("\nfile_stats:", file_stats, "\n") # get the creation date for the image file if hasattr(file_stats, 'st_birthtime') == True: date_stamp = file_stats.st_birthtime elif hasattr(file_stats, 'st_mtime') == True: date_stamp = file_stats.st_mtime else: date_stamp = time() # create a datetime object from UNIX time stamp creation_date = datetime.utcfromtimestamp( date_stamp ) # fix the file name if needed img_filename = filename # Platform is Windows if platform.system() == "Windows": if "\" in img_filename: start = img_filename.find("\") img_filename = img_filename[start:] # UNIX-based OS like macOS or Linux else: if "/" in img_filename: start = img_filename.find("/") img_filename = img_filename[start:] # Declare a Python dict for the MongoDB doc img_doc = { "filename":img_filename, "creation_date": creation_date, "text": data_from_image, "timestamp": datetime.utcnow() } # print the dict object for the doc print (img_doc) except Exception as err: # set the image dict object to 'None' if exception print ("pytesseract.image_to_string() ERROR:", err) img_doc = None try: # attempt to insert the image text as a MongoDB doc if img_doc != None: insert_id = col.insert_one(img_doc).inserted_id print ("MongoDB doc ID for image insertion:", insert_id) except Exception as err: print ("MongoDB client insert_one() ERROR:", err) |

Pilot the ObjectRocket Platform Free!
Try Fully-Managed CockroachDB, Elasticsearch, MongoDB, PostgreSQL (Beta) or Redis.
Get Started