Parse Lines In A Text File And Insert Them As MongoDB Documents Using Python
Introduction
MongoDB and Python are known to work particularly well together, making it possible to accomplish arduous tasks with quick and simple scripts. In this article, we’ll show you a perfect example of this harmony between Python and MongoDB. We’ll demonstrate how you can iterate over the contents of a dictionary text file to parse out terms and definitions, inserting those entries as MongoDB documents. If this sounds like a task requiring reams of complex code, fear not– everything we described can be done with fewer than 200 lines of Python code.
Before you try parsing a line-by-line text file and inserting MongoDB documents with Python, make sure you own the rights to the content being inserted, or use an open source or public domain text document. For the purposes of this article, we’ll be using an open source eBook titled “Webster’s Unabridged Dictionary by Various”, which can be found on the Gutenberg website.
Please continue reading as we parse lines of a text file and insert them as MongoDB Documents with Python.
Prerequisites
Let’s go over a couple of basic prerequisites that need to be taken care of before we can proceed with our tutorial:
Make sure that the text file you’re planning on inserting is on the same machine that’s running your MongoDB server. Use the
mongodormongocommands to verify that the server is running.Python 3 should be installed on the same machine, and the PyMongo Python driver needs to be installed using the PIP3 package manager:
1 | pip3 install pymongo |
- Make sure you have some free space on your machine or server to download the copy of Webster’s dictionary before running the code shown in this article.
Download and unzip the text file for Webster’s Dictionary
Now that we’ve reviewed the prerequisites, let’s open another browser tab and navigate to the download page for the Webster’s dictionary files. Download either the zip archive (29765-8.zip) or the text file for the dictionary. Unzip the archive and move the text file (which will be about 29MB in size) to the same directory as the Python script.
Create a Python script that will parse the text file and insert the data as MongoDB documents
If you’re running macOS or Linux, you can use the touch command to create a new Python script:
1 | touch insert_dictionary.py |
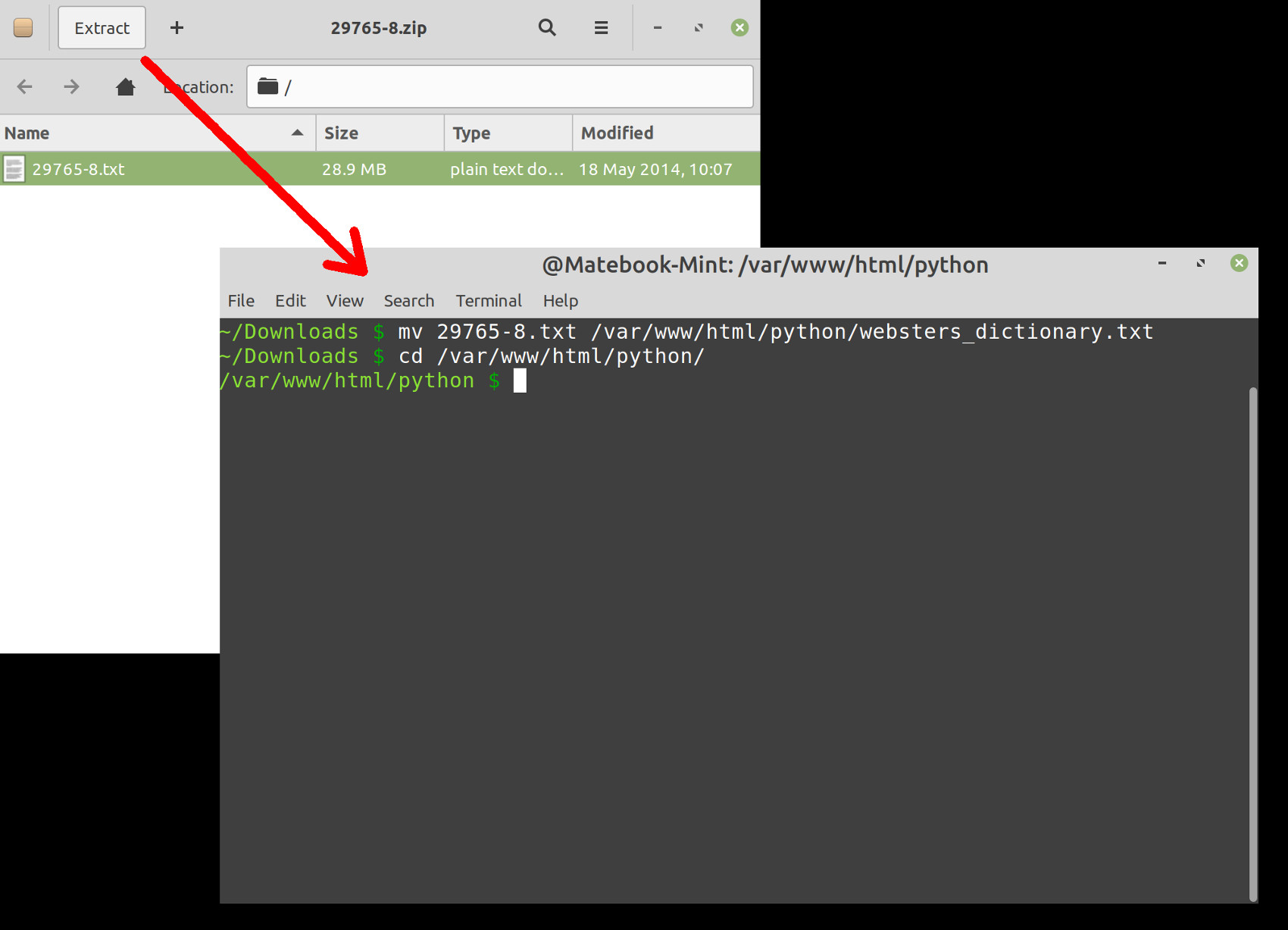
Rename and move the dictionary file to the location of the Python script
If you’re in the same directory as the ~/Downloads folder, use the bash command shown below to rename the filename 29765-8.txt and move it into the same directory as the Python script:
1 | mv 29765-8.txt /var/www/html/python/websters_dictionary.txt |
Be sure to replace the file path with a value that matches the path of your Python script. If you’re not sure what the path is, use the pwd command to find out.
Import the Python necessary packages for inserting MongoDB documents
Next, we’ll import the MongoClient and errors attribute libraries from the PyMongo driver library:
1 2 | # import the MongoClient class from pymongo import MongoClient, errors |
Import Python’s Pickle library to serialize the dictionary entries
1 2 | # import Python's pickle library to serialize the dictionary import pickle |
Import Python’s time and JSON libraries
We’ll use the json.dumps() method to indent the JSON response that will be returned by MongoDB when the API response is printed:
1 2 | # import Python's time and JSON libraries import time, json |
Instantiate float variable for the Python’s scripts start time
We’ll also need to import the time library to track how many seconds it takes to iterate, parse, and insert the text data. The time.time() method will be used to return a float of the epoch time at the start of the script:
1 2 | # record the start time for the script start_time = time.time() |
Declare a function that will iterate and parse the dictionary text file
Declare a function that will open the Webster’s dictionary text file, iterate and parse its data, and then put each dictionary entry into a dictionary:
Declare the get_webster_entries() function for parsing text
Our get_webster_entries() function will require a string passed to it representing the text file’s name and directory path:
1 2 | # declare a function that parsed the Webster's text file def get_webster_entries(filename): |
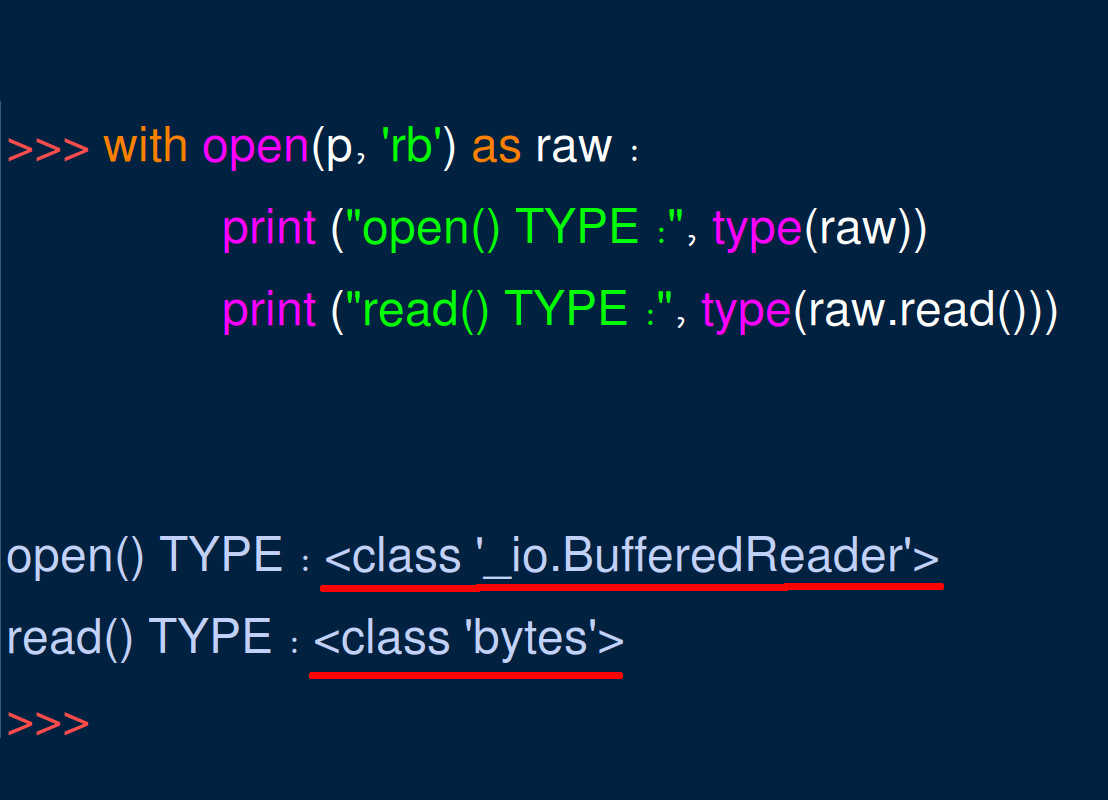
Using Python’s open() function and managing system resources
Next, we’ll use Python’s open() function to create a _io.BufferedReader object of the text file’s data. We’ll then use the object’s read() method to have it convert the data into a bytes object:
1 2 3 | # use the open() function to open the text file with open(filename, 'rb') as raw: data = raw.read() |
NOTE: It’s a good idea to use the with keyword and have it open the file in an indentation so that it will free your system’s memory once the operation is complete. Otherwise, you’ll have to call the buffered reader’s close() method to have Python’s garbage collector immediately free up those system resources.
Decode the bytes string for the dictionary data as UTF-8
The bytes data from the text file needs to be converted to a string. We can use the decode() method to convert the bytes string to a UTF-8 unicode string:
1 2 | # decode the file as UTF-8 and ignore errors data = data.decode("utf-8", errors='ignore') |
Note that we opted to ignore errors as we convert to UTF-8. This may leave some minor “holes” in the data, but it’s necessary to avoid Python returning a UnicodeDecodeError.
Split the string into a list of strings using the “rn” newline characters
1 2 | # split the dictionary file into list by: "\r\n" data = data.split("\r\n") |
Declare an empty Python dictionary for the dictionary entries and iterate over the list of strings
The dictionary entries can be stored as dictionary keys, and the list of strings can be iterated over using the enumerate() function:
1 2 3 4 5 | # create an empty Python dict for the entries dict_data = {} # iterate over the list of dictionary terms for num, line in enumerate(data): |
Check for new dictionary entries in the string data
You may notice that each entry in this version of Webster’s dictionary starts with a uppercase word(s)(e.g. MODALITY). This makes it easy to have Python determine where to start for each dictionary entry and its definitions:
1 2 3 4 5 6 7 | try: # entry titles in Webster's dict are uppercase if len(line) < 40 and line.isupper() == True: # new entry for the dictionary current = line.title() current = current.replace("'S", "'s") |
The code shown above code converts the term to title case and fixes the 's possessive. Be sure to replace the periods (.) in the entry title so that MongoDB won’t return an error:
1 2 | # MongoDB docs must not have "." current = current.replace(".", "") |
Add the dictionary entry to the Python dict object
Before adding an entry to the dict object, check to see if the dictionary entry has already been added, and count the definitions for each entry:
1 2 3 4 5 6 7 8 9 10 11 | # append an empty dict object to the list for the entry if current not in dict_data: # reset the definition count def_count = 1 # new dictionary entry dict_data[current] = {"definitions": 1} else: # append to dict entry if needed def_count = dict_data[current]["definitions"] + 1 dict_data[current]["definitions"] = def_count |
Look for the dictionary entry’s definitions
The version of Webster’s dictionary that we’re using denotes definitions in two different ways. For the first definition of a word, the line starts with "Defn:"; for all subsequent definitions, it starts with a number and period like this: "2.".
In our code, we’ll look for the "Defn:" substring inside each line as we iterate through the data. The presence of the substring signals that a new definition starts on the line being evaluated:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | # add a new definition by looking for "Defn" if "Defn:" in line: # concatenate strings for the definitions def_title = "Defn " + str(def_count) def_content = line.replace("Defn: ", "") # add the definition to the defn title key dict_data[current][def_title] = def_content # add to the definition count def_count += 1 # add definition by number and period elif "." in line[:2] and line[0].isdigit(): # concatenate strings for the definitions def_title = "Defn " + str(def_count) def_content = line = line[line.find(".")+2:] # make sure content for definition has some length if len(def_content) >= 10: # add the definition to the defn title key dict_data[current][def_title] = def_content # add to the definition count def_count += 1 |
Make sure to increment the entry’s def_count variable each time a definition is added to keep accurate track of all the definitions.
Update the number of definitions and return the dict data
We need to end the try-except indentation and update the current entry’s "definitions" key before returning the dict_data object at the end of the function:
1 2 3 4 5 6 7 8 9 10 11 12 | except Exception as error: # errors while iterating with enumerate() print ("\nenumerate() text file ERROR:", error) print ("line number:", num) try: # update the number of definitions dict_data[current]["definitions"] = def_count-1 except UnboundLocalError: pass return dict_data |
Have the get_webster_entries() function return the dictionary entries
At this point, we’re ready to call the function by passing the text file’s name as a string:
1 2 | # call the function and return Webster's dict as a Python dict dictionary = get_webster_entries("websters_dictionary.txt") |
NOTE: Make sure to specify the exact location of the text file in the filename string if it is not located in the same directory as this Python script.
Put the dictionary entries into a list for the MongoDB insert_many() method call
The PyMongo client driver’s insert_many() method requires that a Python list ([]) object containing dict objects be passed to its method call, so we’ll need to put our entries into a list.
Instantiate an empty Python list for the MongoDB documents
Let’s declare the empty Python list that will contain the dictionary entries as Python dict objects. This list will ultimately be inserted into a MongoDB collection:
1 2 | # declare an empty list for the final MongoDB docs to be inserted final_list = [] |
Keep track of the entries that get removed because they have no content, and iterate over the dictionary’s object’s key-value pairs in order to construct a new MongoDB document with each iteration:
1 2 3 4 5 6 7 8 9 10 11 12 13 | # tally the # of entries that won't be inserted rem = 0 # iterate over the dictionary entries and definitions for entry, val in dictionary.items(): # only add to the list if it has a definition if val != {'definitions': 1}: # put the final dictionary entry into the list obj = {'entry': entry} # update the entry with definitions for the document obj.update(val) |
Append the new MongoDB document object containing the dictionary entry to the list:
1 2 3 4 5 | # add the dictionary object to the MongoDB list final_list += [ obj ] else: # tally the removed entries rem += 1 |
Print information about the dictionary entries queued for MongoDB insertion
Print the list of dictionary entries and other information about the data about to be inserted into a MongoDB collection:
1 2 3 4 5 | # uncomment the following to print the complete list of entries #print (final_list) # print the num of entries with empty definitions print ("# of entries removed:", rem) |
Declare a client instance of MongoDB and insert the dictionary entries
Now, let’s declare a new client instance with the MongoClient() method library. Be sure to pass the correct domain and port parameters for the host server:
1 2 | # declare a client instance of the MongoDB PyMongo driver client = MongoClient('localhost', 27017) |
Use the MongoDB client’s server_info() method call to check if the host settings are correct
We’ll need to call the client’s server_info() method inside of a try-except indentation to make sure that the MongoDB server is running:
1 2 3 | try: # server_info() should raise exception if host settings are invalid print ("\nserver_info():", json.dumps(client.server_info(), indent=4)) |
Instantiate MongoDB database and collection objects and pass the dictionary data to insert_many()
Declare the database and collection names for the data parsed from the Webster’s dictionary text file, and pass the list of MongoDB documents to the collection object’s insert_many() method:
1 2 3 4 5 6 | # declare a database and collection instance from the client db = client["WebstersDictionary"] col = db["DictionaryEntries"] # make an API request to MongoDB to insert_many() fruits result = col.insert_many(final_list) |
Parse and print the result object returned by the MongoDB server
1 2 3 4 5 6 7 8 9 10 11 12 | # print the API response from the MongoDB server print ("\ninsert_many() result:", result) # get the total numbers of docs inserted total_docs = len(result.inserted_ids) # print the number of dictionary entries inserted print ("total entries inserted:", total_docs) except errors.ServerSelectionTimeoutError as err: # catch pymongo.errors.ServerSelectionTimeoutError print ("PyMongo ERROR:", err) |
Print the number of seconds that have elapsed since completing the operations
1 2 | # print the time that elapsed print ("Elapsed time (in seconds):", time.time() - start_time) |
Serialize the dictionary entries as a Python pickle object
If you’d like to serialize and store the data locally, it’s not difficult to make that happen. You can do this by passing the dictionary object, containing all of the dictionary entries, to the Pickle library’s dump() method:
1 2 3 | # serialize the Python dictionary as a local pickle file with open("websters_mongodb.pickle","wb") as pickle_dict: pickle.dump(dictionary, pickle_dict) |
Conclusion
Once you’ve finished creating your script based on the example we discussed in this article, it’s time to test it out. Run the Python script to open the dictionary text file and parse its contents to be inserted as MongoDB documents:
1 | python3 insert_dictionary.py |
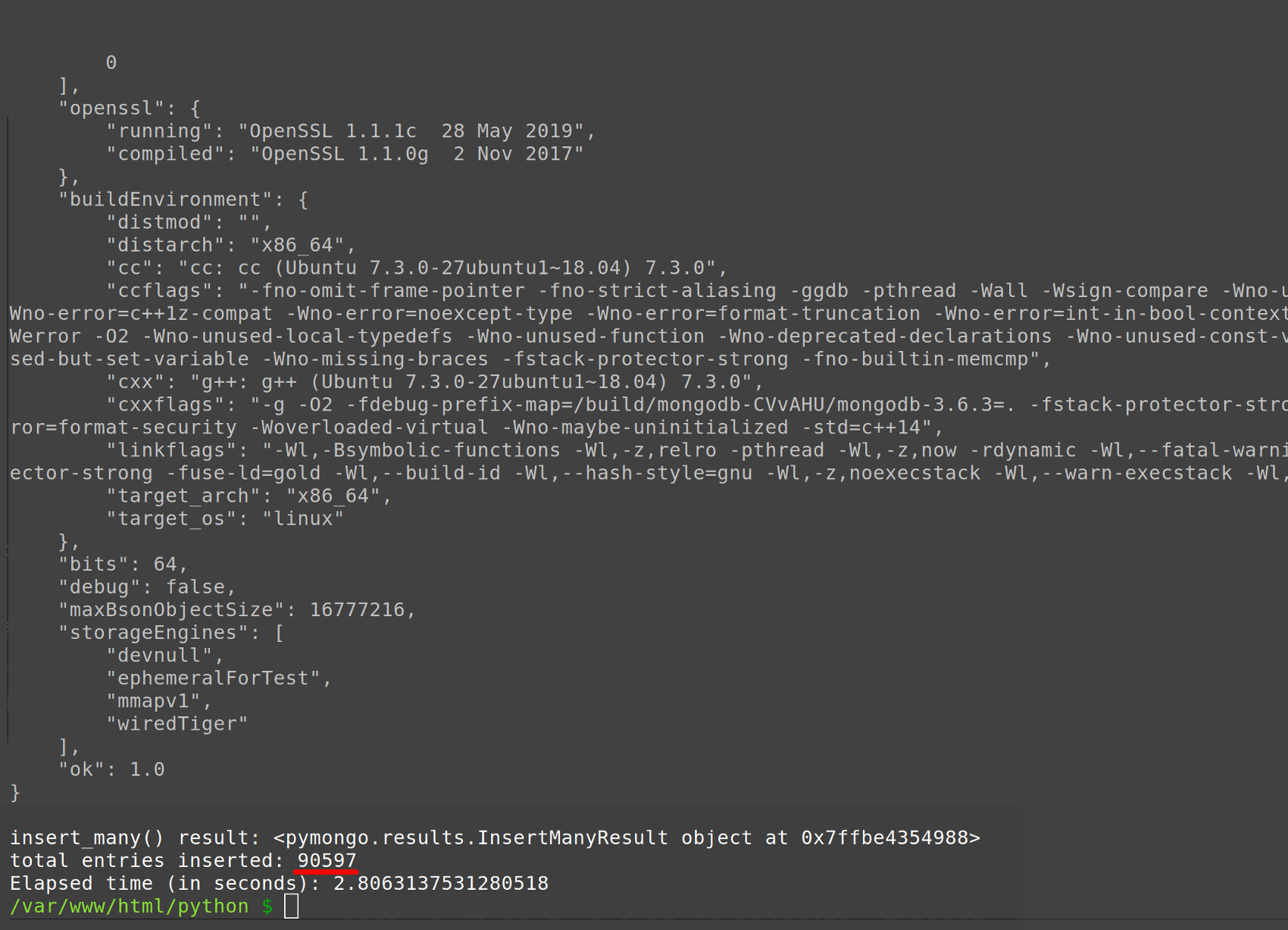
Even if you’re running this code on an older machine, the complete run-time for the script shouldn’t be more than a few seconds :
1 2 3 | total entries inserted: 90597 # of entries removed: 8372 Elapsed time (in seconds): 2.8063137531280518 |
NOTE: Python’s print() statement is very CPU-intensive. Make sure not to avoid using print() while iterating over the dictionary entries to keep your code running efficiently.
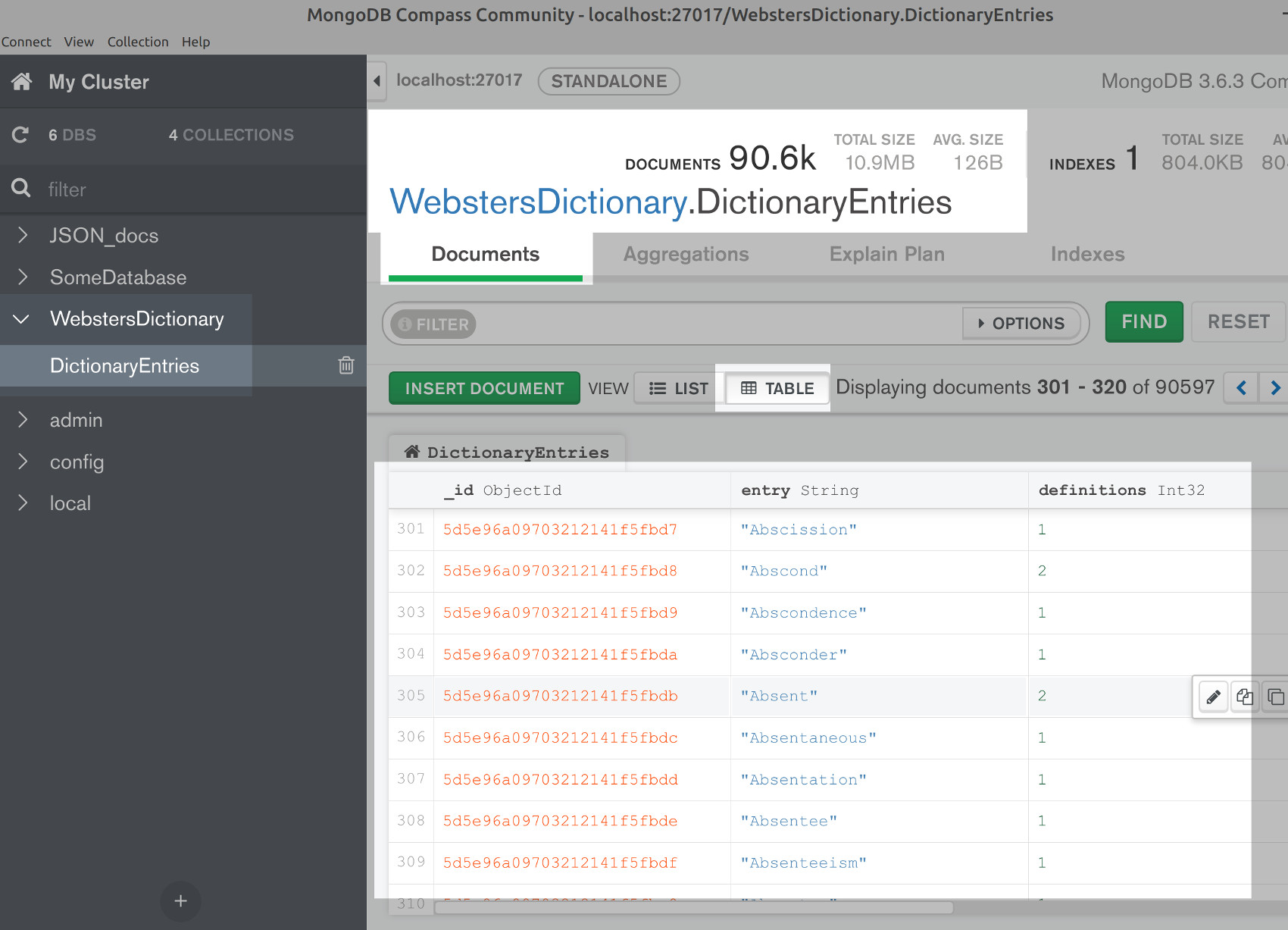
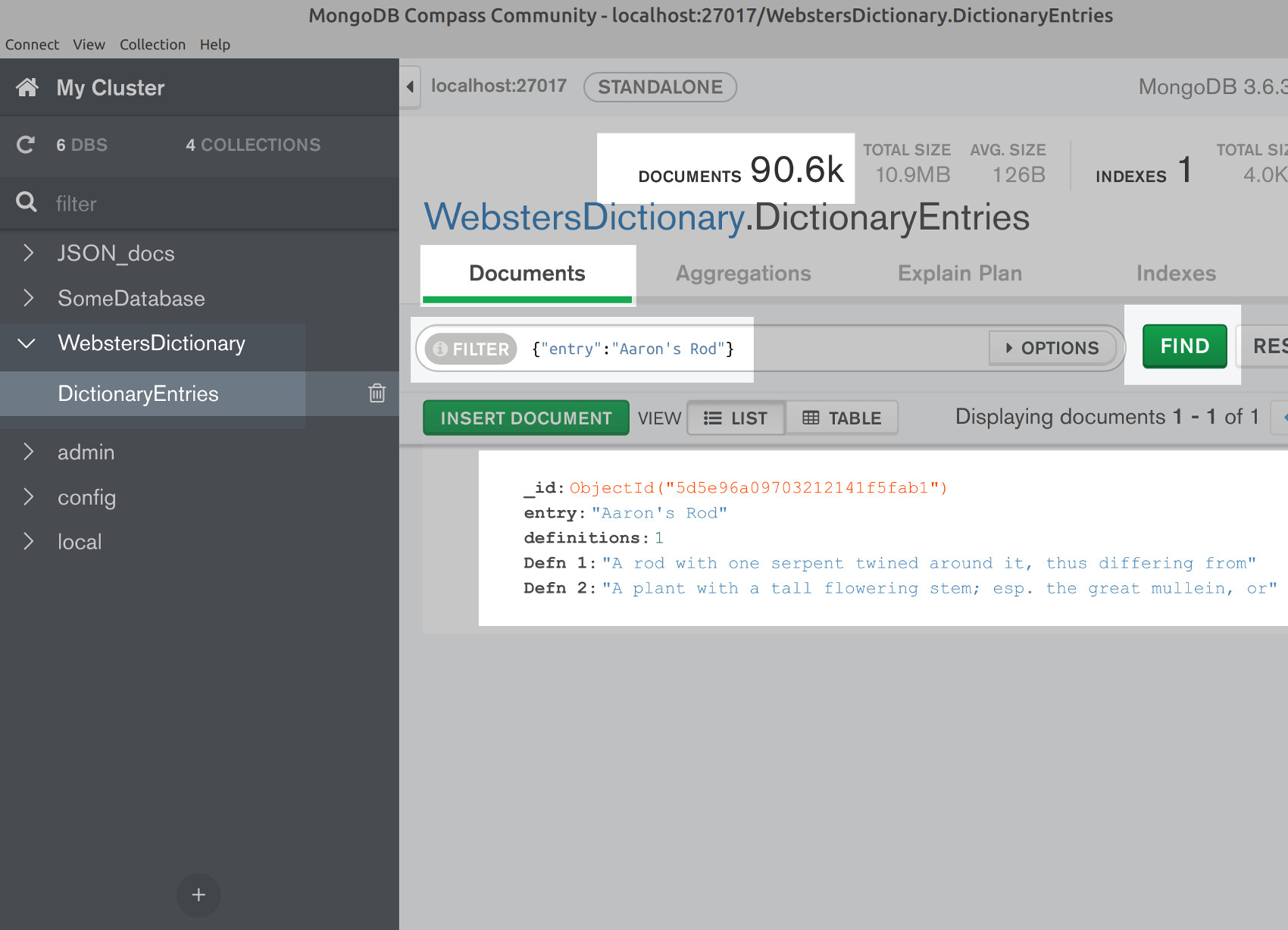
Use the MongoDB Compass GUI to filter the Webster dictionary entries
If you have the MongoDB Compass application installed you can use it to verify that the Webster’s dictionary entries have been inserted successfully. Just navigate to the WebstersDictionary database and then to the DictionaryEntries collection on the left-hand side, and there should be over 90k documents in it:
Create a MongoDB filter to find a dictionary entry
You can also use the Compass GUI to filter a dictionary entry. Here’s a filter example that gets the definition for “Aaron’s Rod”:
1 | {"entry":"Aaron's Rod"} |
Inserting or indexing Dictionary entries into a NoSQL database as documents is ideal for creating a mobile, web-based, or desktop dictionary application. With the instructions provided in this tutorial, you’ll be able to parse a line-by-line text file and insert MongoDB documents with Python to create your own dictionary application.
Just the Code
Throughout our tutorial, we looked at the example code one section at a time. Shown below is the complete Python script to parse a line-by-line text file and insert MongoDB documents based on the contents of the file:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 | #!/usr/bin/env python3 #-*- coding: utf-8 -*- # import the MongoClient class from pymongo import MongoClient, errors # import Python's pickle library to serialize the dictionary import pickle # import Python's time and JSON libraries import time, json # record the start time for the script start_time = time.time() # declare a function that parsed the Webster's text file def get_webster_entries(filename): # use the open() function to open the text file with open(filename, 'rb') as raw: data = raw.read() # decode the file as UTF-8 and ignore errors data = data.decode("utf-8", errors='ignore') # split the dictionary file into list by: "\r\n" data = data.split("\r\n") # create an empty Python dict for the entries dict_data = {} # iterate over the list of dictionary terms for num, line in enumerate(data): try: # entry titles in Webster's dict are uppercase if len(line) < 40 and line.isupper() == True: # new entry for the dictionary current = line.title() current = current.replace("'S", "'s") # MongoDB docs must not have "." current = current.replace(".", "") # append an empty dict object to the list for the entry if current not in dict_data: # reset the definition count def_count = 1 # new dictionary entry dict_data[current] = {"definitions": 1} else: # append to dict entry if needed def_count = dict_data[current]["definitions"] + 1 dict_data[current]["definitions"] = def_count # add a new definition by looking for "Defn" if "Defn:" in line: # concatenate strings for the definitions def_title = "Defn " + str(def_count) def_content = line.replace("Defn: ", "") # add the definition to the defn title key dict_data[current][def_title] = def_content # add to the definition count def_count += 1 # add definition by number and period elif "." in line[:2] and line[0].isdigit(): # concatenate strings for the definitions def_title = "Defn " + str(def_count) def_content = line = line[line.find(".")+2:] # make sure content for definition has some length if len(def_content) >= 10: # add the definition to the defn title key dict_data[current][def_title] = def_content # add to the definition count def_count += 1 except Exception as error: # errors while iterating with enumerate() print ("\nenumerate() text file ERROR:", error) print ("line number:", num) try: # update the number of definitions dict_data[current]["definitions"] = def_count-1 except UnboundLocalError: pass return dict_data # call the function and return Webster's dict as a Python dict dictionary = get_webster_entries("websters_dictionary.txt") # declare an empty list for the final MongoDB docs to be inserted final_list = [] # tally the # of entries that won't be inserted rem = 0 # iterate over the dictionary entries and definitions for entry, val in dictionary.items(): # only add to the list if it has a definition if val != {'definitions': 1}: # put the final dictionary entry into the list obj = {'entry': entry} # update the entry with definitions for the document obj.update(val) # add the dictionary object to the MongoDB list final_list += [ obj ] else: # tally the removed entries rem += 1 # uncomment the following to print the complete list of entries #print (final_list) # print the num of entries with empty definitions print ("# of entries removed:", rem) # declare a client instance of the MongoDB PyMongo driver client = MongoClient('localhost', 27017) try: # server_info() should raise exception if host settings are invalid print ("\nserver_info():", json.dumps(client.server_info(), indent=4)) # declare a database and collection instance from the client db = client["WebstersDictionary"] col = db["DictionaryEntries"] # make an API request to MongoDB to insert_many() fruits result = col.insert_many(final_list) # print the API response from the MongoDB server print ("\ninsert_many() result:", result) # get the total numbers of docs inserted total_docs = len(result.inserted_ids) # print the number of dictionary entries inserted print ("total entries inserted:", total_docs) except errors.ServerSelectionTimeoutError as err: # catch pymongo.errors.ServerSelectionTimeoutError print ("PyMongo ERROR:", err) # print the time that elapsed print ("Elapsed time (in seconds):", time.time() - start_time) # serialize the Python dictionary as a local pickle file with open("websters_mongodb.pickle","wb") as pickle_dict: pickle.dump(dictionary, pickle_dict) |


Pilot the ObjectRocket Platform Free!
Try Fully-Managed CockroachDB, Elasticsearch, MongoDB, PostgreSQL (Beta) or Redis.
Get Started