How to Use Python to Update API Elasticsearch Documents
Introduction
The Python client can be used to update existing documents on an Elasticsearch cluster. In order to perform any python updates API Elasticsearch you will need Python Versions 2 or 3 with its PIP package manager installed along with a good working knowledge of Python. Once you have the basics requisites you will be able to use python update Elasticsearch documentsx000D in single or multiple calls.
Prerequisites
You should possess a good working knowledge of Python and its syntax.
Python version 2 or 3, and its PIP package manager, must be installed. However, you are strongly encouraged to use Python 3 as Python Version 2 is now considered depreciated.
You must have the compatible Elasticsearch low-level client installed for the version of Python you plan to use. If you do not, you can use the PIP installer to set up the
Elasticsearchlibrary for Python as follows:
1 2 3 4 5 | # use 'pip3' for Python 3 pip3 install elasticsearch # use 'pip' for Python 2 pip install elasticsearch |
To avoid potential errors, the major version of Elasticsearch should be matched with the same major version of the Python low-level client. For example, if you have Elasticsearch v7.x installed should also have the low-level Python client version 7.x installed.
Use the following Python command in IDLE or a Python interpreter to obtain the client’s version:
1 2 | import elasticsearch print ('version:', elasticsearch.__version__[0]) |
- An Elasticsearch cluster, containing an index with some data, must be installed. The Elasticsearch service typically runs on port
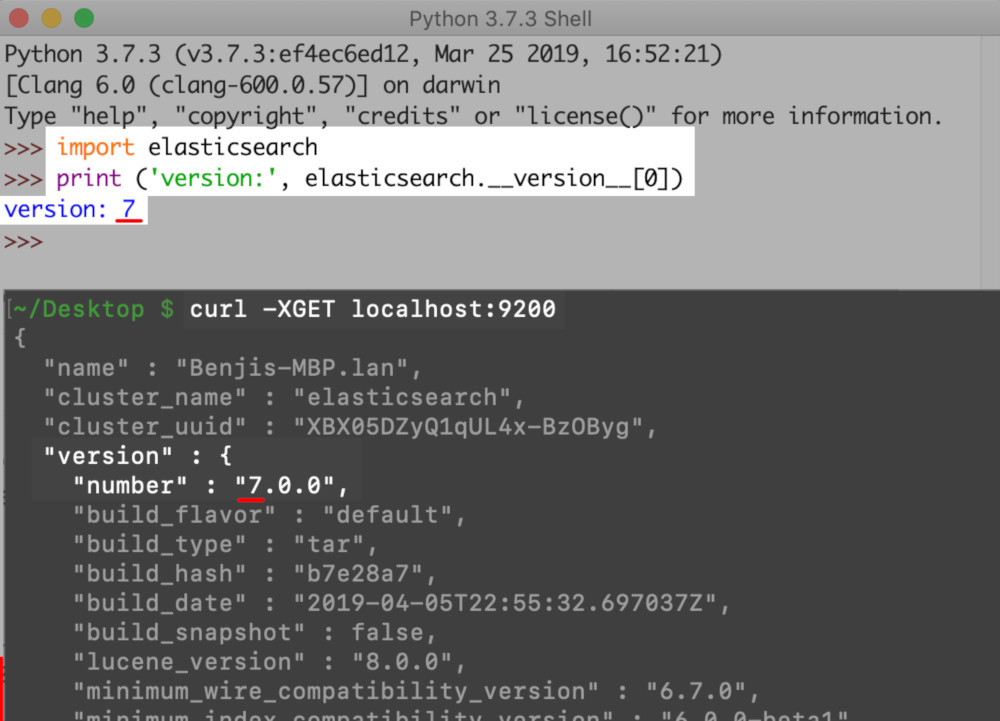
9200and you can confirm it is running by executing the following cURL request:curl -XGET localhost:9200
Obtain the version of the Elasticsearch cluster with a cURL request
Connecting to the Elasticsearch Cluster with a Client Instance
You should now be able to connect to the Elasticsearch cluster and make requests to the cluster in Python. However, if you haven’t already done so, you will first need to import the elasticsearch library as follows:
1 2 3 4 5 | #!/usr/bin/env python3 #-*- coding: utf-8 -*- from elasticsearch import Elasticsearch import time # for the index's ""timestamp"" field |
At this point you should save and run the script to confirm there were no import errors. If everything was properly imported, the script should not output anything to the terminal.
Edit the script again and try making a client instance of the library that will be used when connecting to the Elasticsearch cluster:
1 2 3 4 5 6 7 8 9 10 11 | # connect to the Elasticsearch cluster elastic = Elasticsearch() # or: Elasticsearch([{'host': 'localhost', 'port': 9200}]) ''' The 'hosts' parameter is optional: elastic = Elasticsearch(hosts=[""DOMAIN_NAME""]) Optional dictionary parameter to pass: {'host': ""SOME_DOMAIN"", 'port': 1234, 'url_prefix': 'en', 'use_ssl': True} ''' |
NOTE: You do not have to pass the hosts parameter array at this point in development. It will connect with most localhost web servers by just instantiating the class without parameters (Elasticsearch()), or by using the string localhost, as in the following example:
1 | Elasticsearch(hosts=[""localhost""]) |
GET the _Mapping of the Elasticsearch Document’s Index
- It is highly recommend you have Elasticsearch return a JSON response of the index’s
_mappingto more easily avoidmapper_parsingexceptions.
For Kibana and cURL you can use a simple GET request with no JSON body:
1 2 3 4 5 | # Kibana console request: GET some_index/_mapping # cURL request: curl -XGET localhost:9200/some_index/_mapping/?pretty |
Confirm that the Python dictionary object used to pass to the update() method matches the schema, or layout, of the index’s _mapping.
How to make a GET request with cURL to obtain the _mapping of an Elasticsearch index:
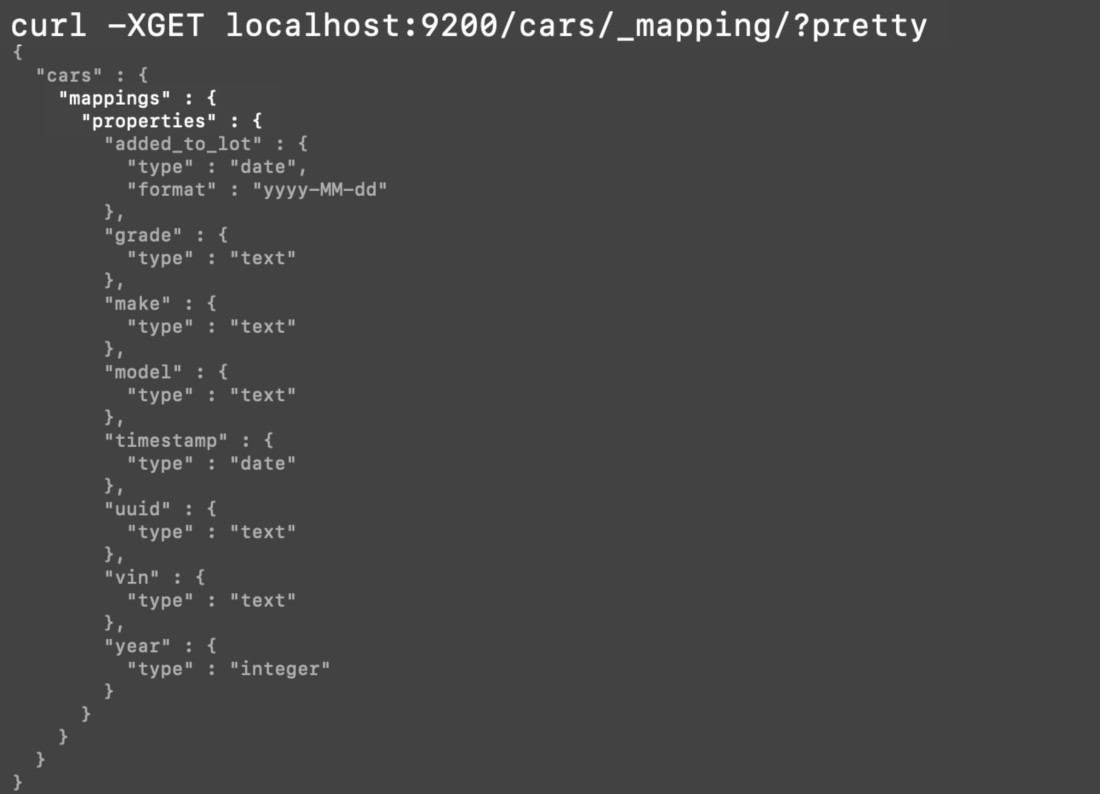
You can obtain the mapping of all indexes on the cluster using this GET request:
1 | curl -XGET 'http://localhost:9200/_mapping?pretty=true' |
Confim you have the correct Elasticsearch document ID
It is imperative you make certain you are updating the correct document for the correct index. You can make sure you have the correct files by making a GET request for the document and its index that you want to update using either Kibana or cURL in a terminal.
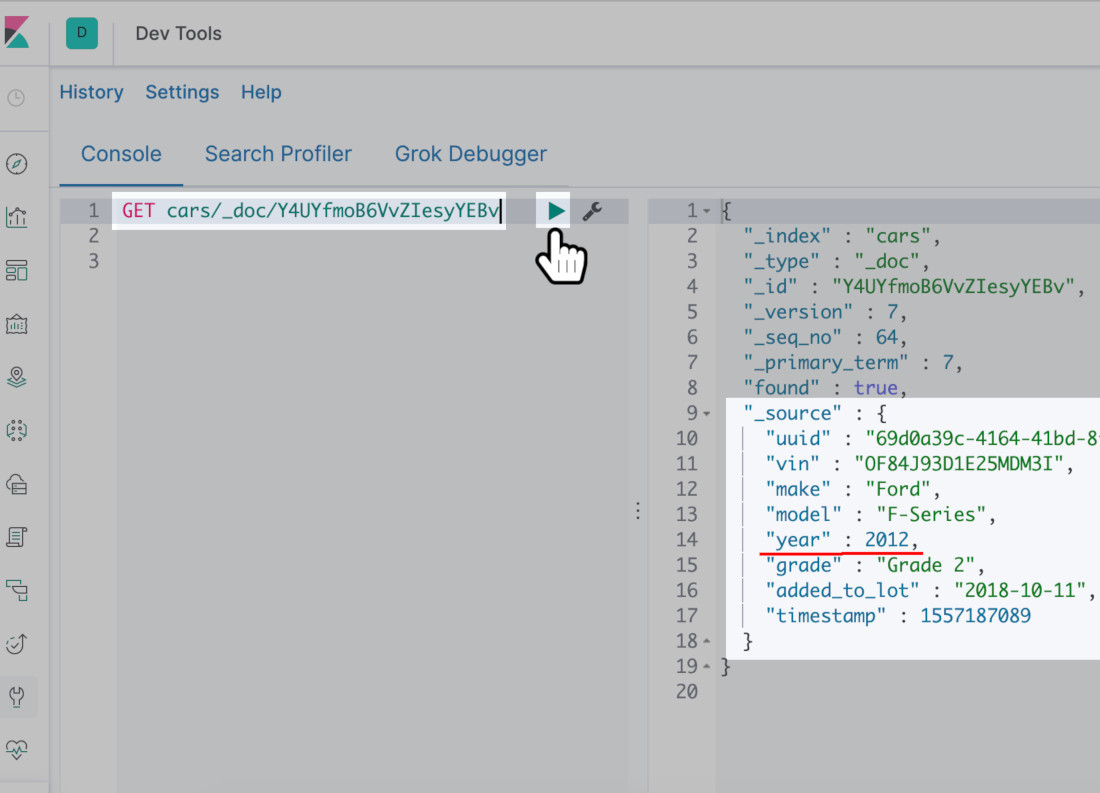
How to Create a Python Dictionary of the Updated Values to Pass to the Elasticsearch Update() Method
Let’s say an auto dealership has an Elasticsearch index for all the vehicles on its lot. The dealership needs to update a document for an older Ford truck that had the model year incorrectly indexed as 2012, instead of the actually production year of 2014.
Here you can use Python’s built-in time module to generate a time stamp of when the Update call took place by having the time.time() method return a float and then convert that float to an integer:
1 2 3 | # create a time stamp, in seconds, since epoch timestamp = int(time.time() print (""EPOCH:"", timestamp) |
Additionally, it was also discovered the vehicle’s condition was incorrectly entered as ""Grade 2"" when it should have be entered as ""Grade 3"".
Here is the command to create a Python dictionary that will represent all of the document’s fields that require updating:
1 2 3 4 5 6 7 8 | source_to_update = { # ""doc"" is essentially Elasticsearch's ""_source"" field ""doc"" : { ""year"" : 2014, ""grade"" : ""Grade 3"", ""timestamp"" : timestamp # integer of epoch time } } |
How to call the Elasticsearch client’s update() method to update an index’s document.
The structure of Python’s Update() method should, at the very minimum, include the index name, it’s document type (depreciated), the document ID and the content “”body”” that is being updated, as shown here:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | client.update( # name of index (string) index='my_index', # document type (string) doc_type=""some_doc_type"", # document ID (string or integer) id=12345, # Python dictionary representing document's '_source' # ""doc"" is the ""_source"" field body={ ""doc""{ ""field_to_update"" : ""updated data"" } } ) |
NOTE: As of April 2019, the Elasticsearch document type is being depreciated so you may have to pass ""_doc"" for the doc_type parameter, depending on what version of Elasticsearch you are using.
Take the source_to_update variable, that was declared earlier, and pass it into the update() method as the body parameter. Have the call return a response and store it as a Python variable called response as follows:
1 2 | response = elastic_client.update(index='cars', doc_type=""_doc"", id='Y4UYfmoB6VvZIesyYEBv', body=source_to_update) print ('response:', response) |
Use Kibana to verify the update() call in Python was successful:
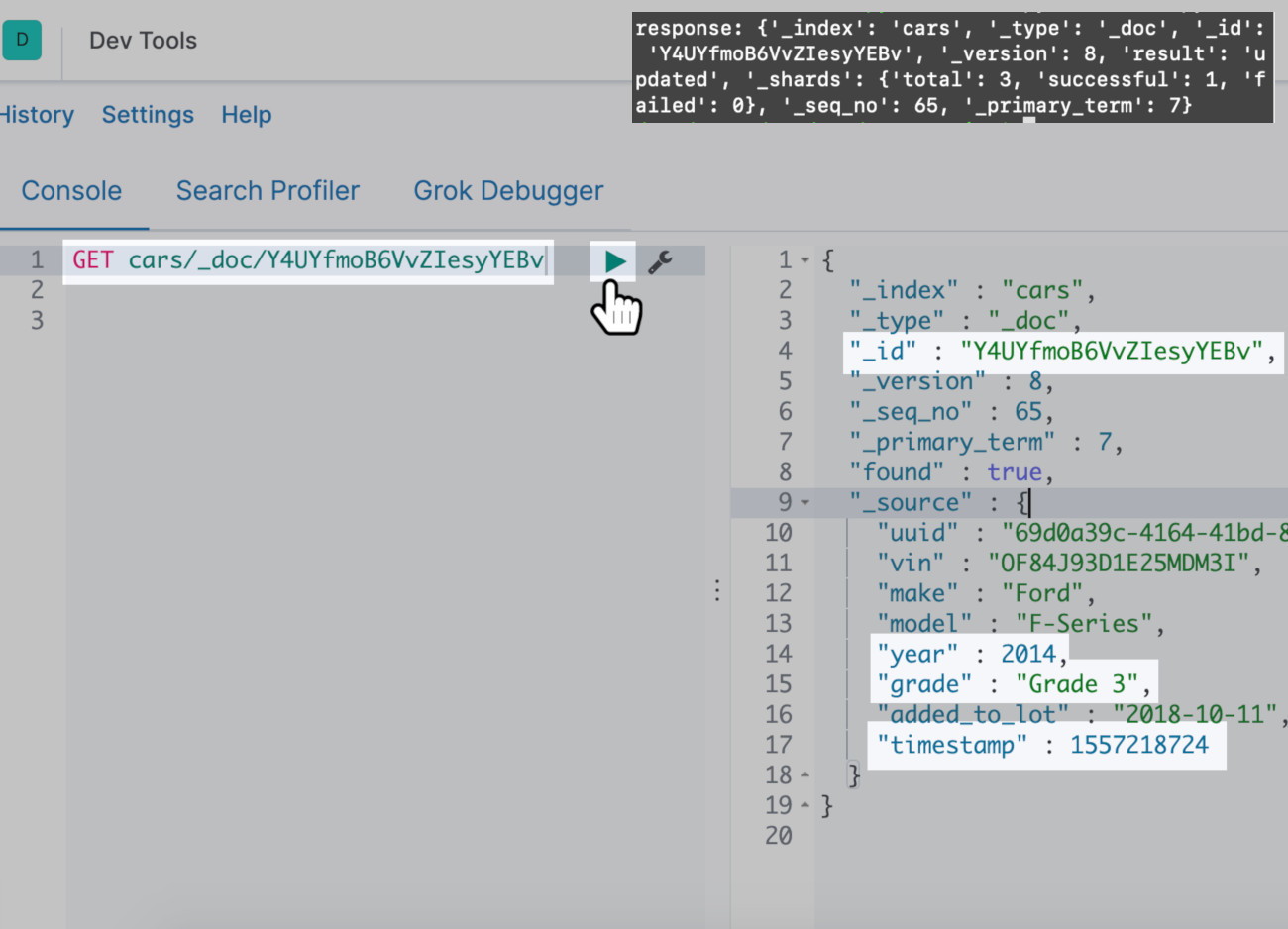
The truck’s year and “”grade”” should now be updated.
Print Out the Response of the Elasticsearch Update API Call
Execute a “”try and except”” block to catch errors and print out the API call’s response:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | # catch API errors try: # call the Update method response = elastic_client.update( index='cars', doc_type=""_doc"", id='Y4UYfmoB6VvZIesyYEBv', body=source_to_update ) # print the response to screen print (response, '\n\n') if response['result'] == ""updated"": print (""result:"", response['result']) print (""Update was a success for ID:"", response['_id']) print (""New data:"", source_to_update) else: print (""result:"", response['result']) print (""Response failed:"", response['_shards']['failed']) except Exception as err: print ('Elasticsearch API error:', err) |
This is what Python will print out to console:
1 2 3 4 5 6 | {'_index': 'cars', '_type': '_doc', '_id': 'Y4UYfmoB6VvZIesyYEBv', '_version': 9, 'result': 'updated', '_shards': {'total': 3, 'successful': 1, 'failed': 0}, '_seq_no': 66, '_primary_term': 7} result: updated Update was a success for ID: Y4UYfmoB6VvZIesyYEBv New data: {'doc': {'year': 2014, 'grade': 'Grade 3', 'timestamp': 1557220825}} |
How to Use a Python Iterator to Update More Than One Elasticsearch Document
The Elasticsearch Update API is designed to update only one document at a time. However, if you wanted to make more than one call, you can make a query to get more than one document, put all of the document IDs into a Python list and iterate over that list.
To accomplish this, you will first need to create a search query dictionary to obtain the documents. Make certain you enter a number in the ""size"" option to return more than the default 10 document “”hits”” by setting the number higher than the default, as shown here:
1 2 3 4 5 6 7 8 9 10 11 12 13 | # query all documents query_all = {""size"":300, ""query"": {""match_all"": {}}} # get a response using the Search API response = elastic_client.search(index=""cars"", body=query_all) all_documents = response['hits']['hits'] # put them all into an empty list documents = [] for num, doc in enumerate(all_documents): documents += [doc['_id']] print (""FOUND"", len(documents), ""documents:"") |
Now create a timestamp, and iterate over all of the Elasticsearch documents inside the documents list to update their ""timestamp"" fields:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 | # integer of seconds since epoch time timestamp = int(time.time()) # just update every document's 'timestamp' field source_to_update = { ""doc"" : { ""timestamp"" : timestamp } } # iterate over the list of documents for num, doc_id in enumerate(documents): # catch API errors try: # call the Update method response = elastic_client.update( index='cars', doc_type=""_doc"", id=doc_id, body=source_to_update ) # print the response to screen print (response, '\n\n') if response['result'] == ""updated"": print (""result:"", response['result']) print (""Update was a success for ID:"", response['_id']) print (""New data:"", source_to_update) else: print (""result:"", response['result']) print (""Response failed:"", response['_shards']['failed']) except Exception as err: print ('Elasticsearch Update API error:', err) |
Now all of the documents in the ""cars"" index have an updated ""timestamp"" field:
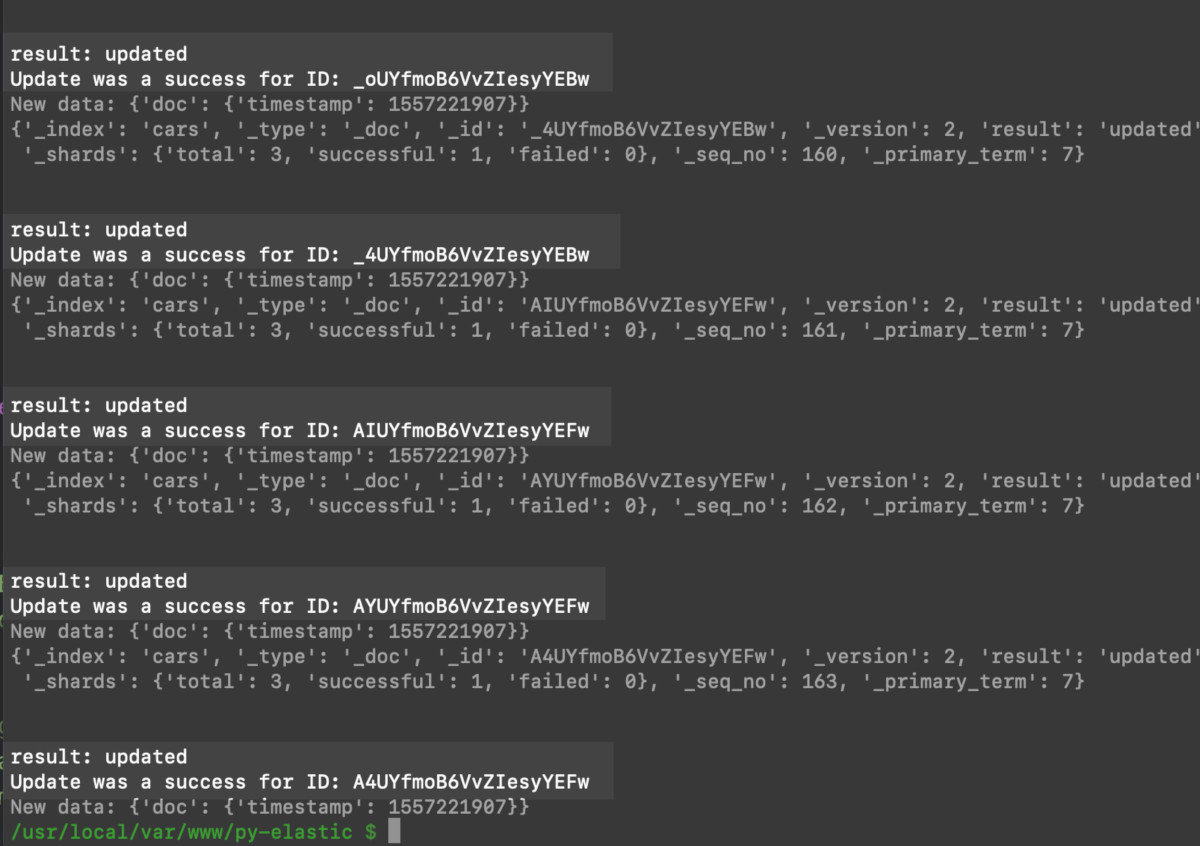
Conclusion
In this tutorial you learned how to update Elasticsearch documents using Python scripts. However, you will have trouble performing these types of updates if you do not possess a good working knowledge of Python. You must have Python and the corresponding version of its PIP package manager installed. However, as Python Version 2 is now considered depreciated, using Version 3 for Python updates API Elasticsearch cluster is strongly recommended. Remember, when using python to update Elasticsearch documents you must remember to confirm that the Python dictionary object you use to pass to the update method matches the schema of the index’s mapping. Additionally, always make certain you are updating the correct document for the correct index by making a GET request for the files you want to update using either Kibana or cURL.



Pilot the ObjectRocket Platform Free!
Try Fully-Managed CockroachDB, Elasticsearch, MongoDB, PostgreSQL (Beta) or Redis.
Get Started