SQL Rank
Introduction
PostgreSQL, the popular object-relational database management system (ORDBMS), has several powerful functions to assist application developers and DBAs in managing their data expeditiously. Among the most helpful functions in PostgreSQL is SQL RANK(). When you use it to query, you have the ability to separate the rows of the result response. Each row can be ranked in each partitioned group within the results set. It’s beneficial because you can obtain the data you need much faster and make insightful decisions based on the rows of ranked results.
This tutorial explains how to designate a rank to the rows within a query result using the RANK() function in PostgreSQL. Let’s get started.
Prerequisties
PostgreSQL – Install it and any dependencies required.
More about the SQL RANK() function
To gain a better understanding, let’s go over some basics about how the RANK() function works.
It is used to rank result rows.
The result rows are located in a partition.
The subclause PARTITION BY is how the groups are separated within the partition.
The number one rank belongs to the row at the top.
The number of rows that are tied together are added together, and that number is used as the designation number for the next row’s rank that isn’t tied. Therefore, it doesn’t work in a typical consecutive manner, if there are tied ranks. For example, if there are ties, row rankings may not reflect their actual designated rows like “1, 2, 3,” and so on. The examples shown in this tutorial will clarify how to read the results.
Ranked rows can have equal rankings.
Rows of equal rank will have comparable ranks for easier identification.
An example of the function ‘RANK()’ syntax
- Here’s an example of a syntax SQL RANK() function in a script:
1 2 3 4 | RANK() OVER ( [PARTITION BY prt_expression, ... ] ORDER BY srt_expression [ASC | DESC], ... ) |
Let’s review the details of the example shown above.
The set of results are divided using the PARTITION BY subclause.
Next, the rows are separated with the ORDER BY subclause.
Examples of how the function RANK() works with tables
Make a simple table. Call it “grades.”
Add the subject “VARCHAR.”
Assign points to the column for points as shown below.
1 2 3 4 | CREATE TABLE grades ( subject VARCHAR(10), points NUMERIC (5, 2) ); |
- Use
INSERT INTOto add some records to the new table you just created:
1 2 3 4 5 6 7 8 9 10 11 12 | INSERT INTO grades (subject, points) VALUES ('Math',97.50), ('History',40.40), ('Math',80.50), ('History',60.40), ('HRM',30.50), ('History',95.40), ('HRM',63.50), ('History',88.40), ('GEOLOGY',95.50), ('GEOLOGY',28.40); |
- Run a query:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | articles=# SELECT * FROM grades; subject | points ---------+-------- Math | 70.50 History | 50.40 Math | 70.50 History | 50.40 Math | 70.50 History | 50.40 HRM | 65.50 History | 50.40 HRM | 65.50 History | 50.40 GEOLOGY | 45.50 GEOLOGY | 50.40 (12 ROWS) |
Designate ranks for the rows of the sample table
- Use the function SQL RANK() to allocate the rows by ranking in the sample table you created like this:
1 2 3 4 | SELECT subject, points, RANK () OVER ( ORDER BY points) points_ranks FROM grades; |
- Your results should look similar to this:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | articles-# grades subject | points | points_ranks ---------+--------+-------------- GEOLOGY | 45.50 | 1 History | 50.40 | GEOLOGY | 50.40 | 2 History | 50.40 | 2 History | 50.40 | 2 History | 50.40 | 2 History | 50.40 | 2 HRM | 65.50 | 8 HRM | 65.50 | 8 Math | 70.50 | 10 Math | 70.50 | 10 Math | 70.50 | 10 (12 ROWS) |
Explanations of the details of the ranking example
Although 12 rows are ranked, due to ties, the rankings range from a row with the lowest rank of “1” to the highest rank of “10.” For example, focus on the 10th, 11th, and 12th rows. They each have a rank of “10” because they are tied for 10th place.
GEOLOGY ranks first.
History ranks second.
The subsequent rows with the same point value of “2” are ranked the same because they are tied for 2nd place ranking.
The two rankings of rows named HRM are in 8th and 9th place; however both of their rankings are “8” because they are indeed tied for the 8th place ranking.
Another PARTITION BY subclause example to consider
- Here’s a different example illustrating the subclause PARTITION BY to rank a result set:
1 2 3 4 5 6 7 8 9 10 | SELECT grade_id, subject, points, RANK () OVER ( PARTITION BY subject ORDER BY points ASC ) grade_ranks FROM grades; |
- Below is an example of what the output of the result set should resemble:
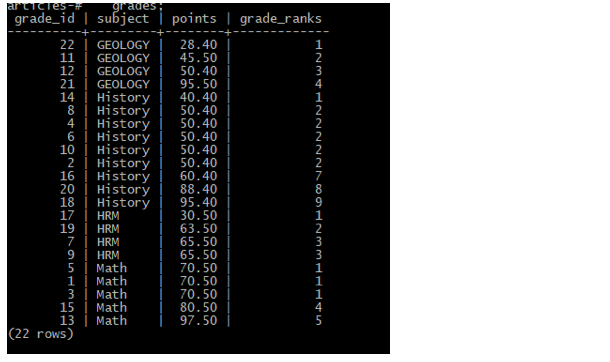
- The row-ranking order of the divided partitions is based on the subject column. Next, the point values rankings in the specific subject columns are ranked from the lowest point values to the highest point values.
>NOTE: Notice that some rows have tied rankings. The total of rows per subject column may not reflect the number of rows within a partition when there are ties.
>To explain further, in the above sample, take HRM, for instance. There are four rows, yet for each of the last two HRM rows there is a ranking of “3.” This is because they are tied for 3rd place within the HRM subject column.
Conclusion
In this tutorial, you learned how to utilize the PostgreSQL function SQL RANK() so that you can make analytical decisions based on rank. The function allows you to partition results data in order based on the criteria you set, for example, column type and point values. Use the RANK() function regularly and uncover your important data upfront.

Pilot the ObjectRocket Platform Free!
Try Fully-Managed CockroachDB, Elasticsearch, MongoDB, PostgreSQL (Beta) or Redis.
Get Started